 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling the Inherent Difficulty of Noise Filtering in RAG
Jan 06, 2026Retrieval-Augmented Generation (RAG) has become a widely adopted approach to enhance Large Language Models (LLMs) by incorporating external knowledge and reducing hallucinations. However, noisy or irrelevant documents are often introduced during RAG, potentially degrading performance and even causing hallucinated outputs. While various methods have been proposed to filter out such noise, we argue that identifying irrelevant information from retrieved content is inherently difficult and limited number of transformer layers can hardly solve this. Consequently, retrievers fail to filter out irrelevant documents entirely. Therefore, LLMs must be robust against such noise, but we demonstrate that standard fine-tuning approaches are often ineffective in enabling the model to selectively utilize relevant information while ignoring irrelevant content due to the structural constraints of attention patterns. To address this, we propose a novel fine-tuning method designed to enhance the model's ability to distinguish between relevant and irrelevant information within retrieved documents. Extensive experiments across multiple benchmarks show that our approach significantly improves the robustness and performance of LLMs.
How Much Can RAG Help the Reasoning of LLM?
Oct 03, 2024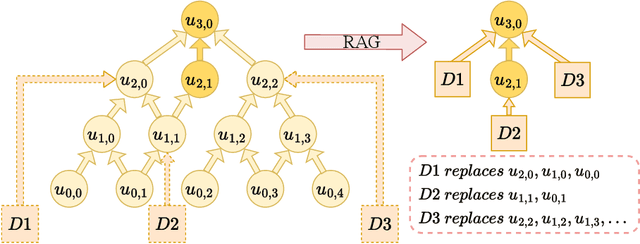
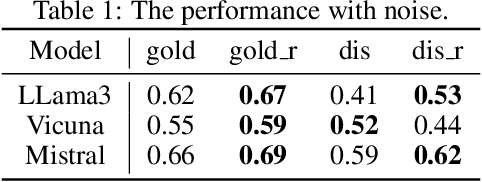
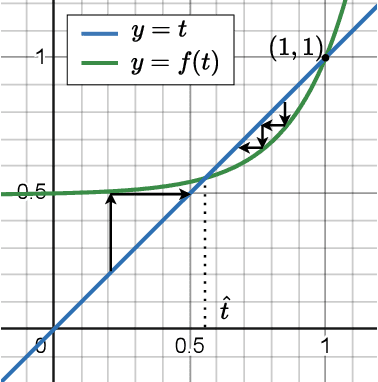
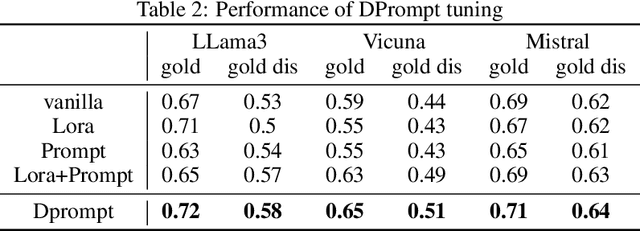
Retrieval-Augmented Generation (RAG) has gained significant popularity in modern Large Language Models (LLMs) due to its effectiveness in introducing new knowledge and reducing hallucinations. However, the deep understanding of RAG remains limited, how does RAG help the reasoning process and can RAG help improve the reasoning capability remains question. While external documents are typically considered as a method to incorporate domain-specific information, they also contain intermediate reasoning results related to the query, this suggests that documents could enhance the reasoning capability of LLMs, which has not been previously explored. In this paper, we investigate this issue in depth and find that while RAG can assist with reasoning, the help is limited. If we conceptualize the reasoning process as a tree with fixed depth, then RAG struggles to assist LLMs in performing deeper reasoning. Additionally, the information in the documents requires preprocessing to filter out noise. We demonstrate that this preprocessing is difficult to achieve simply fine-tuning of the LLM, it often necessitates numerous additional transformer layers to solve the problem. To simplify the problem, we propose DPrompt tuning, which effectively resolves the issue within just limited transformer layers, leading to improved performance.