 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterial-Agnostic Zero-Shot Thermal Inference for Metal Additive Manufacturing via a Parametric PINN Framework
Apr 16, 2026Accurate thermal modeling in metal additive manufacturing (AM) is essential for understanding the process-structure-performance relationship. While prior studies have explored generalization across unseen process conditions, they often require extensive datasets, costly retraining, or pre-training. Generalization across different materials also remains relatively unexplored due to the challenges posed by distinct material-dependent thermal behaviors. This paper introduces a parametric physics-informed neural network (PINN) framework for zero-shot generalization across arbitrary materials without labeled data, retraining, or pre-training. The framework adopts a decoupled parametric PINN architecture that separately encodes material properties and spatiotemporal coordinates, fusing them through conditional modulation to better align with the multiplicative role of material parameters in the governing equation and boundary conditions. Physics-guided output scaling derived from Rosenthal's analytical solution and a hybrid optimization strategy are further incorporated to enhance physical consistency, training stability, and convergence. Experiments on bare plate laser powder bed fusion (LPBF) across diverse metal alloys, including both in-distribution and out-of-distribution cases, demonstrate effective zero-shot generalizability along with superior training efficiency. Specifically, the proposed framework achieved up to a 64.2% reduction in relative L2 error compared to the non-parametric baseline while surpassing its performance within only 4.4% of the baseline training epochs. Ablation studies confirm that the proposed framework's components are broadly applicable to other PINN-based approaches. Overall, the proposed framework provides an efficient and scalable material-agnostic solution for zero-shot thermal modeling, contributing to more flexible and practical deployment in metal AM.
Shared Emotion Geometry Across Small Language Models: A Cross-Architecture Study of Representation, Behavior, and Methodological Confounds
Apr 13, 2026We extract 21-emotion vector sets from twelve small language models (six architectures x base/instruct, 1B-8B parameters) under a unified comprehension-mode pipeline at fp16 precision, and compare the resulting geometries via representational similarity analysis on raw cosine RDMs. The five mature architectures (Qwen 2.5 1.5B, SmolLM2 1.7B, Llama 3.2 3B, Mistral 7B v0.3, Llama 3.1 8B) share nearly identical 21-emotion geometry, with pairwise RDM Spearman correlations of 0.74-0.92. This universality persists across diametrically opposed behavioral profiles: Qwen 2.5 and Llama 3.2 occupy opposite poles of MTI Compliance facets yet produce nearly identical emotion RDMs (rho = 0.81), so behavioral facet differences arise above the shared emotion representation. Gemma-3 1B base, the one immature case in our dataset, exhibits extreme residual-stream anisotropy (0.997) and is restructured by RLHF across all geometric descriptors, whereas the five already-mature families show within-family base x instruct RDM correlations of rho >= 0.92 (Mistral 7B v0.3 at rho = 0.985), suggesting RLHF restructures only representations that are not yet organized. Methodologically, we show that what prior work has read as a single comprehension-vs-generation method effect in fact decomposes into four distinct layers -- a coarse method-dependent dissociation, robust sub-parameter sensitivity within generation, a true precision (fp16 vs INT8) effect, and a conflated cross-experiment bias that distorts in opposite directions for different models -- so that a single rho between two prior emotion-vector studies is not a safe basis for interpretation without the layered decomposition.
Extracting and Steering Emotion Representations in Small Language Models: A Methodological Comparison
Apr 05, 2026Small language models (SLMs) in the 100M-10B parameter range increasingly power production systems, yet whether they possess the internal emotion representations recently discovered in frontier models remains unknown. We present the first comparative analysis of emotion vector extraction methods for SLMs, evaluating 9 models across 5 architectural families (GPT-2, Gemma, Qwen, Llama, Mistral) using 20 emotions and two extraction methods (generation-based and comprehension-based). Generation-based extraction produces statistically superior emotion separation (Mann-Whitney p = 0.007; Cohen's d = -107.5), with the advantage modulated by instruction tuning and architecture. Emotion representations localize at middle transformer layers (~50% depth), following a U-shaped curve that is architecture-invariant from 124M to 3B parameters. We validate these findings against representational anisotropy baselines across 4 models and confirm causal behavioral effects through steering experiments, independently verified by an external emotion classifier (92% success rate, 37/40 scenarios). Steering reveals three regimes -- surgical (coherent text transformation), repetitive collapse, and explosive (text degradation) -- quantified by perplexity ratios and separated by model architecture rather than scale. We document cross-lingual emotion entanglement in Qwen, where steering activates semantically aligned Chinese tokens that RLHF does not suppress, raising safety concerns for multilingual deployment. This work provides methodological guidelines for emotion research on open-weight models and contributes to the Model Medicine series by bridging external behavioral profiling with internal representational analysis.
MTI: A Behavior-Based Temperament Profiling System for AI Agents
Apr 02, 2026AI models of equivalent capability can exhibit fundamentally different behavioral patterns, yet no standardized instrument exists to measure these dispositional differences. Existing approaches either borrow human personality dimensions and rely on self-report (which diverges from actual behavior in LLMs) or treat behavioral variation as a defect rather than a trait. We introduce the Model Temperament Index (MTI), a behavior-based profiling system that measures AI agent temperament across four axes: Reactivity (environmental sensitivity), Compliance (instruction-behavior alignment), Sociality (relational resource allocation), and Resilience (stress resistance). Grounded in the Four Shell Model from Model Medicine, MTI measures what agents do, not what they say about themselves, using structured examination protocols with a two-stage design that separates capability from disposition. We profile 10 small language models (1.7B-9B parameters, 6 organizations, 3 training paradigms) and report five principal findings: (1) the four axes are largely independent among instruction-tuned models (all |r| < 0.42); (2) within-axis facet dissociations are empirically confirmed -- Compliance decomposes into fully independent formal and stance facets (r = 0.002), while Resilience decomposes into inversely related cognitive and adversarial facets; (3) a Compliance-Resilience paradox reveals that opinion-yielding and fact-vulnerability operate through independent channels; (4) RLHF reshapes temperament not only by shifting axis scores but by creating within-axis facet differentiation absent in the unaligned base model; and (5) temperament is independent of model size (1.7B-9B), confirming that MTI measures disposition rather than capability.
Listen First, Then Answer: Timestamp-Grounded Speech Reasoning
Mar 19, 2026Large audio-language models (LALMs) can generate reasoning chains for their predictions, but it remains unclear whether these reasoning chains remain grounded in the input audio. In this paper, we propose an RL-based strategy that grounds the reasoning outputs of LALMs with explicit timestamp annotations referring to relevant segments of the audio signal. Our analysis shows that timestamp grounding leads the model to attend more strongly to audio tokens during reasoning generation. Experiments on four speech-based benchmark datasets demonstrate that our approach improves performance compared to both zero-shot reasoning and fine-tuning without timestamp grounding. Additionally, grounding amplifies desirable reasoning behaviors, such as region exploration, audiology verification, and consistency, underscoring the importance of grounding mechanisms for faithful multimodal reasoning.
Model Medicine: A Clinical Framework for Understanding, Diagnosing, and Treating AI Models
Mar 05, 2026Model Medicine is the science of understanding, diagnosing, treating, and preventing disorders in AI models, grounded in the principle that AI models -- like biological organisms -- have internal structures, dynamic processes, heritable traits, observable symptoms, classifiable conditions, and treatable states. This paper introduces Model Medicine as a research program, bridging the gap between current AI interpretability research (anatomical observation) and the systematic clinical practice that complex AI systems increasingly require. We present five contributions: (1) a discipline taxonomy organizing 15 subdisciplines across four divisions -- Basic Model Sciences, Clinical Model Sciences, Model Public Health, and Model Architectural Medicine; (2) the Four Shell Model (v3.3), a behavioral genetics framework empirically grounded in 720 agents and 24,923 decisions from the Agora-12 program, explaining how model behavior emerges from Core--Shell interaction; (3) Neural MRI (Model Resonance Imaging), a working open-source diagnostic tool mapping five medical neuroimaging modalities to AI interpretability techniques, validated through four clinical cases demonstrating imaging, comparison, localization, and predictive capability; (4) a five-layer diagnostic framework for comprehensive model assessment; and (5) clinical model sciences including the Model Temperament Index for behavioral profiling, Model Semiology for symptom description, and M-CARE for standardized case reporting. We additionally propose the Layered Core Hypothesis -- a biologically-inspired three-layer parameter architecture -- and a therapeutic framework connecting diagnosis to treatment.
Knowing When to Answer: Adaptive Confidence Refinement for Reliable Audio-Visual Question Answering
Feb 04, 2026We present a formal problem formulation for \textit{Reliable} Audio-Visual Question Answering ($\mathcal{R}$-AVQA), where we prefer abstention over answering incorrectly. While recent AVQA models have high accuracy, their ability to identify when they are likely wrong and their consequent abstention from answering remain underexplored areas of research. To fill this gap, we explore several approaches and then propose Adaptive Confidence Refinement (ACR), a lightweight method to further enhance the performance of $\mathcal{R}$-AVQA. Our key insight is that the Maximum Softmax Probability (MSP) is Bayes-optimal only under strong calibration, a condition usually not met in deep neural networks, particularly in multimodal models. Instead of replacing MSP, our ACR maintains it as a primary confidence signal and applies input-adaptive residual corrections when MSP is deemed unreliable. ACR introduces two learned heads: i) a Residual Risk Head that predicts low-magnitude correctness residuals that MSP does not capture, and ii) a Confidence Gating Head to determine MSP trustworthiness. Our experiments and theoretical analysis show that ACR consistently outperforms existing methods on in- and out-of-disrtibution, and data bias settings across three different AVQA architectures, establishing a solid foundation for $\mathcal{R}$-AVQA task. The code and checkpoints will be available upon acceptance \href{https://github.com/PhuTran1005/R-AVQA}{at here}
Time-Efficient and Identity-Consistent Virtual Try-On Using A Variant of Altered Diffusion Models
Mar 12, 2024This study discusses the critical issues of Virtual Try-On in contemporary e-commerce and the prospective metaverse, emphasizing the challenges of preserving intricate texture details and distinctive features of the target person and the clothes in various scenarios, such as clothing texture and identity characteristics like tattoos or accessories. In addition to the fidelity of the synthesized images, the efficiency of the synthesis process presents a significant hurdle. Various existing approaches are explored, highlighting the limitations and unresolved aspects, e.g., identity information omission, uncontrollable artifacts, and low synthesis speed. It then proposes a novel diffusion-based solution that addresses garment texture preservation and user identity retention during virtual try-on. The proposed network comprises two primary modules - a warping module aligning clothing with individual features and a try-on module refining the attire and generating missing parts integrated with a mask-aware post-processing technique ensuring the integrity of the individual's identity. It demonstrates impressive results, surpassing the state-of-the-art in speed by nearly 20 times during inference, with superior fidelity in qualitative assessments. Quantitative evaluations confirm comparable performance with the recent SOTA method on the VITON-HD and Dresscode datasets.
Hybrid full-field thermal characterization of additive manufacturing processes using physics-informed neural networks with data
Jun 15, 2022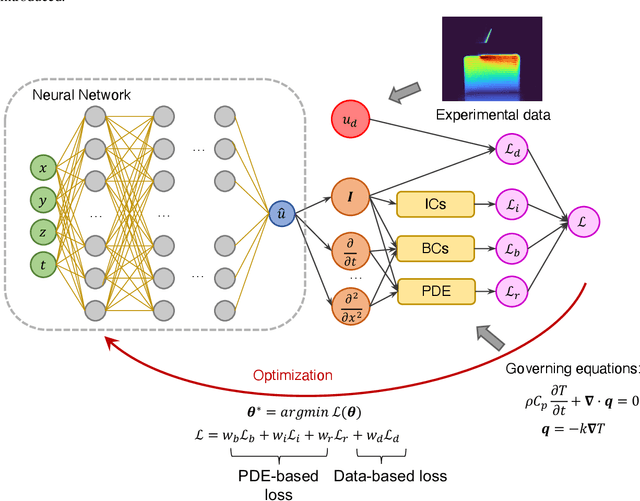

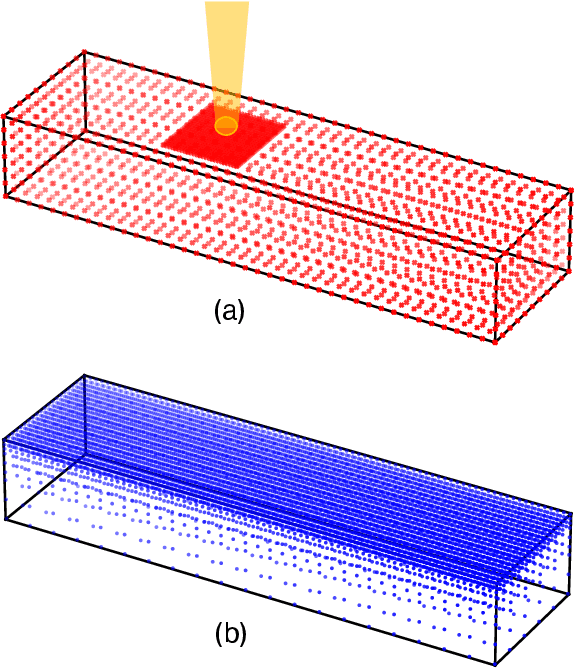
Understanding the thermal behavior of additive manufacturing (AM) processes is crucial for enhancing the quality control and enabling customized process design. Most purely physics-based computational models suffer from intensive computational costs, thus not suitable for online control and iterative design application. Data-driven models taking advantage of the latest developed computational tools can serve as a more efficient surrogate, but they are usually trained over a large amount of simulation data and often fail to effectively use small but high-quality experimental data. In this work, we developed a hybrid physics-based data-driven thermal modeling approach of AM processes using physics-informed neural networks. Specifically, partially observed temperature data measured from an infrared camera is combined with the physics laws to predict full-field temperature history and to discover unknown material and process parameters. In the numerical and experimental examples, the effectiveness of adding auxiliary training data and using the technique of transfer learning on training efficiency and prediction accuracy, as well as the ability to identify unknown parameters with partially observed data, are demonstrated. The results show that the hybrid thermal model can effectively identify unknown parameters and capture the full-field temperature accurately, and thus it has the potential to be used in iterative process design and real-time process control of AM.
Convolutional Attention Networks for Multimodal Emotion Recognition from Speech and Text Data
May 17, 2018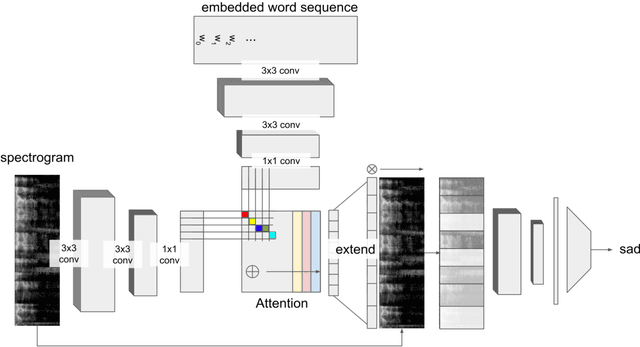
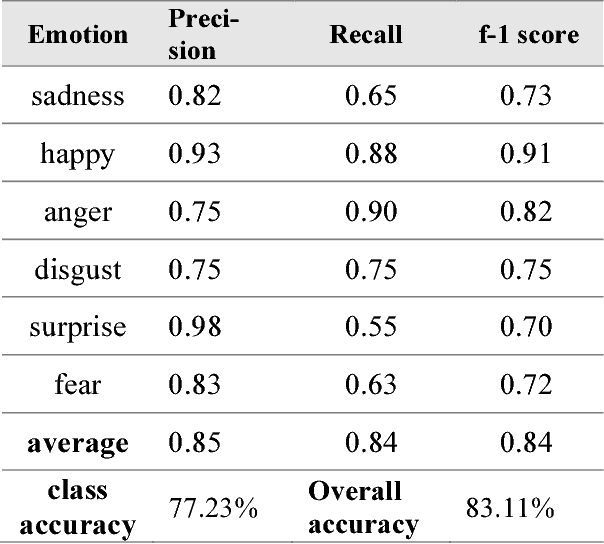

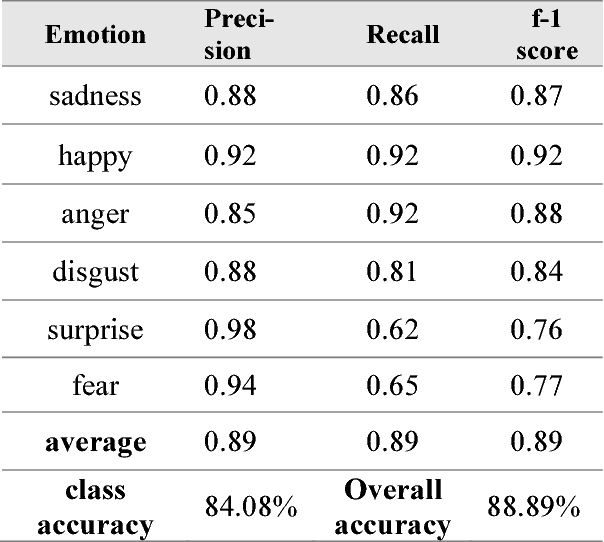
Emotion recognition has become a popular topic of interest, especially in the field of human computer interaction. Previous works involve unimodal analysis of emotion, while recent efforts focus on multi-modal emotion recognition from vision and speech. In this paper, we propose a new method of learning about the hidden representations between just speech and text data using convolutional attention networks. Compared to the shallow model which employs simple concatenation of feature vectors, the proposed attention model performs much better in classifying emotion from speech and text data contained in the CMU-MOSEI dataset.