 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Entropy Regularized Reinforcement Learning for Efficient Encrypted Policy Synthesis
Jun 14, 2025
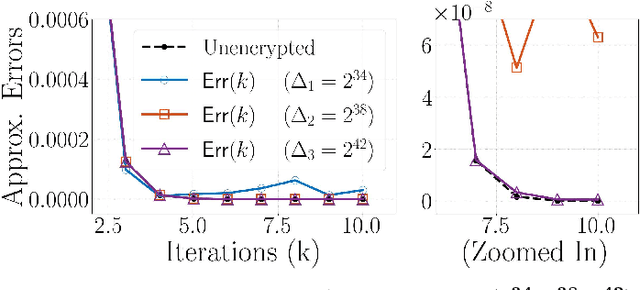
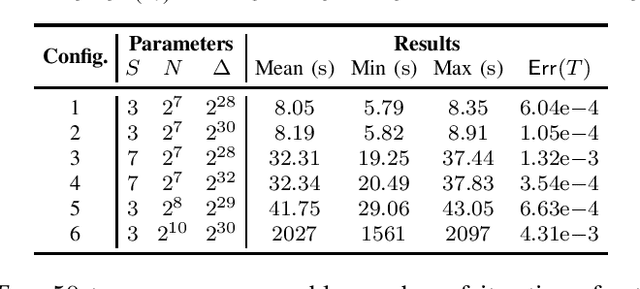
We propose an efficient encrypted policy synthesis to develop privacy-preserving model-based reinforcement learning. We first demonstrate that the relative-entropy-regularized reinforcement learning framework offers a computationally convenient linear and ``min-free'' structure for value iteration, enabling a direct and efficient integration of fully homomorphic encryption with bootstrapping into policy synthesis. Convergence and error bounds are analyzed as encrypted policy synthesis propagates errors under the presence of encryption-induced errors including quantization and bootstrapping. Theoretical analysis is validated by numerical simulations. Results demonstrate the effectiveness of the RERL framework in integrating FHE for encrypted policy synthesis.
* 6 pages, 2 figures, Published in IEEE Control Systems Letters, June 2025
Efficient Implementation of Reinforcement Learning over Homomorphic Encryption
Apr 12, 2025We investigate encrypted control policy synthesis over the cloud. While encrypted control implementations have been studied previously, we focus on the less explored paradigm of privacy-preserving control synthesis, which can involve heavier computations ideal for cloud outsourcing. We classify control policy synthesis into model-based, simulator-driven, and data-driven approaches and examine their implementation over fully homomorphic encryption (FHE) for privacy enhancements. A key challenge arises from comparison operations (min or max) in standard reinforcement learning algorithms, which are difficult to execute over encrypted data. This observation motivates our focus on Relative-Entropy-regularized reinforcement learning (RL) problems, which simplifies encrypted evaluation of synthesis algorithms due to their comparison-free structures. We demonstrate how linearly solvable value iteration, path integral control, and Z-learning can be readily implemented over FHE. We conduct a case study of our approach through numerical simulations of encrypted Z-learning in a grid world environment using the CKKS encryption scheme, showing convergence with acceptable approximation error. Our work suggests the potential for secure and efficient cloud-based reinforcement learning.
* 6 pages, 3 figures