 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Is Enough Not Enough? Illusory Completion in Search Agents
Feb 07, 2026Recent search agents leverage multi-turn reasoning and search tools to achieve strong performance on multi-hop and long-horizon benchmarks. Yet it remains unclear whether they reliably reason across all requirements by tracking, verifying, and maintaining multiple conditions in these questions. We study this capability under multi-constraint problems, where valid answers must satisfy several constraints simultaneously. We find that illusory completion frequently occurs, wherein agents believe tasks are complete despite unresolved or violated constraints, leading to underverified answers. To diagnose this behavior, we introduce the Epistemic Ledger, an evaluation framework that tracks evidential support and agents' beliefs for each constraint throughout multi-turn reasoning. Our analysis reveals four recurring failure patterns: bare assertions, overlooked refutations, stagnation, and premature exit. Motivated by these findings, we examine whether explicit constraint-state tracking during execution mitigates these failures via LiveLedger, an inference-time tracker. This simple intervention consistently improves performance, substantially reducing underverified answers (by up to 26.5%) and improving overall accuracy (by up to 11.6%) on multi-constraint problems.
Adaptive Retrieval for Reasoning-Intensive Retrieval
Jan 08, 2026We study leveraging adaptive retrieval to ensure sufficient "bridge" documents are retrieved for reasoning-intensive retrieval. Bridge documents are those that contribute to the reasoning process yet are not directly relevant to the initial query. While existing reasoning-based reranker pipelines attempt to surface these documents in ranking, they suffer from bounded recall. Naive solution with adaptive retrieval into these pipelines often leads to planning error propagation. To address this, we propose REPAIR, a framework that bridges this gap by repurposing reasoning plans as dense feedback signals for adaptive retrieval. Our key distinction is enabling mid-course correction during reranking through selective adaptive retrieval, retrieving documents that support the pivotal plan. Experimental results on reasoning-intensive retrieval and complex QA tasks demonstrate that our method outperforms existing baselines by 5.6%pt.
Hybrid Deep Searcher: Integrating Parallel and Sequential Search Reasoning
Aug 26, 2025Large reasoning models (LRMs) have demonstrated strong performance in complex, multi-step reasoning tasks. Existing methods enhance LRMs by sequentially integrating external knowledge retrieval; models iteratively generate queries, retrieve external information, and progressively reason over this information. However, purely sequential querying increases inference latency and context length, diminishing coherence and potentially reducing accuracy. To address these limitations, we introduce HDS-QA (Hybrid Deep Search QA), a synthetic dataset automatically generated from Natural Questions, explicitly designed to train LRMs to distinguish parallelizable from sequential queries. HDS-QA comprises hybrid-hop questions that combine parallelizable independent subqueries (executable simultaneously) and sequentially dependent subqueries (requiring step-by-step resolution), along with synthetic reasoning-querying-retrieval paths involving parallel queries. We fine-tune an LRM using HDS-QA, naming the model HybridDeepSearcher, which outperforms state-of-the-art baselines across multiple benchmarks, notably achieving +15.9 and +11.5 F1 on FanOutQA and a subset of BrowseComp, respectively, both requiring comprehensive and exhaustive search. Experimental results highlight two key advantages: HybridDeepSearcher reaches comparable accuracy with fewer search turns, significantly reducing inference latency, and it effectively scales as more turns are permitted. These results demonstrate the efficiency, scalability, and effectiveness of explicitly training LRMs to leverage hybrid parallel and sequential querying.
Collective Relevance Labeling for Passage Retrieval
May 09, 2022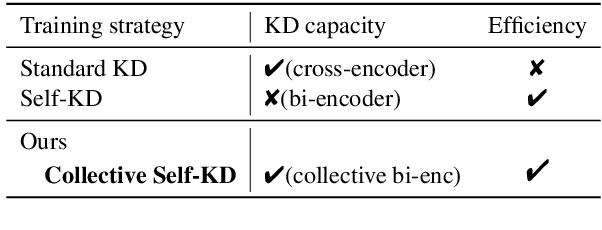
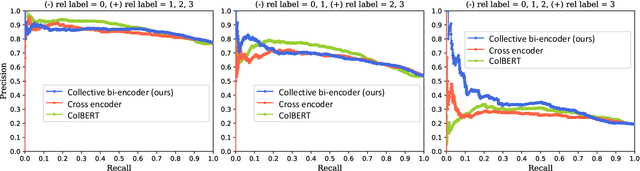
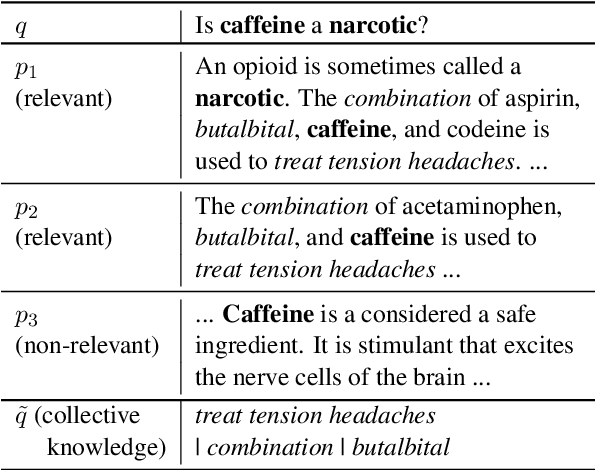
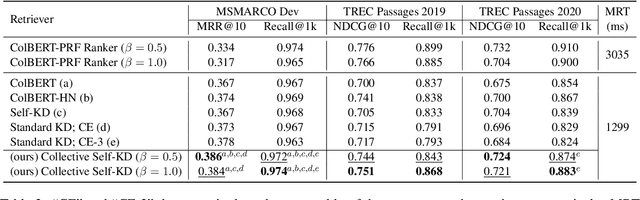
Deep learning for Information Retrieval (IR) requires a large amount of high-quality query-document relevance labels, but such labels are inherently sparse. Label smoothing redistributes some observed probability mass over unobserved instances, often uniformly, uninformed of the true distribution. In contrast, we propose knowledge distillation for informed labeling, without incurring high computation overheads at evaluation time. Our contribution is designing a simple but efficient teacher model which utilizes collective knowledge, to outperform state-of-the-arts distilled from a more complex teacher model. Specifically, we train up to x8 faster than the state-of-the-art teacher, while distilling the rankings better. Our code is publicly available at https://github.com/jihyukkim-nlp/CollectiveKD