 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterial-Agnostic Zero-Shot Thermal Inference for Metal Additive Manufacturing via a Parametric PINN Framework
Apr 16, 2026Accurate thermal modeling in metal additive manufacturing (AM) is essential for understanding the process-structure-performance relationship. While prior studies have explored generalization across unseen process conditions, they often require extensive datasets, costly retraining, or pre-training. Generalization across different materials also remains relatively unexplored due to the challenges posed by distinct material-dependent thermal behaviors. This paper introduces a parametric physics-informed neural network (PINN) framework for zero-shot generalization across arbitrary materials without labeled data, retraining, or pre-training. The framework adopts a decoupled parametric PINN architecture that separately encodes material properties and spatiotemporal coordinates, fusing them through conditional modulation to better align with the multiplicative role of material parameters in the governing equation and boundary conditions. Physics-guided output scaling derived from Rosenthal's analytical solution and a hybrid optimization strategy are further incorporated to enhance physical consistency, training stability, and convergence. Experiments on bare plate laser powder bed fusion (LPBF) across diverse metal alloys, including both in-distribution and out-of-distribution cases, demonstrate effective zero-shot generalizability along with superior training efficiency. Specifically, the proposed framework achieved up to a 64.2% reduction in relative L2 error compared to the non-parametric baseline while surpassing its performance within only 4.4% of the baseline training epochs. Ablation studies confirm that the proposed framework's components are broadly applicable to other PINN-based approaches. Overall, the proposed framework provides an efficient and scalable material-agnostic solution for zero-shot thermal modeling, contributing to more flexible and practical deployment in metal AM.
Antibody Foundational Model : Ab-RoBERTa
Jun 16, 2025



With the growing prominence of antibody-based therapeutics, antibody engineering has gained increasing attention as a critical area of research and development. Recent progress in transformer-based protein large language models (LLMs) has demonstrated promising applications in protein sequence design and structural prediction. Moreover, the availability of large-scale antibody datasets such as the Observed Antibody Space (OAS) database has opened new avenues for the development of LLMs specialized for processing antibody sequences. Among these, RoBERTa has demonstrated improved performance relative to BERT, while maintaining a smaller parameter count (125M) compared to the BERT-based protein model, ProtBERT (420M). This reduced model size enables more efficient deployment in antibody-related applications. However, despite the numerous advantages of the RoBERTa architecture, antibody-specific foundational models built upon it have remained inaccessible to the research community. In this study, we introduce Ab-RoBERTa, a RoBERTa-based antibody-specific LLM, which is publicly available at https://huggingface.co/mogam-ai/Ab-RoBERTa. This resource is intended to support a wide range of antibody-related research applications including paratope prediction or humanness assessment.
Neuromimetic metaplasticity for adaptive continual learning
Jul 09, 2024Conventional intelligent systems based on deep neural network (DNN) models encounter challenges in achieving human-like continual learning due to catastrophic forgetting. Here, we propose a metaplasticity model inspired by human working memory, enabling DNNs to perform catastrophic forgetting-free continual learning without any pre- or post-processing. A key aspect of our approach involves implementing distinct types of synapses from stable to flexible, and randomly intermixing them to train synaptic connections with different degrees of flexibility. This strategy allowed the network to successfully learn a continuous stream of information, even under unexpected changes in input length. The model achieved a balanced tradeoff between memory capacity and performance without requiring additional training or structural modifications, dynamically allocating memory resources to retain both old and new information. Furthermore, the model demonstrated robustness against data poisoning attacks by selectively filtering out erroneous memories, leveraging the Hebb repetition effect to reinforce the retention of significant data.
The Surprisingly Straightforward Scene Text Removal Method With Gated Attention and Region of Interest Generation: A Comprehensive Prominent Model Analysis
Oct 14, 2022
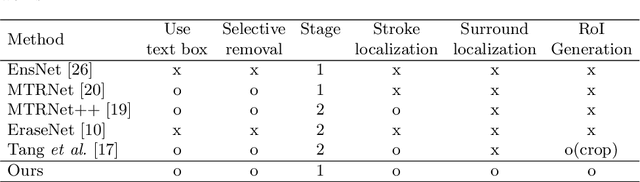
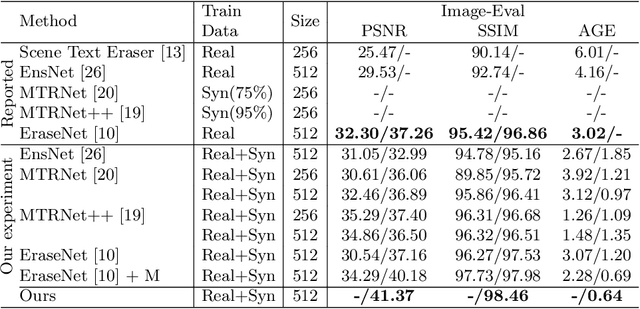
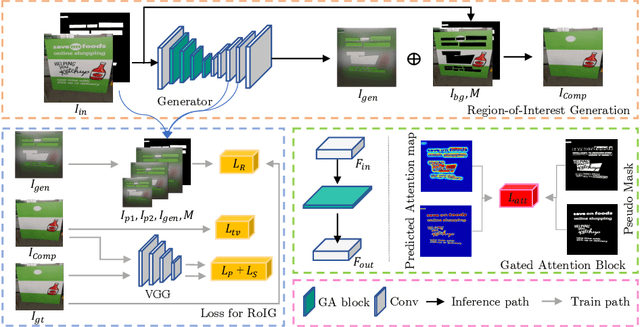
Scene text removal (STR), a task of erasing text from natural scene images, has recently attracted attention as an important component of editing text or concealing private information such as ID, telephone, and license plate numbers. While there are a variety of different methods for STR actively being researched, it is difficult to evaluate superiority because previously proposed methods do not use the same standardized training/evaluation dataset. We use the same standardized training/testing dataset to evaluate the performance of several previous methods after standardized re-implementation. We also introduce a simple yet extremely effective Gated Attention (GA) and Region-of-Interest Generation (RoIG) methodology in this paper. GA uses attention to focus on the text stroke as well as the textures and colors of the surrounding regions to remove text from the input image much more precisely. RoIG is applied to focus on only the region with text instead of the entire image to train the model more efficiently. Experimental results on the benchmark dataset show that our method significantly outperforms existing state-of-the-art methods in almost all metrics with remarkably higher-quality results. Furthermore, because our model does not generate a text stroke mask explicitly, there is no need for additional refinement steps or sub-models, making our model extremely fast with fewer parameters. The dataset and code are available at this https://github.com/naver/garnet.