 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf Power: Benchmarking the Energy Efficiency of Machine Learning Systems from μWatts to MWatts for Sustainable AI
Oct 15, 2024



Rapid adoption of machine learning (ML) technologies has led to a surge in power consumption across diverse systems, from tiny IoT devices to massive datacenter clusters. Benchmarking the energy efficiency of these systems is crucial for optimization, but presents novel challenges due to the variety of hardware platforms, workload characteristics, and system-level interactions. This paper introduces MLPerf Power, a comprehensive benchmarking methodology with capabilities to evaluate the energy efficiency of ML systems at power levels ranging from microwatts to megawatts. Developed by a consortium of industry professionals from more than 20 organizations, MLPerf Power establishes rules and best practices to ensure comparability across diverse architectures. We use representative workloads from the MLPerf benchmark suite to collect 1,841 reproducible measurements from 60 systems across the entire range of ML deployment scales. Our analysis reveals trade-offs between performance, complexity, and energy efficiency across this wide range of systems, providing actionable insights for designing optimized ML solutions from the smallest edge devices to the largest cloud infrastructures. This work emphasizes the importance of energy efficiency as a key metric in the evaluation and comparison of the ML system, laying the foundation for future research in this critical area. We discuss the implications for developing sustainable AI solutions and standardizing energy efficiency benchmarking for ML systems.
MLPerf Tiny Benchmark
Jun 28, 2021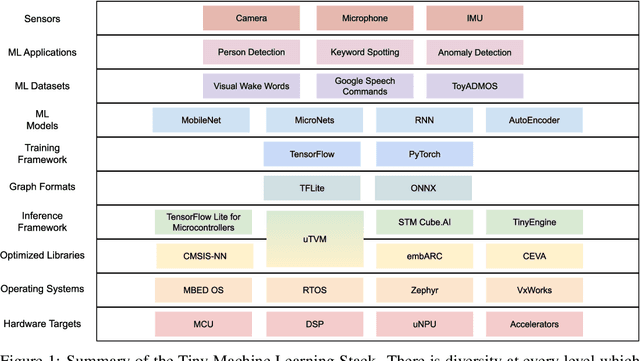
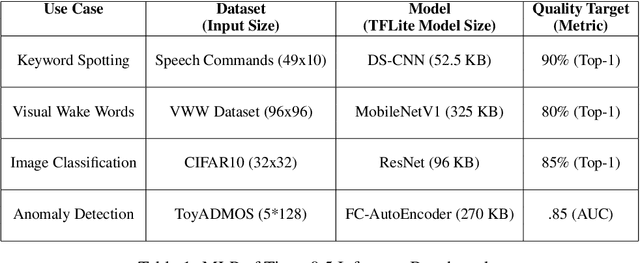
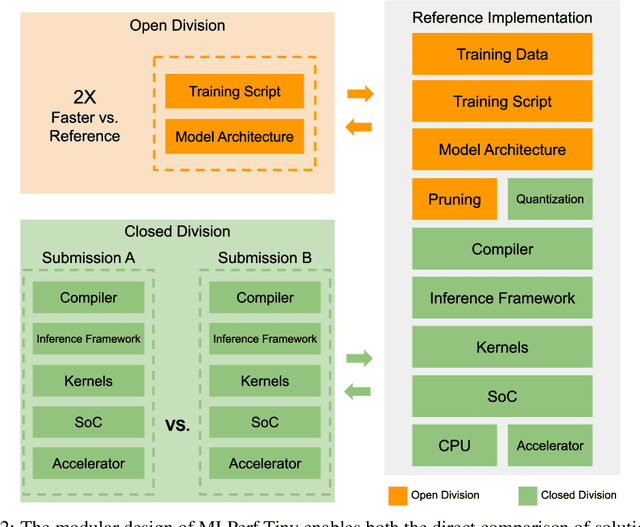
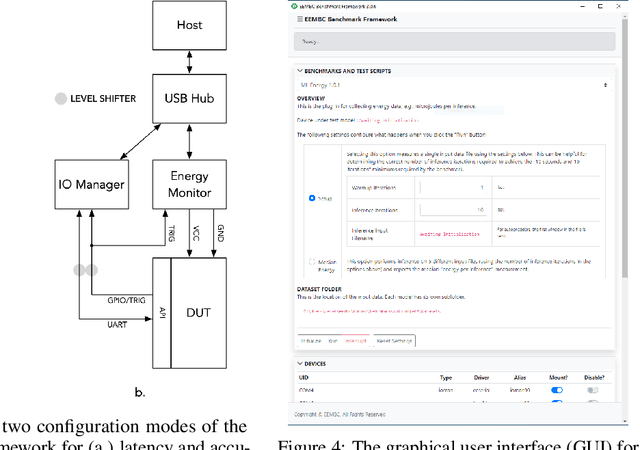
Advancements in ultra-low-power tiny machine learning (TinyML) systems promise to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted and easily reproducible benchmark for these systems. To meet this need, we present MLPerf Tiny, the first industry-standard benchmark suite for ultra-low-power tiny machine learning systems. The benchmark suite is the collaborative effort of more than 50 organizations from industry and academia and reflects the needs of the community. MLPerf Tiny measures the accuracy, latency, and energy of machine learning inference to properly evaluate the tradeoffs between systems. Additionally, MLPerf Tiny implements a modular design that enables benchmark submitters to show the benefits of their product, regardless of where it falls on the ML deployment stack, in a fair and reproducible manner. The suite features four benchmarks: keyword spotting, visual wake words, image classification, and anomaly detection.
Training Neural Networks Using the Property of Negative Feedback to Inverse a Function
Mar 25, 2021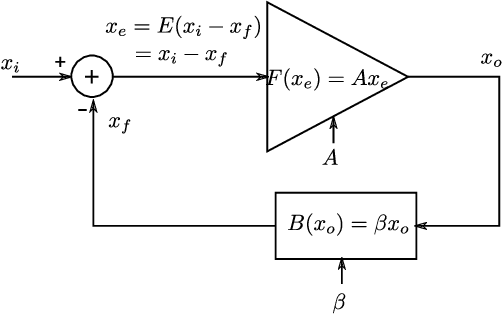
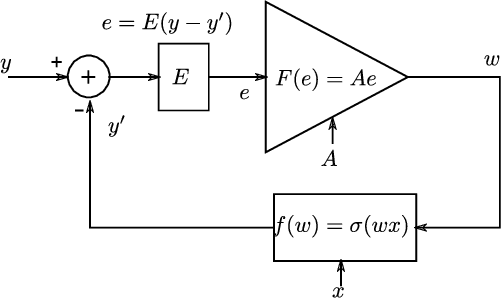
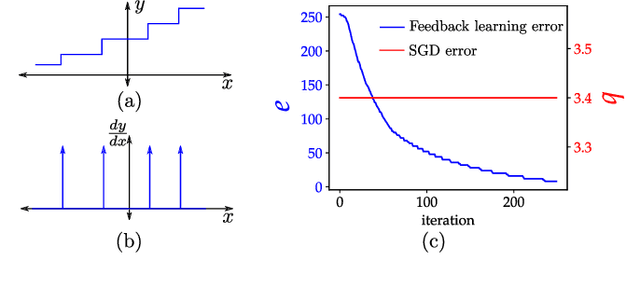
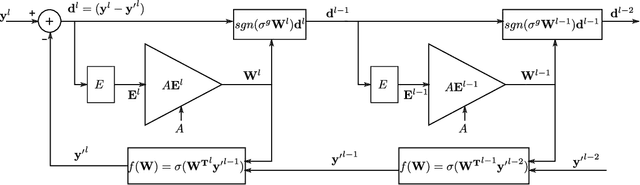
With high forward gain, a negative feedback system has the ability to perform the inverse of a linear or non linear function that is in the feedback path. This property of negative feedback systems has been widely used in analog circuits to construct precise closed-loop functions. This paper describes how the property of a negative feedback system to perform inverse of a function can be used for training neural networks. This method does not require that the cost or activation functions be differentiable. Hence, it is able to learn a class of non-differentiable functions as well where a gradient descent-based method fails. We also show that gradient descent emerges as a special case of the proposed method. We have applied this method to the MNIST dataset and obtained results that shows the method is viable for neural network training. This method, to the best of our knowledge, is novel in machine learning.
Benchmarking TinyML Systems: Challenges and Direction
Mar 10, 2020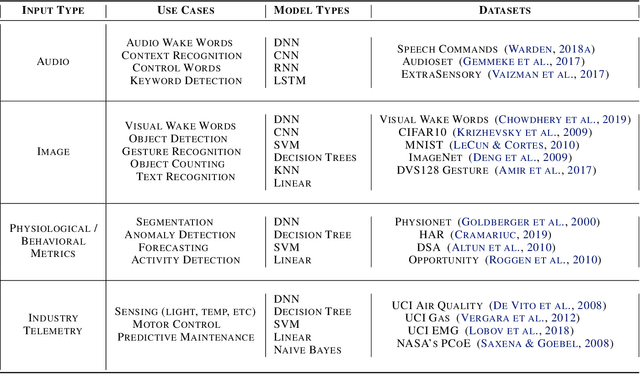
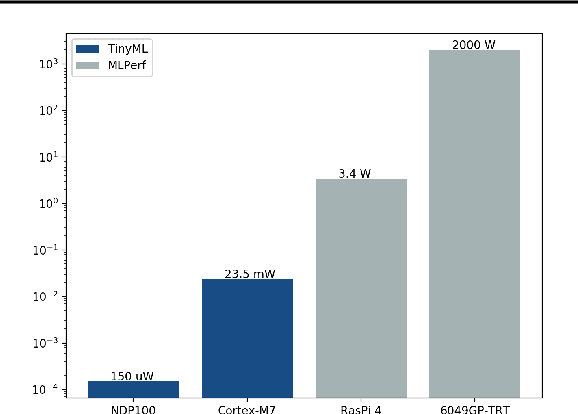
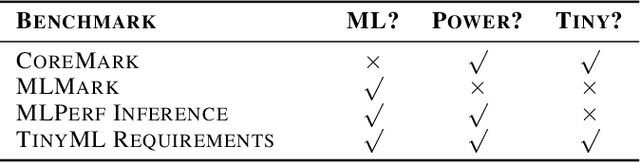
Recent advancements in ultra-low-power machine learning (TinyML) hardware promises to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted benchmark for these systems. Benchmarking allows us to measure and thereby systematically compare, evaluate, and improve the performance of systems. In this position paper, we present the current landscape of TinyML and discuss the challenges and direction towards developing a fair and useful hardware benchmark for TinyML workloads. Our viewpoints reflect the collective thoughts of the TinyMLPerf working group that is comprised of 30 organizations.