 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarizing Data Succinctly with the Most Informative Itemsets
Apr 27, 2019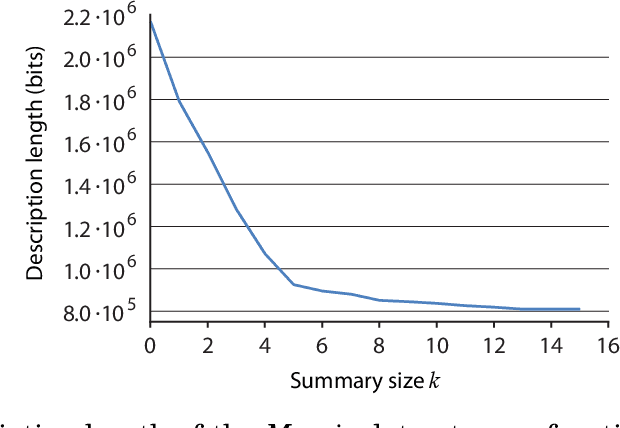
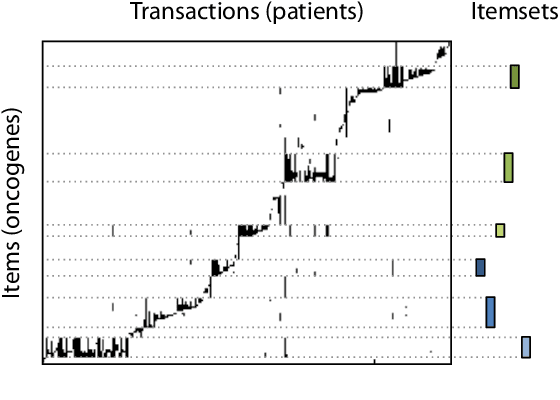
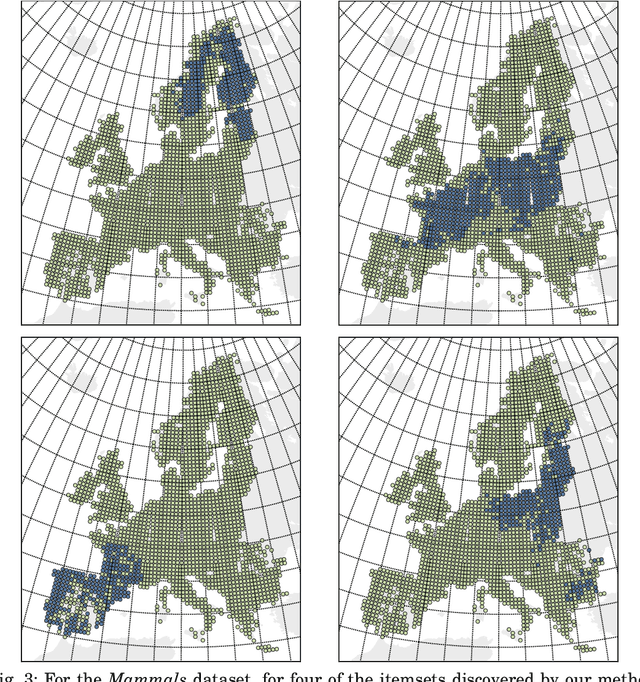
Knowledge discovery from data is an inherently iterative process. That is, what we know about the data greatly determines our expectations, and therefore, what results we would find interesting and/or surprising. Given new knowledge about the data, our expectations will change. Hence, in order to avoid redundant results, knowledge discovery algorithms ideally should follow such an iterative updating procedure. With this in mind, we introduce a well-founded approach for succinctly summarizing data with the most informative itemsets; using a probabilistic maximum entropy model, we iteratively find the itemset that provides us the most novel information--that is, for which the frequency in the data surprises us the most---and in turn we update our model accordingly. As we use the Maximum Entropy principle to obtain unbiased probabilistic models, and only include those itemsets that are most informative with regard to the current model, the summaries we construct are guaranteed to be both descriptive and non-redundant. The algorithm that we present, called MTV, can either discover the top-$k$ most informative itemsets, or we can employ either the Bayesian Information Criterion (BIC) or the Minimum Description Length (MDL) principle to automatically identify the set of itemsets that together summarize the data well. In other words, our method will `tell you what you need to know' about the data. Importantly, it is a one-phase algorithm: rather than picking itemsets from a user-provided candidate set, itemsets and their supports are mined on-the-fly. To further its applicability, we provide an efficient method to compute the maximum entropy distribution using Quick Inclusion-Exclusion. Experiments on our method, using synthetic, benchmark, and real data, show that the discovered summaries are succinct, and correctly identify the key patterns in the data.
Using Background Knowledge to Rank Itemsets
Feb 08, 2019
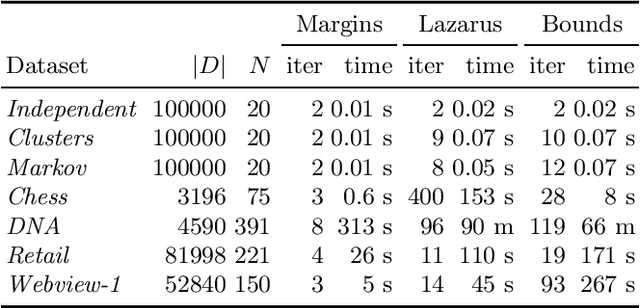
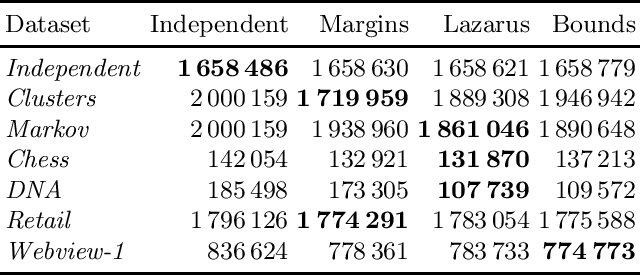
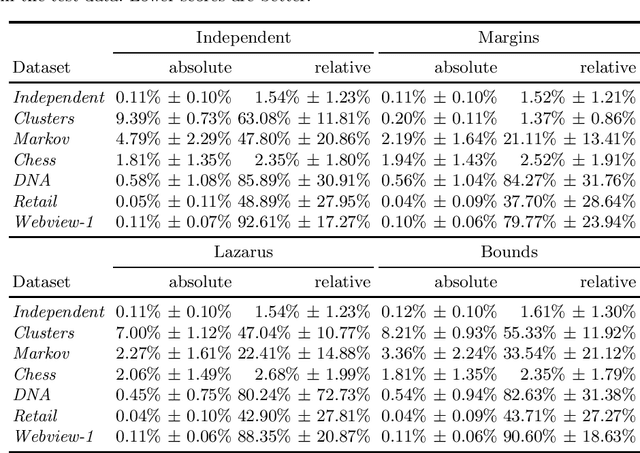
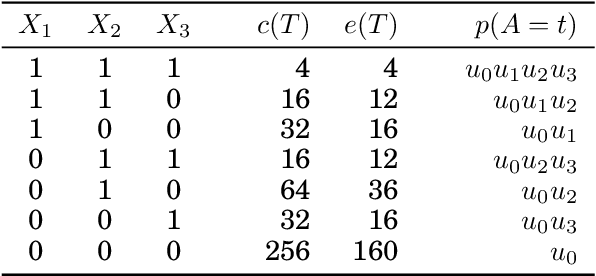
Assessing the quality of discovered results is an important open problem in data mining. Such assessment is particularly vital when mining itemsets, since commonly many of the discovered patterns can be easily explained by background knowledge. The simplest approach to screen uninteresting patterns is to compare the observed frequency against the independence model. Since the parameters for the independence model are the column margins, we can view such screening as a way of using the column margins as background knowledge. In this paper we study techniques for more flexible approaches for infusing background knowledge. Namely, we show that we can efficiently use additional knowledge such as row margins, lazarus counts, and bounds of ones. We demonstrate that these statistics describe forms of data that occur in practice and have been studied in data mining. To infuse the information efficiently we use a maximum entropy approach. In its general setting, solving a maximum entropy model is infeasible, but we demonstrate that for our setting it can be solved in polynomial time. Experiments show that more sophisticated models fit the data better and that using more information improves the frequency prediction of itemsets.