 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Surface to Semantics: Semantic Structure Parsing for Table-Centric Document Analysis
Aug 14, 2025Documents are core carriers of information and knowl-edge, with broad applications in finance, healthcare, and scientific research. Tables, as the main medium for structured data, encapsulate key information and are among the most critical document components. Existing studies largely focus on surface-level tasks such as layout analysis, table detection, and data extraction, lacking deep semantic parsing of tables and their contextual associations. This limits advanced tasks like cross-paragraph data interpretation and context-consistent analysis. To address this, we propose DOTABLER, a table-centric semantic document parsing framework designed to uncover deep semantic links between tables and their context. DOTABLER leverages a custom dataset and domain-specific fine-tuning of pre-trained models, integrating a complete parsing pipeline to identify context segments semantically tied to tables. Built on this semantic understanding, DOTABLER implements two core functionalities: table-centric document structure parsing and domain-specific table retrieval, delivering comprehensive table-anchored semantic analysis and precise extraction of semantically relevant tables. Evaluated on nearly 4,000 pages with over 1,000 tables from real-world PDFs, DOTABLER achieves over 90% Precision and F1 scores, demonstrating superior performance in table-context semantic analysis and deep document parsing compared to advanced models such as GPT-4o.
Towards Explainability in NLP: Analyzing and Calculating Word Saliency through Word Properties
Jul 17, 2022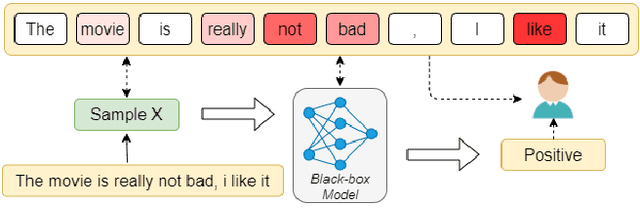
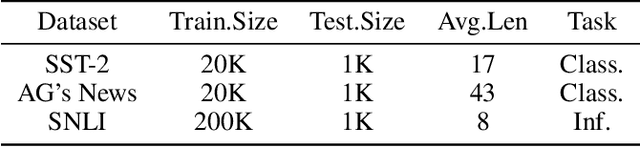

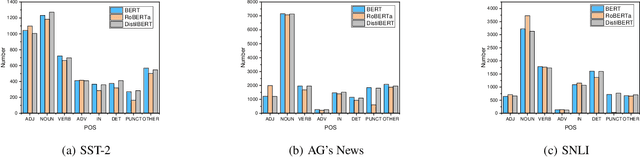
The wide use of black-box models in natural language processing brings great challenges to the understanding of the decision basis, the trustworthiness of the prediction results, and the improvement of the model performance. The words in text samples have properties that reflect their semantics and contextual information, such as the part of speech, the position, etc. These properties may have certain relationships with the word saliency, which is of great help for studying the explainability of the model predictions. In this paper, we explore the relationships between the word saliency and the word properties. According to the analysis results, we further establish a mapping model, Seq2Saliency, from the words in a text sample and their properties to the saliency values based on the idea of sequence tagging. In addition, we establish a new dataset called PrSalM, which contains each word in the text samples, the word properties, and the word saliency values. The experimental evaluations are conducted to analyze the saliency of words with different properties. The effectiveness of the Seq2Saliency model is verified.