 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Descriptive Patterns and their Application to Characterizing Classification Errors
Oct 18, 2021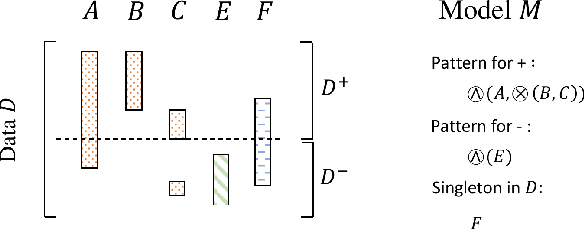

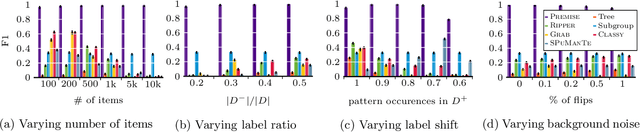

State-of-the-art deep learning methods achieve human-like performance on many tasks, but make errors nevertheless. Characterizing these errors in easily interpretable terms gives insight into whether a model is prone to making systematic errors, but also gives a way to act and improve the model. In this paper we propose a method that allows us to do so for arbitrary classifiers by mining a small set of patterns that together succinctly describe the input data that is partitioned according to correctness of prediction. We show this is an instance of the more general label description problem, which we formulate in terms of the Minimum Description Length principle. To discover good pattern sets we propose the efficient and hyperparameter-free Premise algorithm, which through an extensive set of experiments we show on both synthetic and real-world data performs very well in practice; unlike existing solutions it ably recovers ground truth patterns, even on highly imbalanced data over many unique items, or where patterns are only weakly associated to labels. Through two real-world case studies we confirm that Premise gives clear and actionable insight into the systematic errors made by modern NLP classifiers.
Graph Similarity Description: How Are These Graphs Similar?
May 29, 2021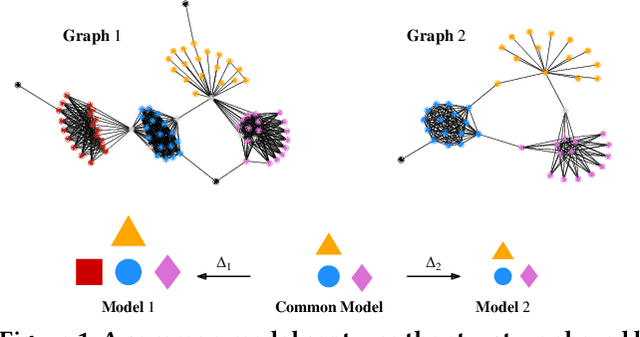
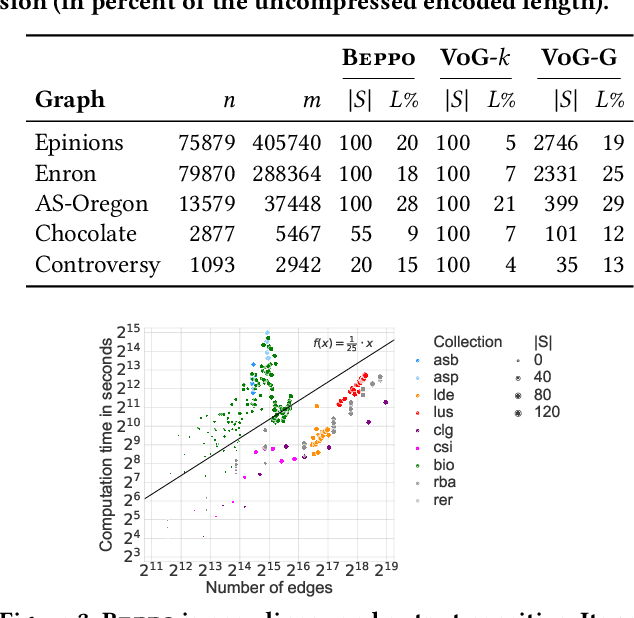
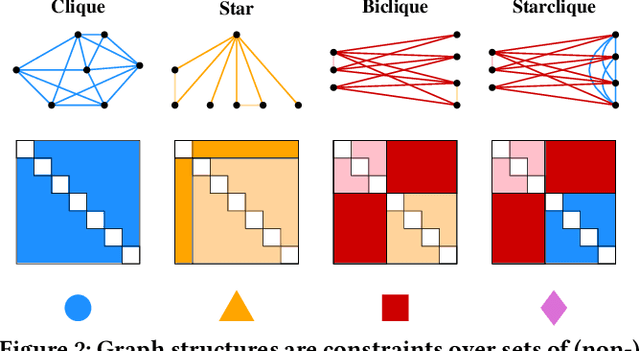

How do social networks differ across platforms? How do information networks change over time? Answering questions like these requires us to compare two or more graphs. This task is commonly treated as a measurement problem, but numerical answers give limited insight. Here, we argue that if the goal is to gain understanding, we should treat graph similarity assessment as a description problem instead. We formalize this problem as a model selection task using the Minimum Description Length principle, capturing the similarity of the input graphs in a common model and the differences between them in transformations to individual models. To discover good models, we propose Momo, which breaks the problem into two parts and introduces efficient algorithms for each. Through an extensive set of experiments on a wide range of synthetic and real-world graphs, we confirm that Momo works well in practice.
Factoring out prior knowledge from low-dimensional embeddings
Mar 02, 2021

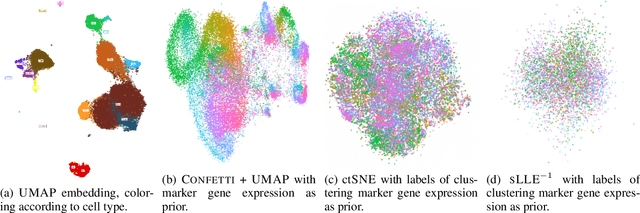

Low-dimensional embedding techniques such as tSNE and UMAP allow visualizing high-dimensional data and therewith facilitate the discovery of interesting structure. Although they are widely used, they visualize data as is, rather than in light of the background knowledge we have about the data. What we already know, however, strongly determines what is novel and hence interesting. In this paper we propose two methods for factoring out prior knowledge in the form of distance matrices from low-dimensional embeddings. To factor out prior knowledge from tSNE embeddings, we propose JEDI that adapts the tSNE objective in a principled way using Jensen-Shannon divergence. To factor out prior knowledge from any downstream embedding approach, we propose CONFETTI, in which we directly operate on the input distance matrices. Extensive experiments on both synthetic and real world data show that both methods work well, providing embeddings that exhibit meaningful structure that would otherwise remain hidden.
Discovering Reliable Causal Rules
Sep 08, 2020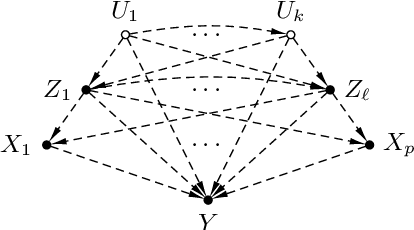
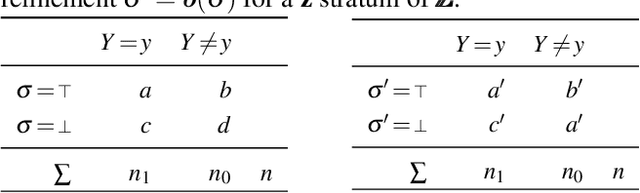
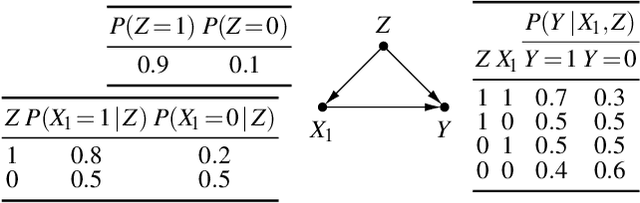

We study the problem of deriving policies, or rules, that when enacted on a complex system, cause a desired outcome. Absent the ability to perform controlled experiments, such rules have to be inferred from past observations of the system's behaviour. This is a challenging problem for two reasons: First, observational effects are often unrepresentative of the underlying causal effect because they are skewed by the presence of confounding factors. Second, naive empirical estimations of a rule's effect have a high variance, and, hence, their maximisation can lead to random results. To address these issues, first we measure the causal effect of a rule from observational data---adjusting for the effect of potential confounders. Importantly, we provide a graphical criteria under which causal rule discovery is possible. Moreover, to discover reliable causal rules from a sample, we propose a conservative and consistent estimator of the causal effect, and derive an efficient and exact algorithm that maximises the estimator. On synthetic data, the proposed estimator converges faster to the ground truth than the naive estimator and recovers relevant causal rules even at small sample sizes. Extensive experiments on a variety of real-world datasets show that the proposed algorithm is efficient and discovers meaningful rules.
What is Normal, What is Strange, and What is Missing in a Knowledge Graph: Unified Characterization via Inductive Summarization
Mar 23, 2020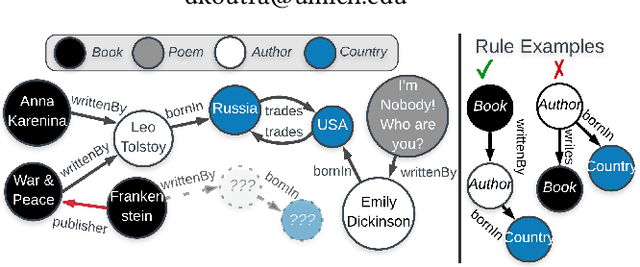


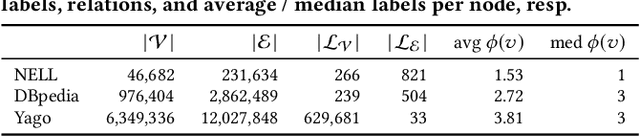
Knowledge graphs (KGs) store highly heterogeneous information about the world in the structure of a graph, and are useful for tasks such as question answering and reasoning. However, they often contain errors and are missing information. Vibrant research in KG refinement has worked to resolve these issues, tailoring techniques to either detect specific types of errors or complete a KG. In this work, we introduce a unified solution to KG characterization by formulating the problem as unsupervised KG summarization with a set of inductive, soft rules, which describe what is normal in a KG, and thus can be used to identify what is abnormal, whether it be strange or missing. Unlike first-order logic rules, our rules are labeled, rooted graphs, i.e., patterns that describe the expected neighborhood around a (seen or unseen) node, based on its type, and information in the KG. Stepping away from the traditional support/confidence-based rule mining techniques, we propose KGist, Knowledge Graph Inductive SummarizaTion, which learns a summary of inductive rules that best compress the KG according to the Minimum Description Length principle---a formulation that we are the first to use in the context of KG rule mining. We apply our rules to three large KGs (NELL, DBpedia, and Yago), and tasks such as compression, various types of error detection, and identification of incomplete information. We show that KGist outperforms task-specific, supervised and unsupervised baselines in error detection and incompleteness identification, (identifying the location of up to 93% of missing entities---over 10% more than baselines), while also being efficient for large knowledge graphs.
Discovering Reliable Correlations in Categorical Data
Aug 30, 2019
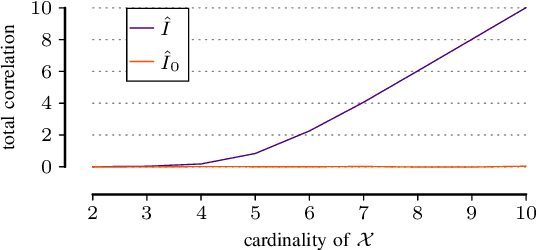
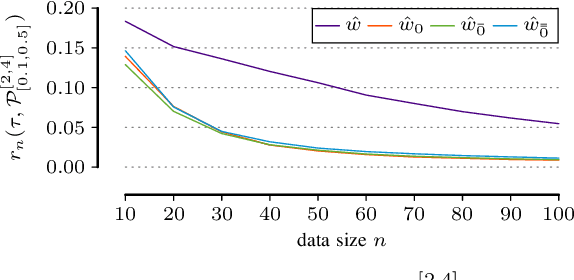

In many scientific tasks we are interested in discovering whether there exist any correlations in our data. This raises many questions, such as how to reliably and interpretably measure correlation between a multivariate set of attributes, how to do so without having to make assumptions on distribution of the data or the type of correlation, and, how to efficiently discover the top-most reliably correlated attribute sets from data. In this paper we answer these questions for discovery tasks in categorical data. In particular, we propose a corrected-for-chance, consistent, and efficient estimator for normalized total correlation, by which we obtain a reliable, naturally interpretable, non-parametric measure for correlation over multivariate sets. For the discovery of the top-k correlated sets, we derive an effective algorithmic framework based on a tight bounding function. This framework offers exact, approximate, and heuristic search. Empirical evaluation shows that already for small sample sizes the estimator leads to low-regret optimization outcomes, while the algorithms are shown to be highly effective for both large and high-dimensional data. Through two case studies we confirm that our discovery framework identifies interesting and meaningful correlations.
Summarizing Data Succinctly with the Most Informative Itemsets
Apr 27, 2019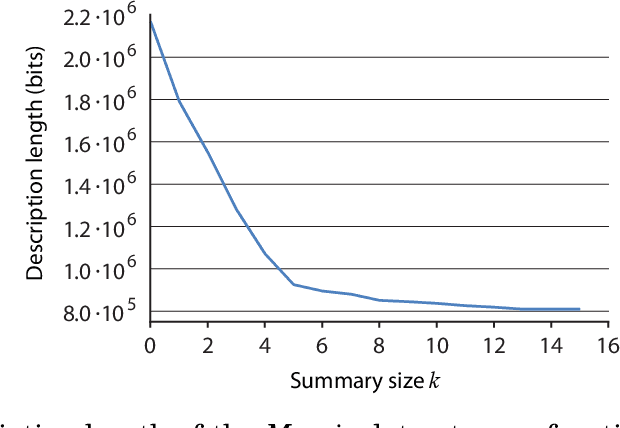
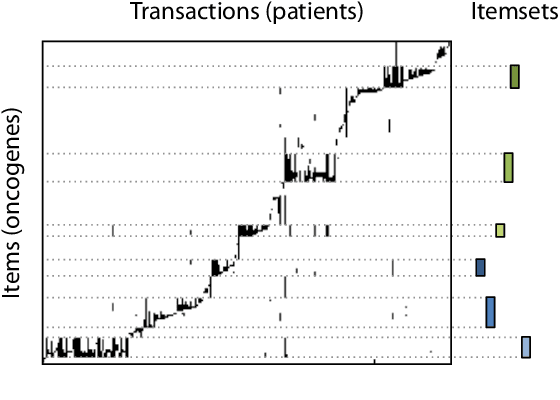
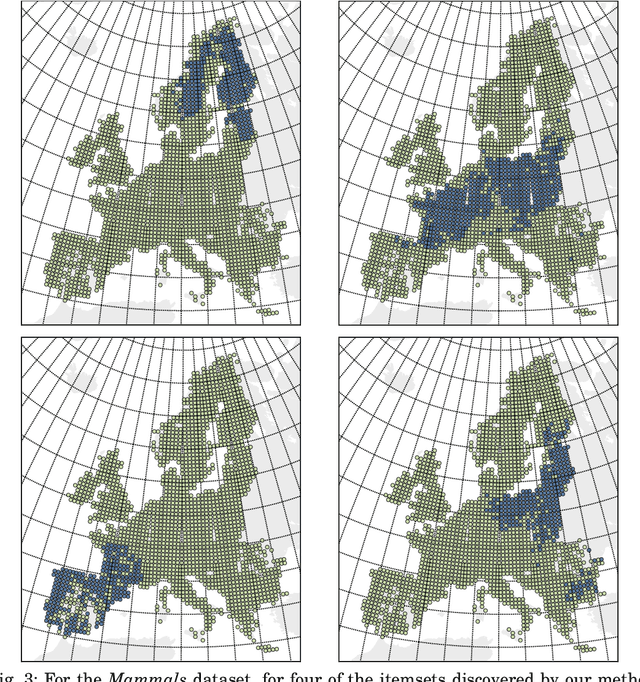
Knowledge discovery from data is an inherently iterative process. That is, what we know about the data greatly determines our expectations, and therefore, what results we would find interesting and/or surprising. Given new knowledge about the data, our expectations will change. Hence, in order to avoid redundant results, knowledge discovery algorithms ideally should follow such an iterative updating procedure. With this in mind, we introduce a well-founded approach for succinctly summarizing data with the most informative itemsets; using a probabilistic maximum entropy model, we iteratively find the itemset that provides us the most novel information--that is, for which the frequency in the data surprises us the most---and in turn we update our model accordingly. As we use the Maximum Entropy principle to obtain unbiased probabilistic models, and only include those itemsets that are most informative with regard to the current model, the summaries we construct are guaranteed to be both descriptive and non-redundant. The algorithm that we present, called MTV, can either discover the top-$k$ most informative itemsets, or we can employ either the Bayesian Information Criterion (BIC) or the Minimum Description Length (MDL) principle to automatically identify the set of itemsets that together summarize the data well. In other words, our method will `tell you what you need to know' about the data. Importantly, it is a one-phase algorithm: rather than picking itemsets from a user-provided candidate set, itemsets and their supports are mined on-the-fly. To further its applicability, we provide an efficient method to compute the maximum entropy distribution using Quick Inclusion-Exclusion. Experiments on our method, using synthetic, benchmark, and real data, show that the discovered summaries are succinct, and correctly identify the key patterns in the data.
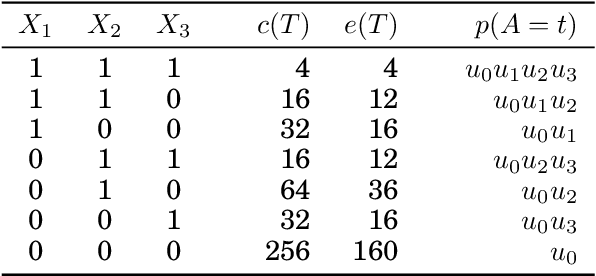
Testing Conditional Independence on Discrete Data using Stochastic Complexity
Mar 12, 2019
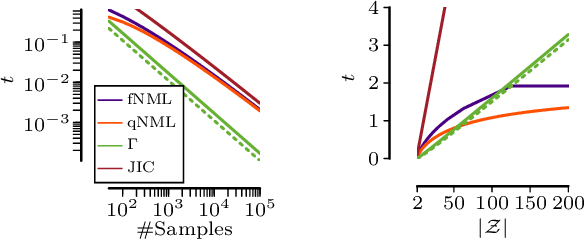
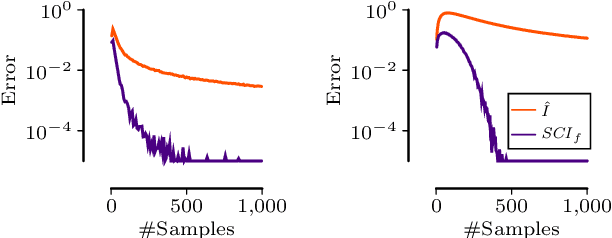
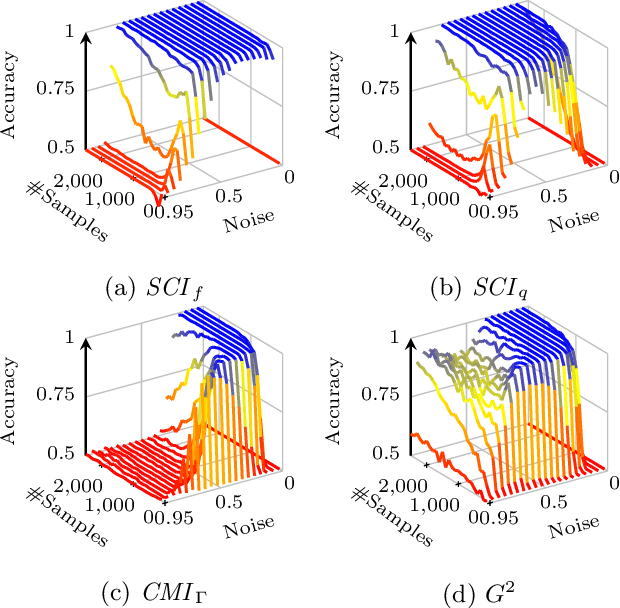
Testing for conditional independence is a core aspect of constraint-based causal discovery. Although commonly used tests are perfect in theory, they often fail to reject independence in practice, especially when conditioning on multiple variables. We focus on discrete data and propose a new test based on the notion of algorithmic independence that we instantiate using stochastic complexity. Amongst others, we show that our proposed test, SCI, is an asymptotically unbiased as well as $L_2$ consistent estimator for conditional mutual information (CMI). Further, we show that SCI can be reformulated to find a sensible threshold for CMI that works well on limited samples. Empirical evaluation shows that SCI has a lower type II error than commonly used tests. As a result, we obtain a higher recall when we use SCI in causal discovery algorithms, without compromising the precision.
The Long and the Short of It: Summarising Event Sequences with Serial Episodes
Feb 07, 2019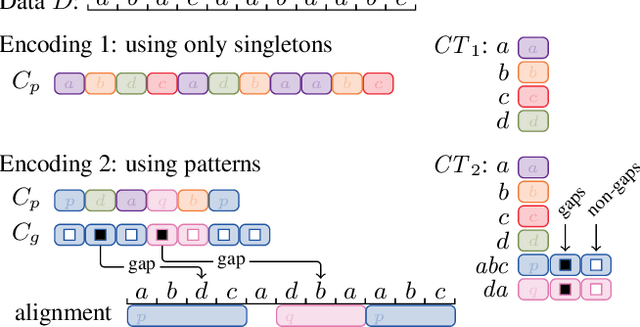
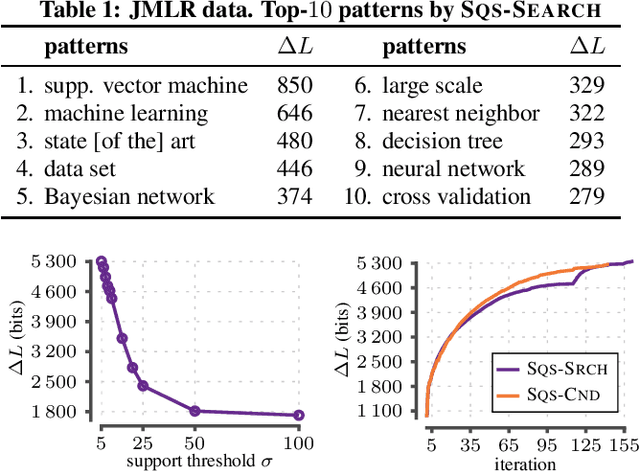
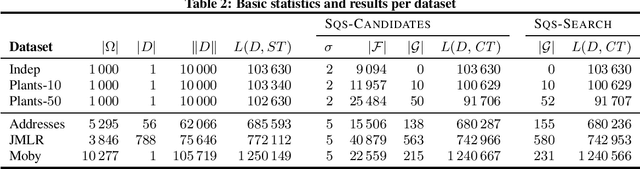
An ideal outcome of pattern mining is a small set of informative patterns, containing no redundancy or noise, that identifies the key structure of the data at hand. Standard frequent pattern miners do not achieve this goal, as due to the pattern explosion typically very large numbers of highly redundant patterns are returned. We pursue the ideal for sequential data, by employing a pattern set mining approach-an approach where, instead of ranking patterns individually, we consider results as a whole. Pattern set mining has been successfully applied to transactional data, but has been surprisingly under studied for sequential data. In this paper, we employ the MDL principle to identify the set of sequential patterns that summarises the data best. In particular, we formalise how to encode sequential data using sets of serial episodes, and use the encoded length as a quality score. As search strategy, we propose two approaches: the first algorithm selects a good pattern set from a large candidate set, while the second is a parameter-free any-time algorithm that mines pattern sets directly from the data. Experimentation on synthetic and real data demonstrates we efficiently discover small sets of informative patterns.
We Are Not Your Real Parents: Telling Causal from Confounded using MDL
Jan 21, 2019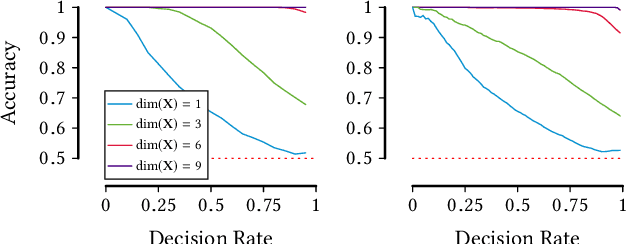
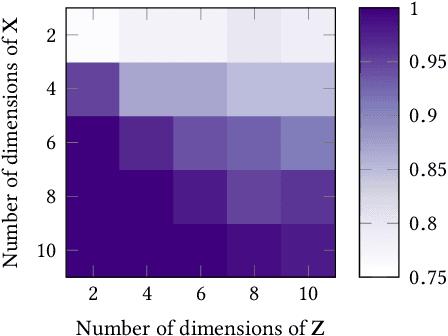

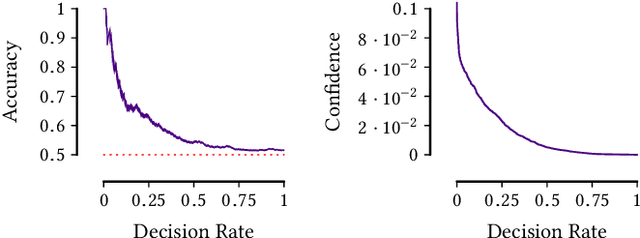
Given data over variables $(X_1,...,X_m, Y)$ we consider the problem of finding out whether $X$ jointly causes $Y$ or whether they are all confounded by an unobserved latent variable $Z$. To do so, we take an information-theoretic approach based on Kolmogorov complexity. In a nutshell, we follow the postulate that first encoding the true cause, and then the effects given that cause, results in a shorter description than any other encoding of the observed variables. The ideal score is not computable, and hence we have to approximate it. We propose to do so using the Minimum Description Length (MDL) principle. We compare the MDL scores under the models where $X$ causes $Y$ and where there exists a latent variables $Z$ confounding both $X$ and $Y$ and show our scores are consistent. To find potential confounders we propose using latent factor modeling, in particular, probabilistic PCA (PPCA). Empirical evaluation on both synthetic and real-world data shows that our method, CoCa, performs very well -- even when the true generating process of the data is far from the assumptions made by the models we use. Moreover, it is robust as its accuracy goes hand in hand with its confidence.