 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmo2Vec: Learning Generalized Emotion Representation by Multi-task Training
Sep 12, 2018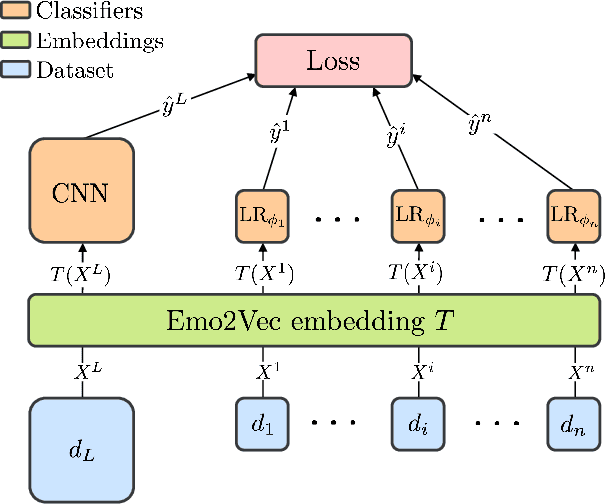


In this paper, we propose Emo2Vec which encodes emotional semantics into vectors. We train Emo2Vec by multi-task learning six different emotion-related tasks, including emotion/sentiment analysis, sarcasm classification, stress detection, abusive language classification, insult detection, and personality recognition. Our evaluation of Emo2Vec shows that it outperforms existing affect-related representations, such as Sentiment-Specific Word Embedding and DeepMoji embeddings with much smaller training corpora. When concatenated with GloVe, Emo2Vec achieves competitive performances to state-of-the-art results on several tasks using a simple logistic regression classifier.
Finding Good Representations of Emotions for Text Classification
Aug 22, 2018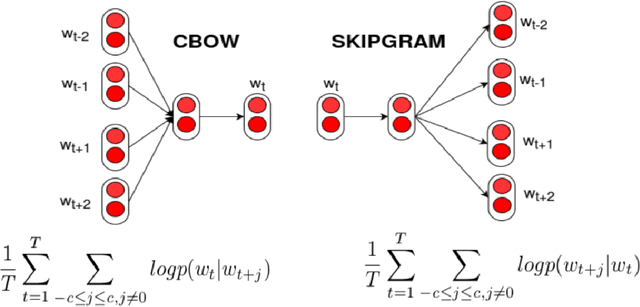

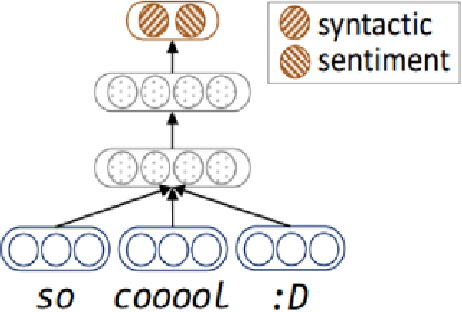
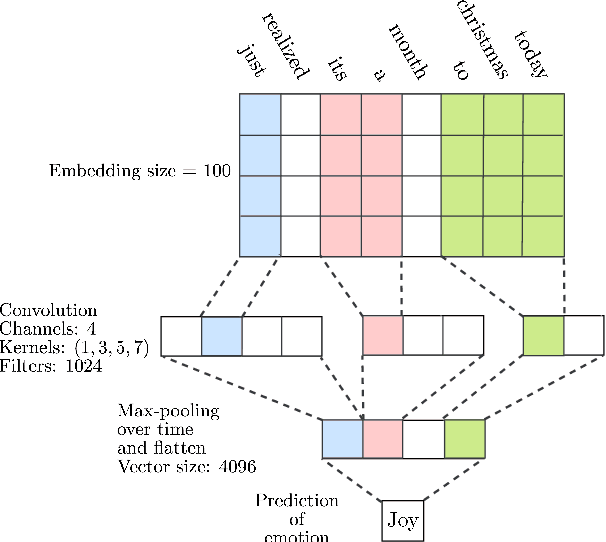
It is important for machines to interpret human emotions properly for better human-machine communications, as emotion is an essential part of human-to-human communications. One aspect of emotion is reflected in the language we use. How to represent emotions in texts is a challenge in natural language processing (NLP). Although continuous vector representations like word2vec have become the new norm for NLP problems, their limitations are that they do not take emotions into consideration and can unintentionally contain bias toward certain identities like different genders. This thesis focuses on improving existing representations in both word and sentence levels by explicitly taking emotions inside text and model bias into account in their training process. Our improved representations can help to build more robust machine learning models for affect-related text classification like sentiment/emotion analysis and abusive language detection. We first propose representations called emotional word vectors (EVEC), which is learned from a convolutional neural network model with an emotion-labeled corpus, which is constructed using hashtags. Secondly, we extend to learning sentence-level representations with a huge corpus of texts with the pseudo task of recognizing emojis. Our results show that, with the representations trained from millions of tweets with weakly supervised labels such as hashtags and emojis, we can solve sentiment/emotion analysis tasks more effectively. Lastly, as examples of model bias in representations of existing approaches, we explore a specific problem of automatic detection of abusive language. We address the issue of gender bias in various neural network models by conducting experiments to measure and reduce those biases in the representations in order to build more robust classification models.
* HKUST MPhil Thesis, 87 pages
Reducing Gender Bias in Abusive Language Detection
Aug 22, 2018

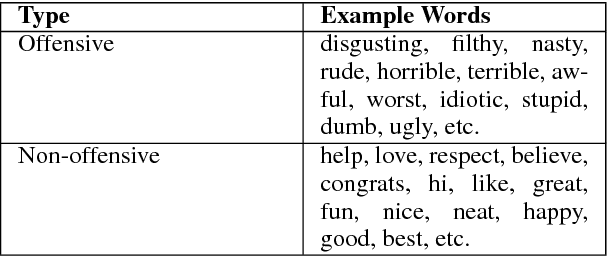
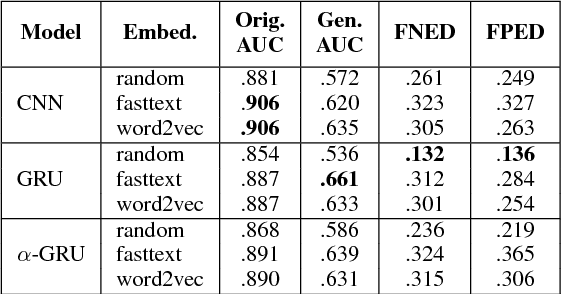
Abusive language detection models tend to have a problem of being biased toward identity words of a certain group of people because of imbalanced training datasets. For example, "You are a good woman" was considered "sexist" when trained on an existing dataset. Such model bias is an obstacle for models to be robust enough for practical use. In this work, we measure gender biases on models trained with different abusive language datasets, while analyzing the effect of different pre-trained word embeddings and model architectures. We also experiment with three bias mitigation methods: (1) debiased word embeddings, (2) gender swap data augmentation, and (3) fine-tuning with a larger corpus. These methods can effectively reduce gender bias by 90-98% and can be extended to correct model bias in other scenarios.
PlusEmo2Vec at SemEval-2018 Task 1: Exploiting emotion knowledge from emoji and #hashtags
Apr 23, 2018


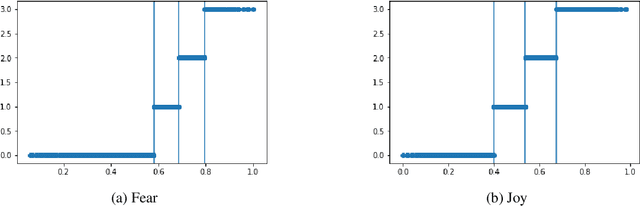
This paper describes our system that has been submitted to SemEval-2018 Task 1: Affect in Tweets (AIT) to solve five subtasks. We focus on modeling both sentence and word level representations of emotion inside texts through large distantly labeled corpora with emojis and hashtags. We transfer the emotional knowledge by exploiting neural network models as feature extractors and use these representations for traditional machine learning models such as support vector regression (SVR) and logistic regression to solve the competition tasks. Our system is placed among the Top3 for all subtasks we participated.
One-step and Two-step Classification for Abusive Language Detection on Twitter
Jun 05, 2017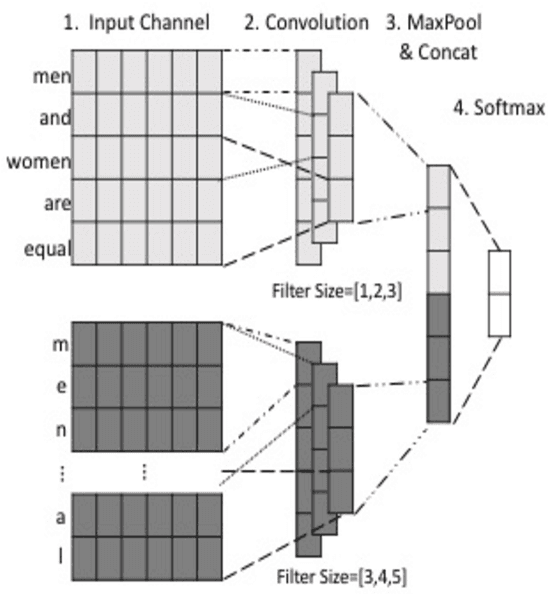

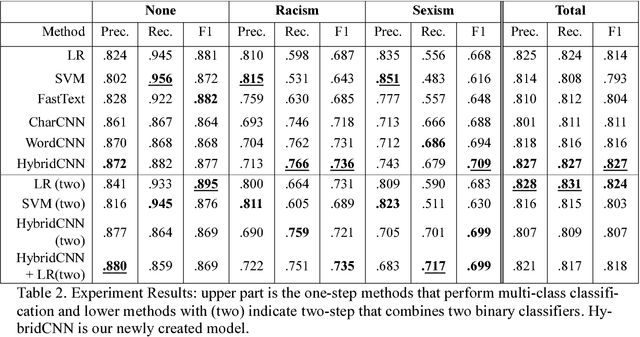
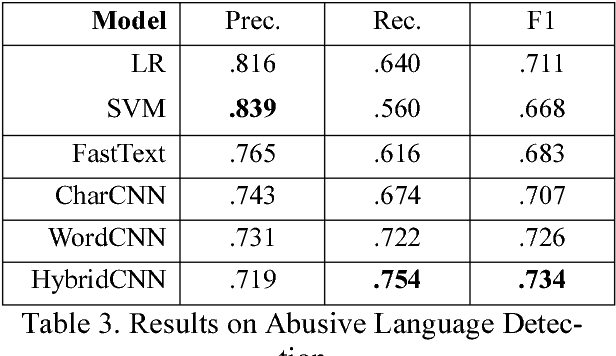
Automatic abusive language detection is a difficult but important task for online social media. Our research explores a two-step approach of performing classification on abusive language and then classifying into specific types and compares it with one-step approach of doing one multi-class classification for detecting sexist and racist languages. With a public English Twitter corpus of 20 thousand tweets in the type of sexism and racism, our approach shows a promising performance of 0.827 F-measure by using HybridCNN in one-step and 0.824 F-measure by using logistic regression in two-steps.