 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Robust Fusion of Many Treatments for Policy Learning
May 12, 2025Individualized treatment rules/recommendations (ITRs) aim to improve patient outcomes by tailoring treatments to the characteristics of each individual. However, when there are many treatment groups, existing methods face significant challenges due to data sparsity within treatment groups and highly unbalanced covariate distributions across groups. To address these challenges, we propose a novel calibration-weighted treatment fusion procedure that robustly balances covariates across treatment groups and fuses similar treatments using a penalized working model. The fusion procedure ensures the recovery of latent treatment group structures when either the calibration model or the outcome model is correctly specified. In the fused treatment space, practitioners can seamlessly apply state-of-the-art ITR learning methods with the flexibility to utilize a subset of covariates, thereby achieving robustness while addressing practical concerns such as fairness. We establish theoretical guarantees, including consistency, the oracle property of treatment fusion, and regret bounds when integrated with multi-armed ITR learning methods such as policy trees. Simulation studies show superior group recovery and policy value compared to existing approaches. We illustrate the practical utility of our method using a nationwide electronic health record-derived de-identified database containing data from patients with Chronic Lymphocytic Leukemia and Small Lymphocytic Lymphoma.
Multi-Task Combinatorial Bandits for Budget Allocation
Aug 31, 2024



Today's top advertisers typically manage hundreds of campaigns simultaneously and consistently launch new ones throughout the year. A crucial challenge for marketing managers is determining the optimal allocation of limited budgets across various ad lines in each campaign to maximize cumulative returns, especially given the huge uncertainty in return outcomes. In this paper, we propose to formulate budget allocation as a multi-task combinatorial bandit problem and introduce a novel online budget allocation system. The proposed system: i) integrates a Bayesian hierarchical model to intelligently utilize the metadata of campaigns and ad lines and budget size, ensuring efficient information sharing; ii) provides the flexibility to incorporate diverse modeling techniques such as Linear Regression, Gaussian Processes, and Neural Networks, catering to diverse environmental complexities; and iii) employs the Thompson sampling (TS) technique to strike a balance between exploration and exploitation. Through offline evaluation and online experiments, our system demonstrates robustness and adaptability, effectively maximizing the overall cumulative returns. A Python implementation of the proposed procedure is available at https://anonymous.4open.science/r/MCMAB.
Targeted Optimal Treatment Regime Learning Using Summary Statistics
Jan 17, 2022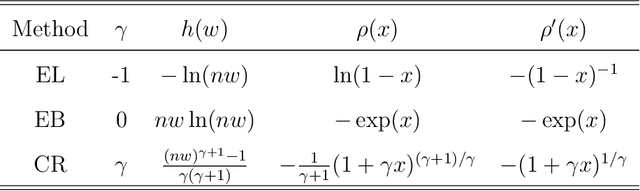
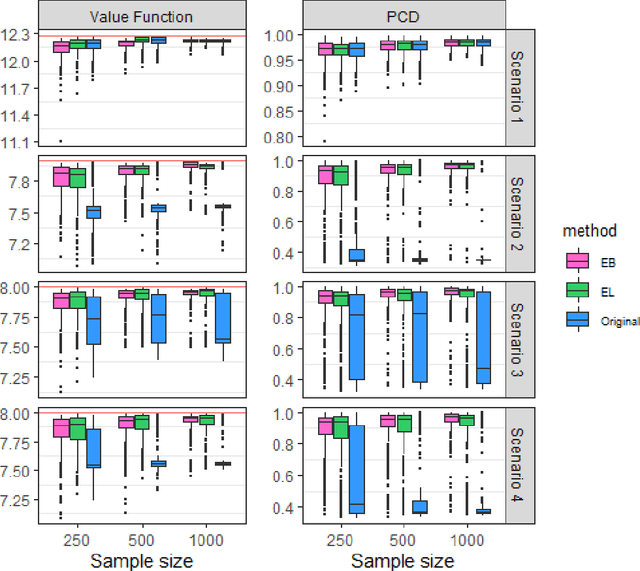
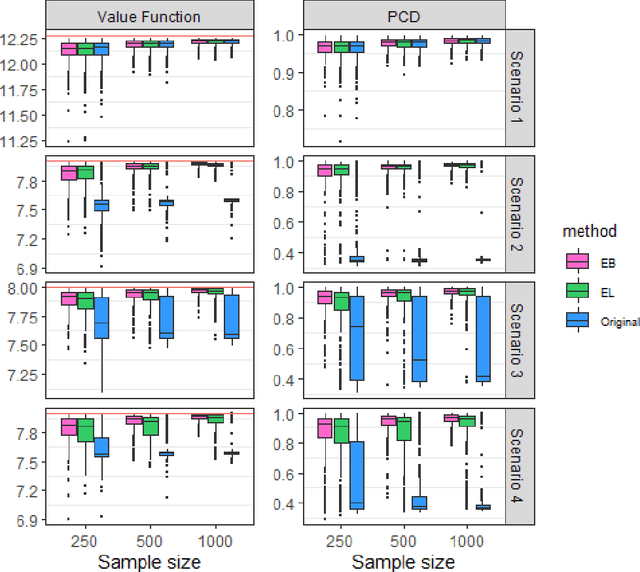
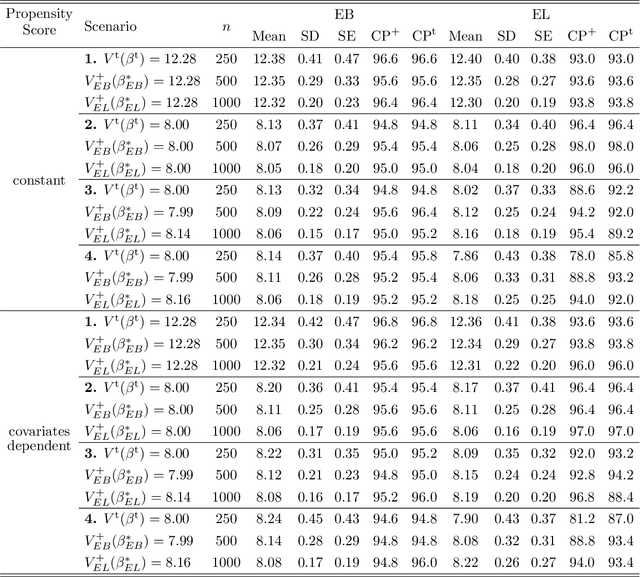
Personalized decision-making, aiming to derive optimal individualized treatment rules (ITRs) based on individual characteristics, has recently attracted increasing attention in many fields, such as medicine, social services, and economics. Current literature mainly focuses on estimating ITRs from a single source population. In real-world applications, the distribution of a target population can be different from that of the source population. Therefore, ITRs learned by existing methods may not generalize well to the target population. Due to privacy concerns and other practical issues, individual-level data from the target population is often not available, which makes ITR learning more challenging. We consider an ITR estimation problem where the source and target populations may be heterogeneous, individual data is available from the source population, and only the summary information of covariates, such as moments, is accessible from the target population. We develop a weighting framework that tailors an ITR for a given target population by leveraging the available summary statistics. Specifically, we propose a calibrated augmented inverse probability weighted estimator of the value function for the target population and estimate an optimal ITR by maximizing this estimator within a class of pre-specified ITRs. We show that the proposed calibrated estimator is consistent and asymptotically normal even with flexible semi/nonparametric models for nuisance function approximation, and the variance of the value estimator can be consistently estimated. We demonstrate the empirical performance of the proposed method using simulation studies and a real application to an eICU dataset as the source sample and a MIMIC-III dataset as the target sample.