 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Deceiving computers in Reverse Turing Test through Deep Learning
Jun 01, 2020
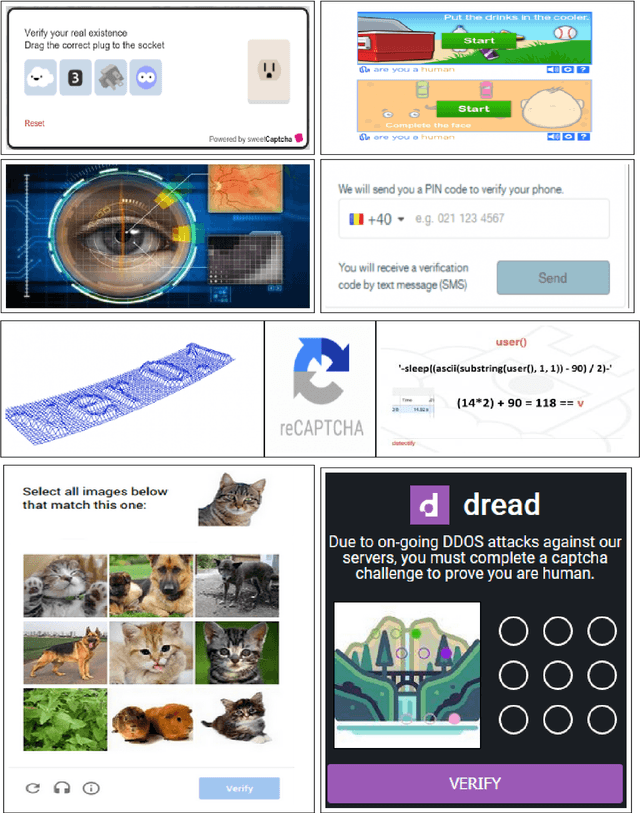

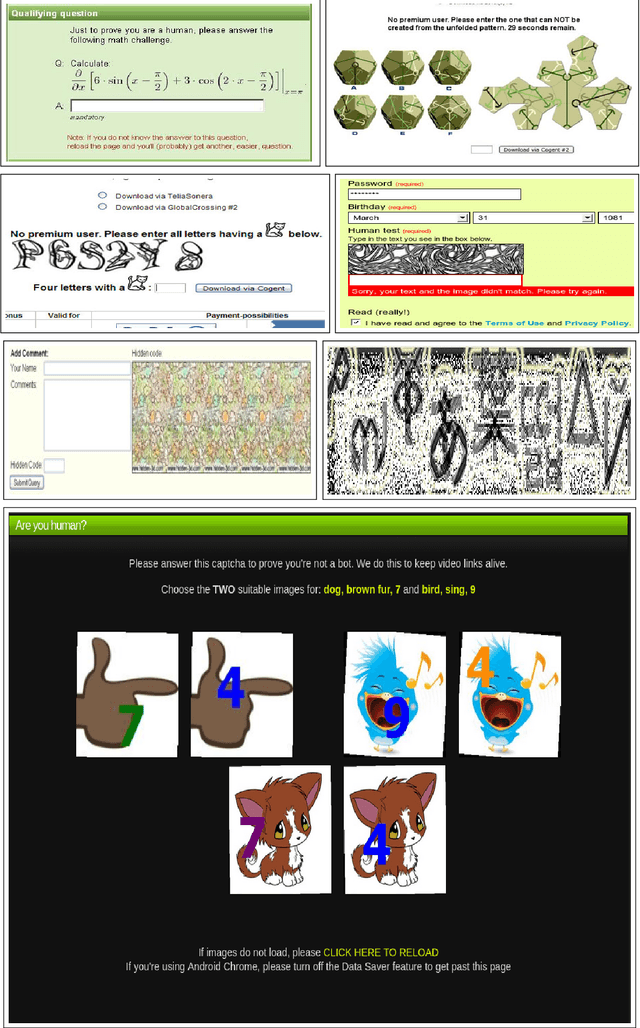
It is increasingly becoming difficult for human beings to work on their day to day life without going through the process of reverse Turing test, where the Computers tests the users to be humans or not. Almost every website and service providers today have the process of checking whether their website is being crawled or not by automated bots which could extract valuable information from their site. In the process the bots are getting more intelligent by the use of Deep Learning techniques to decipher those tests and gain unwanted automated access to data while create nuisance by posting spam. Humans spend a considerable amount of time almost every day when trying to decipher CAPTCHAs. The aim of this investigation is to check whether the use of a subset of commonly used CAPTCHAs, known as the text CAPTCHA is a reliable process for verifying their human customers. We mainly focused on the preprocessing step for every CAPTCHA which converts them in binary intensity and removes the confusion as much as possible and developed various models to correctly label as many CAPTCHAs as possible. We also suggested some ways to improve the process of verifying the humans which makes it easy for humans to solve the existing CAPTCHAs and difficult for bots to do the same.
A Deeper Look into Hybrid Images
Feb 10, 2020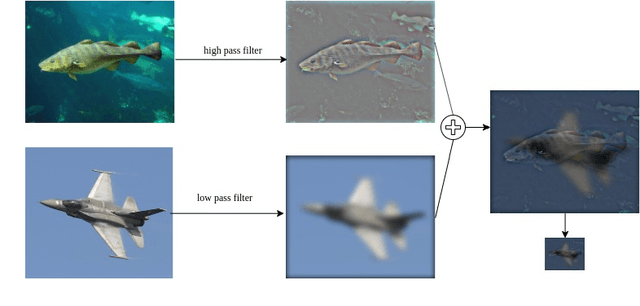

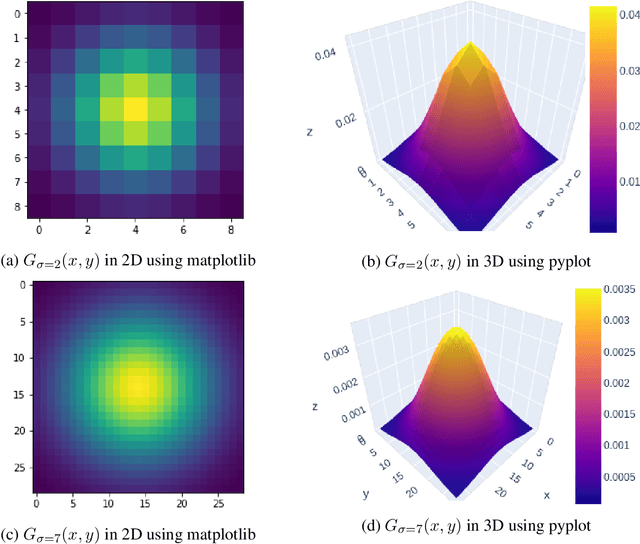

$Hybrid$ $images$ was first introduced by Olivia et al., that produced static images with two interpretations such that the images changes as a function of viewing distance. Hybrid images are built by studying human processing of multiscale images and are motivated by masking studies in visual perception. The first introduction of hybrid images showed that two images can be blend together with a high pass filter and a low pass filter in such a way that when the blended image is viewed from a distance, the high pass filter fades away and the low pass filter becomes prominent. Our main aim here is to study and review the original paper by changing and tweaking certain parameters to see how they affect the quality of the blended image produced. We have used exhaustively different set of images and filters to see how they function and whether this can be used in a real time system or not.