 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Graph Matching Algorithms for Integrating Multiple Data Sources
Feb 03, 2014
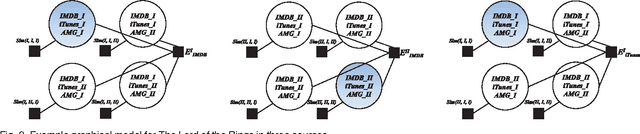

This paper explores combinatorial optimization for problems of max-weight graph matching on multi-partite graphs, which arise in integrating multiple data sources. Entity resolution-the data integration problem of performing noisy joins on structured data-typically proceeds by first hashing each record into zero or more blocks, scoring pairs of records that are co-blocked for similarity, and then matching pairs of sufficient similarity. In the most common case of matching two sources, it is often desirable for the final matching to be one-to-one (a record may be matched with at most one other); members of the database and statistical record linkage communities accomplish such matchings in the final stage by weighted bipartite graph matching on similarity scores. Such matchings are intuitively appealing: they leverage a natural global property of many real-world entity stores-that of being nearly deduped-and are known to provide significant improvements to precision and recall. Unfortunately unlike the bipartite case, exact max-weight matching on multi-partite graphs is known to be NP-hard. Our two-fold algorithmic contributions approximate multi-partite max-weight matching: our first algorithm borrows optimization techniques common to Bayesian probabilistic inference; our second is a greedy approximation algorithm. In addition to a theoretical guarantee on the latter, we present comparisons on a real-world ER problem from Bing significantly larger than typically found in the literature, publication data, and on a series of synthetic problems. Our results quantify significant improvements due to exploiting multiple sources, which are made possible by global one-to-one constraints linking otherwise independent matching sub-problems. We also discover that our algorithms are complementary: one being much more robust under noise, and the other being simple to implement and very fast to run.
Scaling Multiple-Source Entity Resolution using Statistically Efficient Transfer Learning
Aug 09, 2012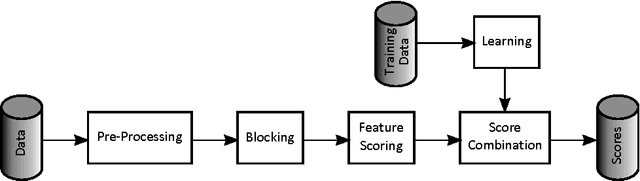
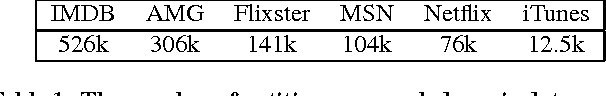
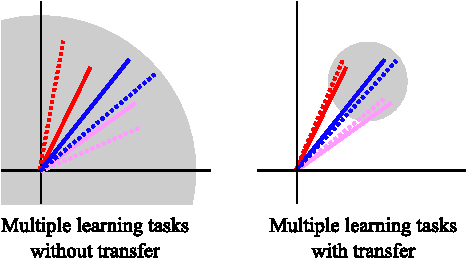
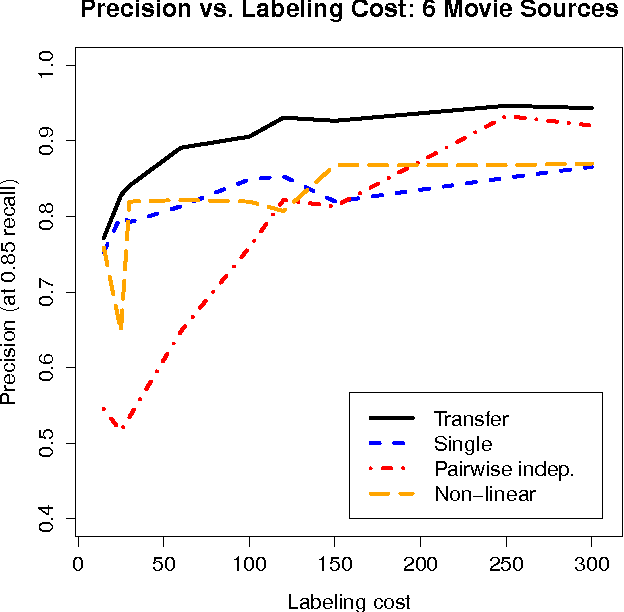
We consider a serious, previously-unexplored challenge facing almost all approaches to scaling up entity resolution (ER) to multiple data sources: the prohibitive cost of labeling training data for supervised learning of similarity scores for each pair of sources. While there exists a rich literature describing almost all aspects of pairwise ER, this new challenge is arising now due to the unprecedented ability to acquire and store data from online sources, features driven by ER such as enriched search verticals, and the uniqueness of noisy and missing data characteristics for each source. We show on real-world and synthetic data that for state-of-the-art techniques, the reality of heterogeneous sources means that the number of labeled training data must scale quadratically in the number of sources, just to maintain constant precision/recall. We address this challenge with a brand new transfer learning algorithm which requires far less training data (or equivalently, achieves superior accuracy with the same data) and is trained using fast convex optimization. The intuition behind our approach is to adaptively share structure learned about one scoring problem with all other scoring problems sharing a data source in common. We demonstrate that our theoretically motivated approach incurs no runtime cost while it can maintain constant precision/recall with the cost of labeling increasing only linearly with the number of sources.
A Bayesian Approach to Discovering Truth from Conflicting Sources for Data Integration
Mar 01, 2012
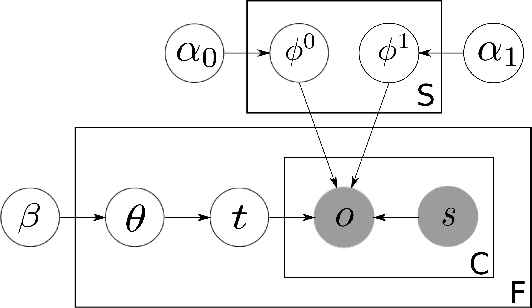
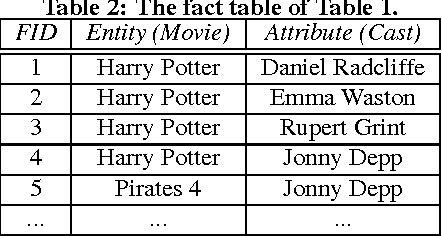
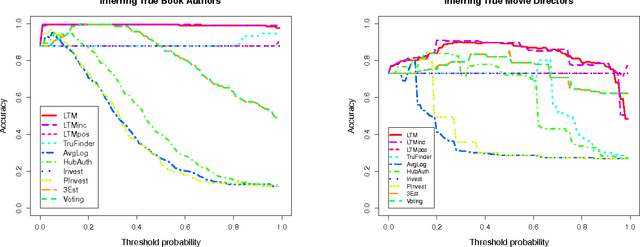
In practical data integration systems, it is common for the data sources being integrated to provide conflicting information about the same entity. Consequently, a major challenge for data integration is to derive the most complete and accurate integrated records from diverse and sometimes conflicting sources. We term this challenge the truth finding problem. We observe that some sources are generally more reliable than others, and therefore a good model of source quality is the key to solving the truth finding problem. In this work, we propose a probabilistic graphical model that can automatically infer true records and source quality without any supervision. In contrast to previous methods, our principled approach leverages a generative process of two types of errors (false positive and false negative) by modeling two different aspects of source quality. In so doing, ours is also the first approach designed to merge multi-valued attribute types. Our method is scalable, due to an efficient sampling-based inference algorithm that needs very few iterations in practice and enjoys linear time complexity, with an even faster incremental variant. Experiments on two real world datasets show that our new method outperforms existing state-of-the-art approaches to the truth finding problem.
* VLDB2012