 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust the uncertain teacher: distilling dark knowledge via calibrated uncertainty
Feb 13, 2026The core of knowledge distillation lies in transferring the teacher's rich 'dark knowledge'-subtle probabilistic patterns that reveal how classes are related and the distribution of uncertainties. While this idea is well established, teachers trained with conventional cross-entropy often fail to preserve such signals. Their distributions collapse into sharp, overconfident peaks that appear decisive but are in fact brittle, offering little beyond the hard label or subtly hindering representation-level transfer. This overconfidence is especially problematic in high-cardinality tasks, where the nuances among many plausible classes matter most for guiding a compact student. Moreover, such brittle targets reduce robustness under distribution shift, leaving students vulnerable to miscalibration in real-world conditions. To address this limitation, we revisit distillation from a distributional perspective and propose Calibrated Uncertainty Distillation (CUD), a framework designed to make dark knowledge more faithfully accessible. Instead of uncritically adopting the teacher's overconfidence, CUD encourages teachers to reveal uncertainty where it is informative and guides students to learn from targets that are calibrated rather than sharpened certainty. By directly shaping the teacher's predictive distribution before transfer, our approach balances accuracy and calibration, allowing students to benefit from both confident signals on easy cases and structured uncertainty on hard ones. Across diverse benchmarks, CUD yields students that are not only more accurate, but also more calibrated under shift and more reliable on ambiguous, long-tail inputs.
ProgRAG: Hallucination-Resistant Progressive Retrieval and Reasoning over Knowledge Graphs
Nov 13, 2025



Large Language Models (LLMs) demonstrate strong reasoning capabilities but struggle with hallucinations and limited transparency. Recently, KG-enhanced LLMs that integrate knowledge graphs (KGs) have been shown to improve reasoning performance, particularly for complex, knowledge-intensive tasks. However, these methods still face significant challenges, including inaccurate retrieval and reasoning failures, often exacerbated by long input contexts that obscure relevant information or by context constructions that struggle to capture the richer logical directions required by different question types. Furthermore, many of these approaches rely on LLMs to directly retrieve evidence from KGs, and to self-assess the sufficiency of this evidence, which often results in premature or incorrect reasoning. To address the retrieval and reasoning failures, we propose ProgRAG, a multi-hop knowledge graph question answering (KGQA) framework that decomposes complex questions into sub-questions, and progressively extends partial reasoning paths by answering each sub-question. At each step, external retrievers gather candidate evidence, which is then refined through uncertainty-aware pruning by the LLM. Finally, the context for LLM reasoning is optimized by organizing and rearranging the partial reasoning paths obtained from the sub-question answers. Experiments on three well-known datasets demonstrate that ProgRAG outperforms existing baselines in multi-hop KGQA, offering improved reliability and reasoning quality.
Seg&Struct: The Interplay Between Part Segmentation and Structure Inference for 3D Shape Parsing
Nov 01, 2022



We propose Seg&Struct, a supervised learning framework leveraging the interplay between part segmentation and structure inference and demonstrating their synergy in an integrated framework. Both part segmentation and structure inference have been extensively studied in the recent deep learning literature, while the supervisions used for each task have not been fully exploited to assist the other task. Namely, structure inference has been typically conducted with an autoencoder that does not leverage the point-to-part associations. Also, segmentation has been mostly performed without structural priors that tell the plausibility of the output segments. We present how these two tasks can be best combined while fully utilizing supervision to improve performance. Our framework first decomposes a raw input shape into part segments using an off-the-shelf algorithm, whose outputs are then mapped to nodes in a part hierarchy, establishing point-to-part associations. Following this, ours predicts the structural information, e.g., part bounding boxes and part relationships. Lastly, the segmentation is rectified by examining the confusion of part boundaries using the structure-based part features. Our experimental results based on the StructureNet and PartNet demonstrate that the interplay between the two tasks results in remarkable improvements in both tasks: 27.91% in structure inference and 0.5% in segmentation.
Predicting resonant properties of plasmonic structures by deep learning
Apr 19, 2018
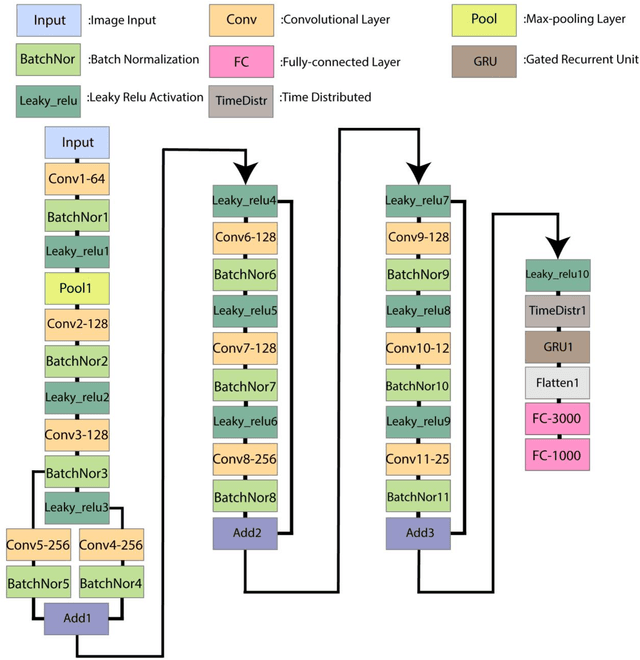
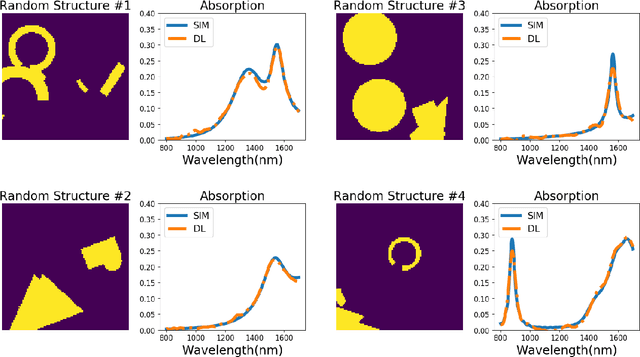
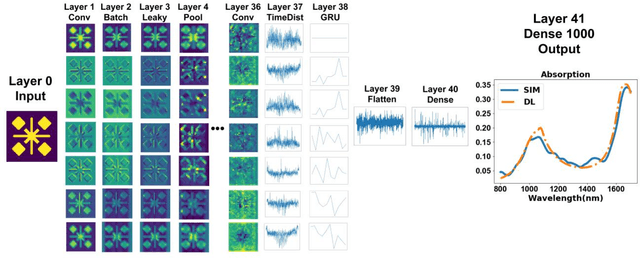
Deep learning can be used to extract meaningful results from images. In this paper, we used convolutional neural networks combined with recurrent neural networks on images of plasmonic structures and extract absorption data form them. To provide the required data for the model we did 100,000 simulations with similar setups and random structures. By designing a deep network we could find a model that could predict the absorption of any structure with similar setup. We used convolutional neural networks to get the spatial information from the images and we used recurrent neural networks to help the model find the relationship between the spatial information obtained from convolutional neural network model. With this design we could reach a very low loss in predicting the absorption compared to the results obtained from numerical simulation in a very short time.