 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASAP-FE: Energy-Efficient Feature Extraction Enabling Multi-Channel Keyword Spotting on Edge Processors
Jun 17, 2025Multi-channel keyword spotting (KWS) has become crucial for voice-based applications in edge environments. However, its substantial computational and energy requirements pose significant challenges. We introduce ASAP-FE (Agile Sparsity-Aware Parallelized-Feature Extractor), a hardware-oriented front-end designed to address these challenges. Our framework incorporates three key innovations: (1) Half-overlapped Infinite Impulse Response (IIR) Framing: This reduces redundant data by approximately 25% while maintaining essential phoneme transition cues. (2) Sparsity-aware Data Reduction: We exploit frame-level sparsity to achieve an additional 50% data reduction by combining frame skipping with stride-based filtering. (3) Dynamic Parallel Processing: We introduce a parameterizable filter cluster and a priority-based scheduling algorithm that allows parallel execution of IIR filtering tasks, reducing latency and optimizing energy efficiency. ASAP-FE is implemented with various filter cluster sizes on edge processors, with functionality verified on FPGA prototypes and designs synthesized at 45 nm. Experimental results using TC-ResNet8, DS-CNN, and KWT-1 demonstrate that ASAP-FE reduces the average workload by 62.73% while supporting real-time processing for up to 32 channels. Compared to a conventional fully overlapped baseline, ASAP-FE achieves less than a 1% accuracy drop (e.g., 96.22% vs. 97.13% for DS-CNN), which is well within acceptable limits for edge AI. By adjusting the number of filter modules, our design optimizes the trade-off between performance and energy, with 15 parallel filters providing optimal performance for up to 25 channels. Overall, ASAP-FE offers a practical and efficient solution for multi-channel KWS on energy-constrained edge devices.
KFinEval-Pilot: A Comprehensive Benchmark Suite for Korean Financial Language Understanding
Apr 17, 2025We introduce KFinEval-Pilot, a benchmark suite specifically designed to evaluate large language models (LLMs) in the Korean financial domain. Addressing the limitations of existing English-centric benchmarks, KFinEval-Pilot comprises over 1,000 curated questions across three critical areas: financial knowledge, legal reasoning, and financial toxicity. The benchmark is constructed through a semi-automated pipeline that combines GPT-4-generated prompts with expert validation to ensure domain relevance and factual accuracy. We evaluate a range of representative LLMs and observe notable performance differences across models, with trade-offs between task accuracy and output safety across different model families. These results highlight persistent challenges in applying LLMs to high-stakes financial applications, particularly in reasoning and safety. Grounded in real-world financial use cases and aligned with the Korean regulatory and linguistic context, KFinEval-Pilot serves as an early diagnostic tool for developing safer and more reliable financial AI systems.
Network-based Topic Structure Visualization
Jan 31, 2024In the real world, many topics are inter-correlated, making it challenging to investigate their structure and relationships. Understanding the interplay between topics and their relevance can provide valuable insights for researchers, guiding their studies and informing the direction of research. In this paper, we utilize the topic-words distribution, obtained from topic models, as item-response data to model the structure of topics using a latent space item response model. By estimating the latent positions of topics based on their distances toward words, we can capture the underlying topic structure and reveal their relationships. Visualizing the latent positions of topics in Euclidean space allows for an intuitive understanding of their proximity and associations. We interpret relationships among topics by characterizing each topic based on representative words selected using a newly proposed scoring scheme. Additionally, we assess the maturity of topics by tracking their latent positions using different word sets, providing insights into the robustness of topics. To demonstrate the effectiveness of our approach, we analyze the topic composition of COVID-19 studies during the early stage of its emergence using biomedical literature in the PubMed database. The software and data used in this paper are publicly available at https://github.com/jeon9677/gViz .
Graph-based Trajectory Visualization for Text Mining of COVID-19 Biomedical Literature
Jun 07, 2021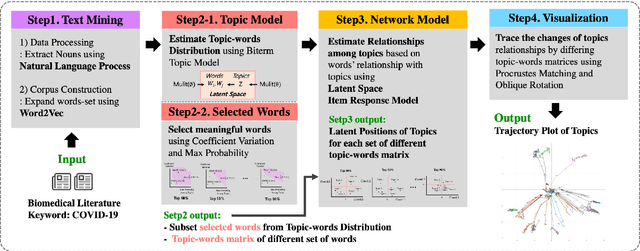


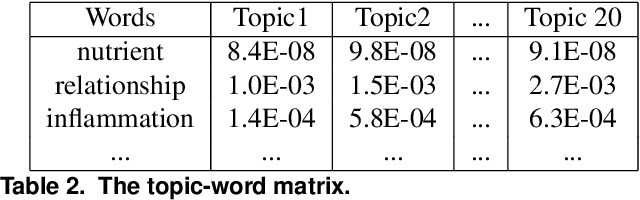
Since the emergence of the worldwide pandemic of COVID-19, relevant research has been published at a dazzling pace, which makes it hard to follow the research in this area without dedicated efforts. It is practically impossible to implement this task manually due to the high volume of the relevant literature. Text mining has been considered to be a powerful approach to address this challenge, especially the topic modeling, a well-known unsupervised method that aims to reveal latent topics from the literature. However, in spite of its potential utility, the results generated from this approach are often investigated manually. Hence, its application to the COVID-19 literature is not straightforward and expert knowledge is needed to make meaningful interpretations. In order to address these challenges, we propose a novel analytical framework for effective visualization and mining of topic modeling results. Here we assumed that topics constituting a paper can be positioned on an interaction map, which belongs to a high-dimensional Euclidean space. Based on this assumption, after summarizing topics with their topic-word distributions using the biterm topic model, we mapped these latent topics on networks to visualize relationships among the topics. Moreover, in the proposed approach, the change of relationships among topics can be traced using a trajectory plot generated with different levels of word richness. These results together provide a deeply mined and intuitive representation of relationships among topics related to a specific research area. The application of this proposed framework to the PubMed literature shows that our approach facilitates understanding of the topics constituting the COVID-19 knowledge.