 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrokking or Glitching? How Low-Precision Drives Slingshot Loss Spikes
May 07, 2026Deep neural networks exhibit periodic loss spikes during unregularized long-term training, a phenomenon known as the "Slingshot Mechanism." Existing work usually attributes this to intrinsic optimization dynamics, but its triggering mechanism remains unclear. This paper proves that this phenomenon is a result of floating-point arithmetic precision limits. As training enters a high-confidence stage, the difference between the correct-class logit and the other logits may exceed the absorption-error threshold. Then during backpropagation, the gradient of the correct class is rounded exactly to zero, while the gradients of the incorrect classes remain nonzero. This breaks the zero-sum constraint of gradients across classes and introduces a systematic drift in the parameter update of the classifier layer. We prove that this drift forms a positive feedback loop with the feature, causing the global classifier mean and the global feature mean to grow exponentially. We call this mechanism Numerical Feature Inflation (NFI). This mechanism explains the rapid norm growth before a Slingshot spike, the subsequent reappearance of gradients, and the resulting loss spike. We further show that NFI is not equivalent to an observed loss spike: in more practical tasks, partial absorption may not produce visible spikes, but it can still break the zero-sum constraint and drive rapid growth of parameter norms. Our results reinterpret Slingshot as a numerical dynamic of finite-precision training, and provide a testable explanation for abnormal parameter growth and logit divergence in late-stage training.
Multi-Modal Coreference Resolution with the Correlation between Space Structures
Sep 01, 2018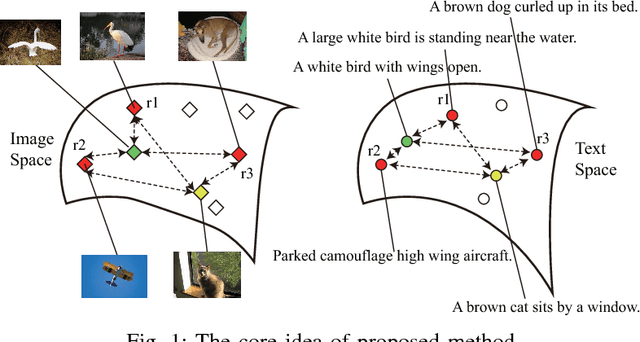
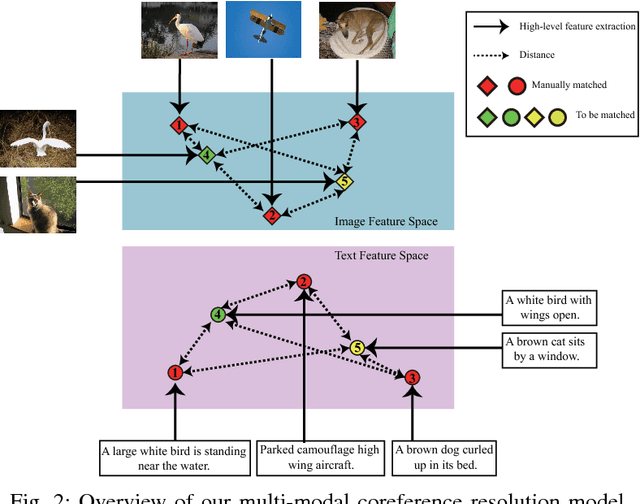
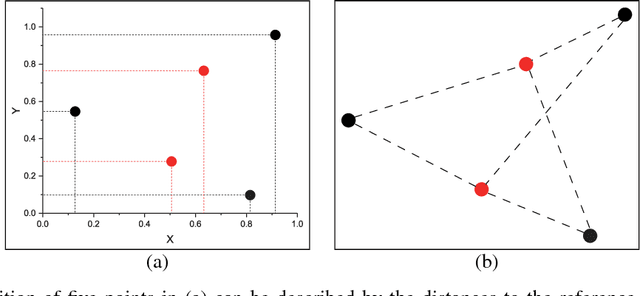
Multi-modal data is becoming more common in big data background. Finding the semantically similar objects from different modality is one of the heart problems of multi-modal learning. Most of the current methods try to learn the inter-modal correlation with extrinsic supervised information, while intrinsic structural information of each modality is neglected. The performance of these methods heavily depends on the richness of training samples. However, obtaining the multi-modal training samples is still a labor and cost intensive work. In this paper, we bring a extrinsic correlation between the space structures of each modalities in coreference resolution. With this correlation, a semi-supervised learning model for multi-modal coreference resolution is proposed. We firstly extract high-level features of images and text, then compute the distances of each object from some reference points to build the space structure of each modality. With a shared reference point set, the space structures of each modality are correlated. We employ the correlation to build a commonly shared space that the semantic distance between multi-modal objects can be computed directly. The experiments on two multi-modal datasets show that our model performs better than the existing methods with insufficient training data.