 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sample Complexity of Rank Regression from Pairwise Comparisons
May 04, 2021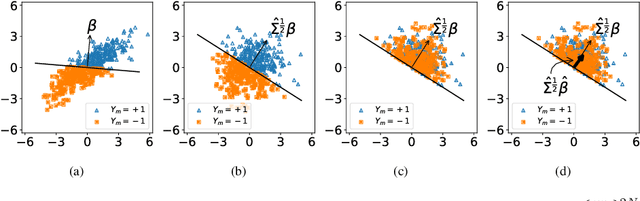

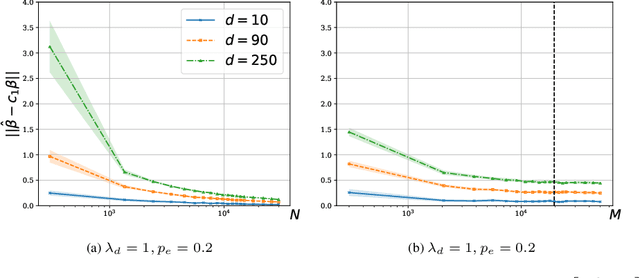
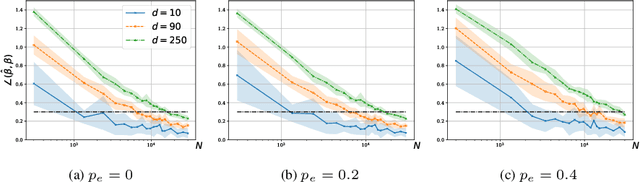
We consider a rank regression setting, in which a dataset of $N$ samples with features in $\mathbb{R}^d$ is ranked by an oracle via $M$ pairwise comparisons. Specifically, there exists a latent total ordering of the samples; when presented with a pair of samples, a noisy oracle identifies the one ranked higher with respect to the underlying total ordering. A learner observes a dataset of such comparisons and wishes to regress sample ranks from their features. We show that to learn the model parameters with $\epsilon > 0$ accuracy, it suffices to conduct $M \in \Omega(dN\log^3 N/\epsilon^2)$ comparisons uniformly at random when $N$ is $\Omega(d/\epsilon^2)$.
Machine Learning on Camera Images for Fast mmWave Beamforming
Feb 15, 2021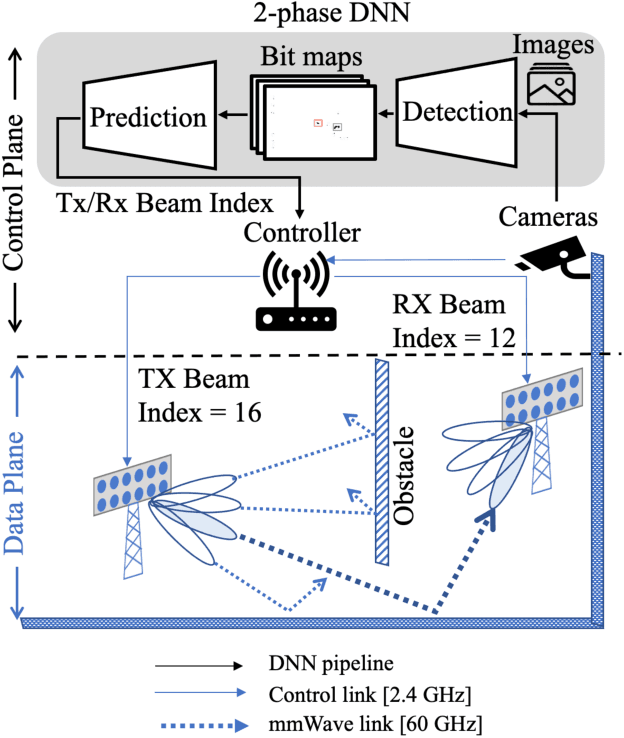
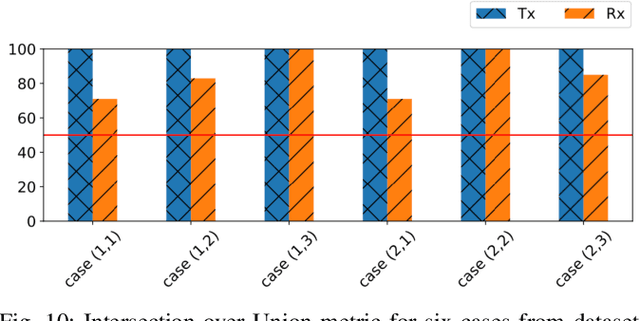
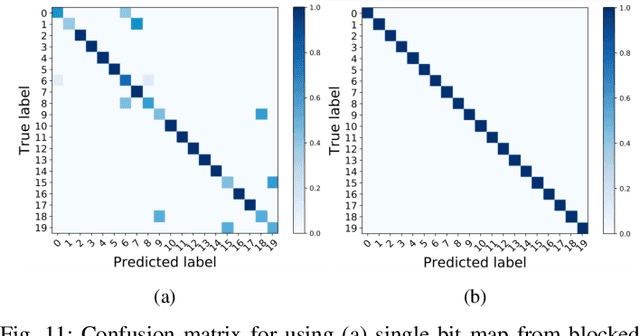
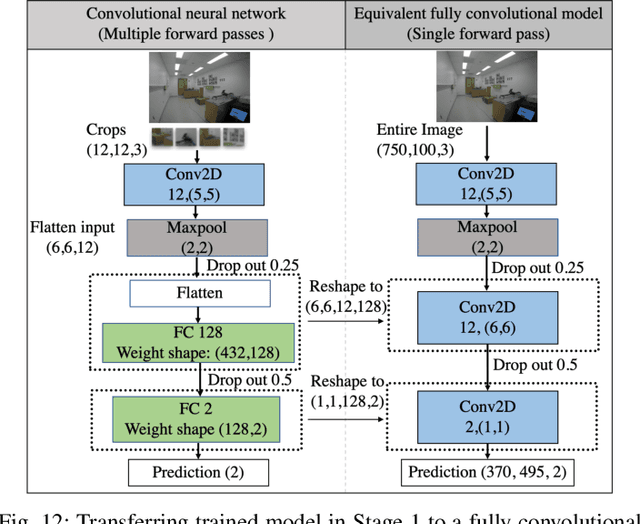
Perfect alignment in chosen beam sectors at both transmit- and receive-nodes is required for beamforming in mmWave bands. Current 802.11ad WiFi and emerging 5G cellular standards spend up to several milliseconds exploring different sector combinations to identify the beam pair with the highest SNR. In this paper, we propose a machine learning (ML) approach with two sequential convolutional neural networks (CNN) that uses out-of-band information, in the form of camera images, to (i) rapidly identify the locations of the transmitter and receiver nodes, and then (ii) return the optimal beam pair. We experimentally validate this intriguing concept for indoor settings using the NI 60GHz mmwave transceiver. Our results reveal that our ML approach reduces beamforming related exploration time by 93% under different ambient lighting conditions, with an error of less than 1% compared to the time-intensive deterministic method defined by the current standards.
Open-World Class Discovery with Kernel Networks
Dec 13, 2020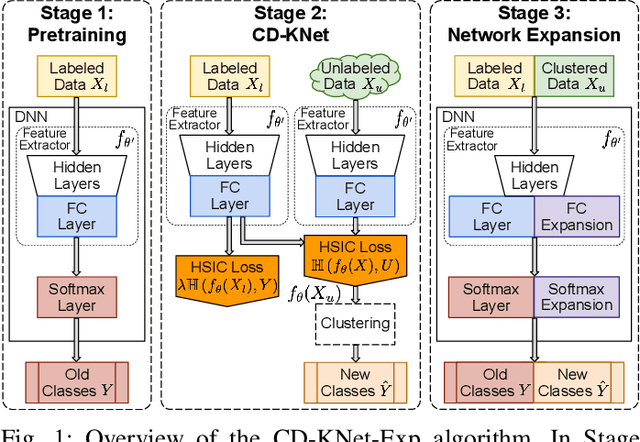


We study an Open-World Class Discovery problem in which, given labeled training samples from old classes, we need to discover new classes from unlabeled test samples. There are two critical challenges to addressing this paradigm: (a) transferring knowledge from old to new classes, and (b) incorporating knowledge learned from new classes back to the original model. We propose Class Discovery Kernel Network with Expansion (CD-KNet-Exp), a deep learning framework, which utilizes the Hilbert Schmidt Independence Criterion to bridge supervised and unsupervised information together in a systematic way, such that the learned knowledge from old classes is distilled appropriately for discovering new classes. Compared to competing methods, CD-KNet-Exp shows superior performance on three publicly available benchmark datasets and a challenging real-world radio frequency fingerprinting dataset.
Learn-Prune-Share for Lifelong Learning
Dec 13, 2020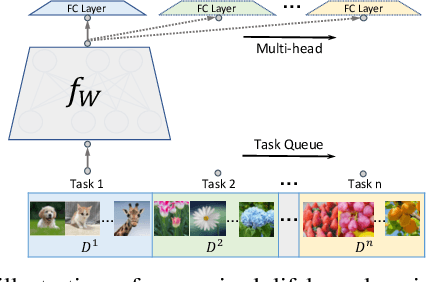
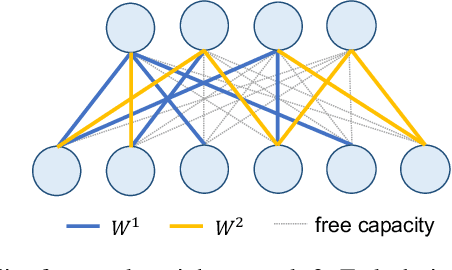
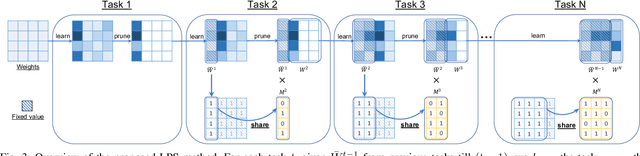
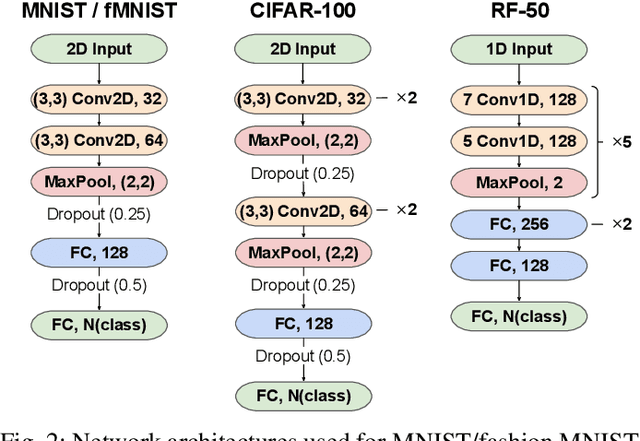
In lifelong learning, we wish to maintain and update a model (e.g., a neural network classifier) in the presence of new classification tasks that arrive sequentially. In this paper, we propose a learn-prune-share (LPS) algorithm which addresses the challenges of catastrophic forgetting, parsimony, and knowledge reuse simultaneously. LPS splits the network into task-specific partitions via an ADMM-based pruning strategy. This leads to no forgetting, while maintaining parsimony. Moreover, LPS integrates a novel selective knowledge sharing scheme into this ADMM optimization framework. This enables adaptive knowledge sharing in an end-to-end fashion. Comprehensive experimental results on two lifelong learning benchmark datasets and a challenging real-world radio frequency fingerprinting dataset are provided to demonstrate the effectiveness of our approach. Our experiments show that LPS consistently outperforms multiple state-of-the-art competitors.
Kernel Dependence Network
Nov 09, 2020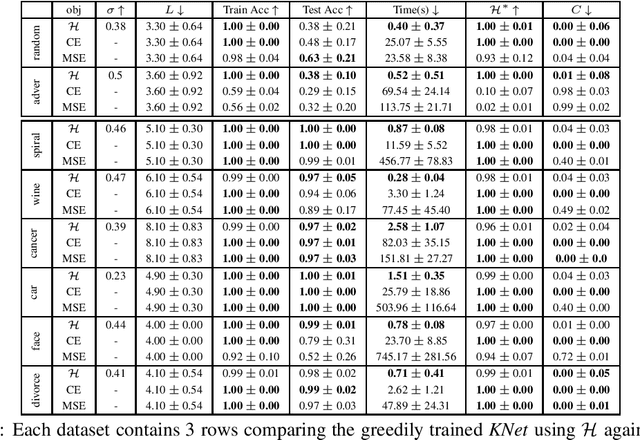
We propose a greedy strategy to spectrally train a deep network for multi-class classification. Each layer is defined as a composition of linear weights with the feature map of a Gaussian kernel acting as the activation function. At each layer, the linear weights are learned by maximizing the dependence between the layer output and the labels using the Hilbert Schmidt Independence Criterion (HSIC). By constraining the solution space on the Stiefel Manifold, we demonstrate how our network construct (Kernel Dependence Network or KNet) can be solved spectrally while leveraging the eigenvalues to automatically find the width and the depth of the network. We theoretically guarantee the existence of a solution for the global optimum while providing insight into our network's ability to generalize.
* arXiv admin note: substantial text overlap with arXiv:2006.08539
Layer-wise Learning of Kernel Dependence Networks
Jun 15, 2020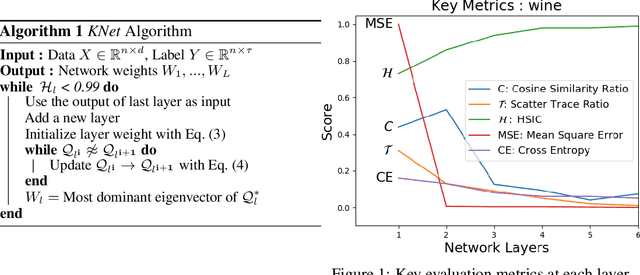
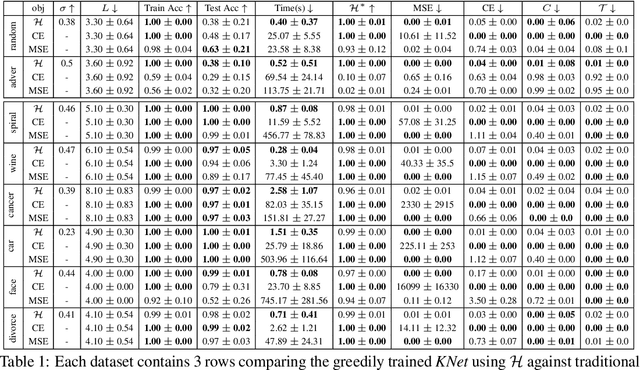
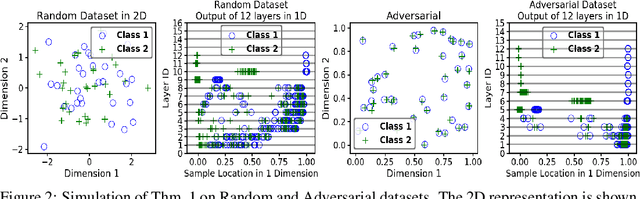
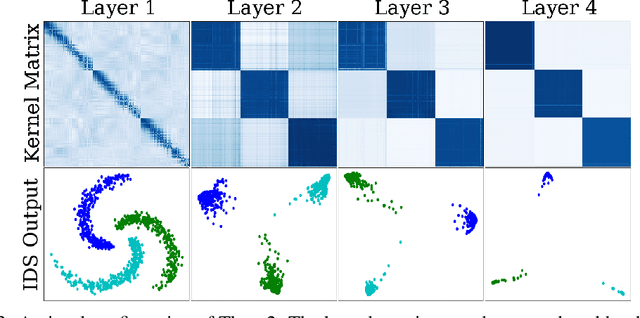
We propose a greedy strategy to train a deep network for multi-class classification, where each layer is defined as a composition of a linear projection and a nonlinear mapping. This nonlinear mapping is defined as the feature map of a Gaussian kernel, and the linear projection is learned by maximizing the dependence between the layer output and the labels, using the Hilbert Schmidt Independence Criterion (HSIC) as the dependence measure. Since each layer is trained greedily in sequence, all learning is local, and neither backpropagation nor even gradient descent is needed. The depth and width of the network are determined via natural guidelines, and the procedure regularizes its weights in the linear layer. As the key theoretical result, the function class represented by the network is proved to be sufficiently rich to learn any dataset labeling using a finite number of layers, in the sense of reaching minimum mean-squared error or cross-entropy, as long as no two data points with different labels coincide. Experiments demonstrate good generalization performance of the greedy approach across multiple benchmarks while showing a significant computational advantage against a multilayer perceptron of the same complexity trained globally by backpropagation.
Deep Markov Spatio-Temporal Factorization
Mar 22, 2020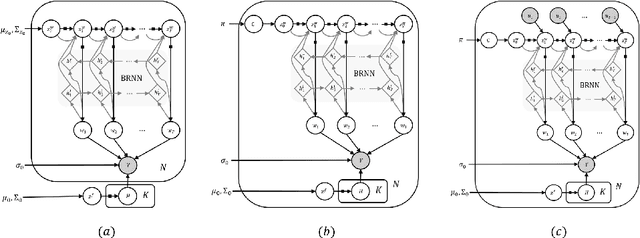

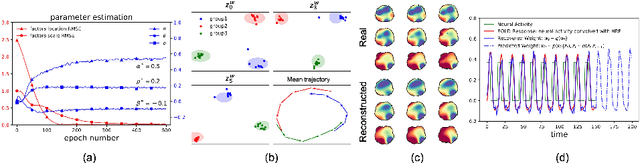

We introduce deep Markov spatio-temporal factorization (DMSTF), a deep generative model for spatio-temporal data. Like other factor analysis methods, DMSTF approximates high-dimensional data by a product between time-dependent weights and spatially dependent factors. These weights and factors are in turn represented in terms of lower-dimensional latent variables that we infer using stochastic variational inference. The innovation in DMSTF is that we parameterize weights in terms of a deep Markovian prior, which is able to characterize nonlinear temporal dynamics. We parameterize the corresponding variational distribution using a bidirectional recurrent network. This results in a flexible family of hierarchical deep generative factor analysis models that can be extended to perform time series clustering, or perform factor analysis in the presence of a control signal. Our experiments, which consider simulated data, fMRI data, and traffic data, demonstrate that DMSTF outperforms related methods in terms of reconstruction accuracy and can perform forecasting in a variety domains with nonlinear temporal transitions.
Weighting Is Worth the Wait: Bayesian Optimization with Importance Sampling
Feb 23, 2020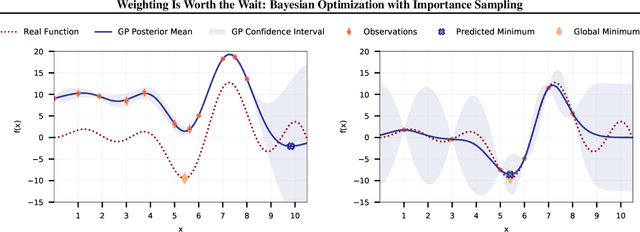
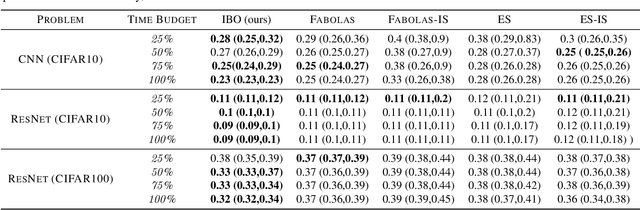
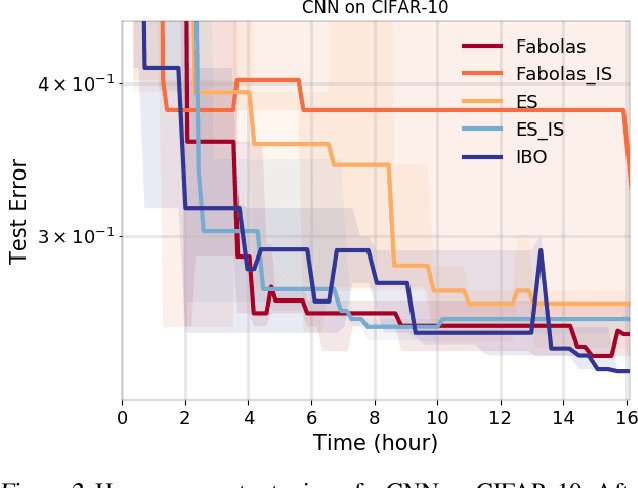
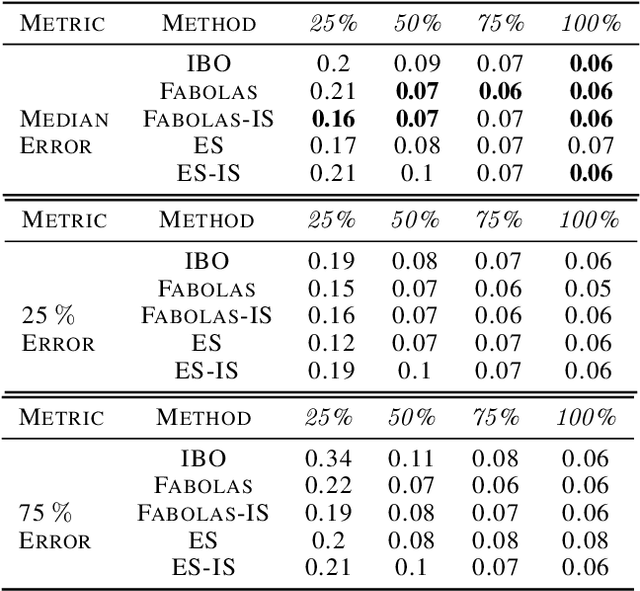
Many contemporary machine learning models require extensive tuning of hyperparameters to perform well. A variety of methods, such as Bayesian optimization, have been developed to automate and expedite this process. However, tuning remains extremely costly as it typically requires repeatedly fully training models. We propose to accelerate the Bayesian optimization approach to hyperparameter tuning for neural networks by taking into account the relative amount of information contributed by each training example. To do so, we leverage importance sampling (IS); this significantly increases the quality of the black-box function evaluations, but also their runtime, and so must be done carefully. Casting hyperparameter search as a multi-task Bayesian optimization problem over both hyperparameters and importance sampling design achieves the best of both worlds: by learning a parameterization of IS that trades-off evaluation complexity and quality, we improve upon Bayesian optimization state-of-the-art runtime and final validation error across a variety of datasets and complex neural architectures.
Segmentation of Cellular Patterns in Confocal Images of Melanocytic Lesions in vivo via a Multiscale Encoder-Decoder Network (MED-Net)
Jan 03, 2020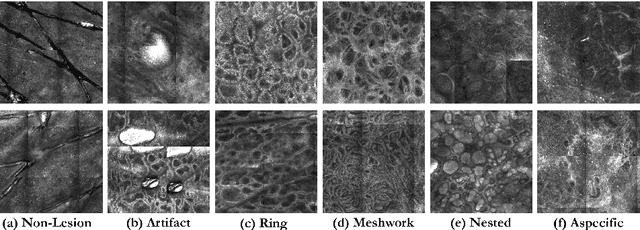
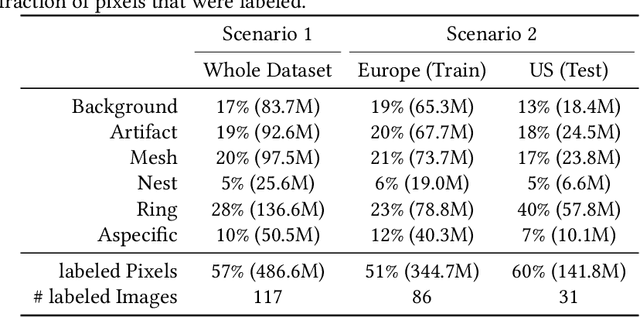
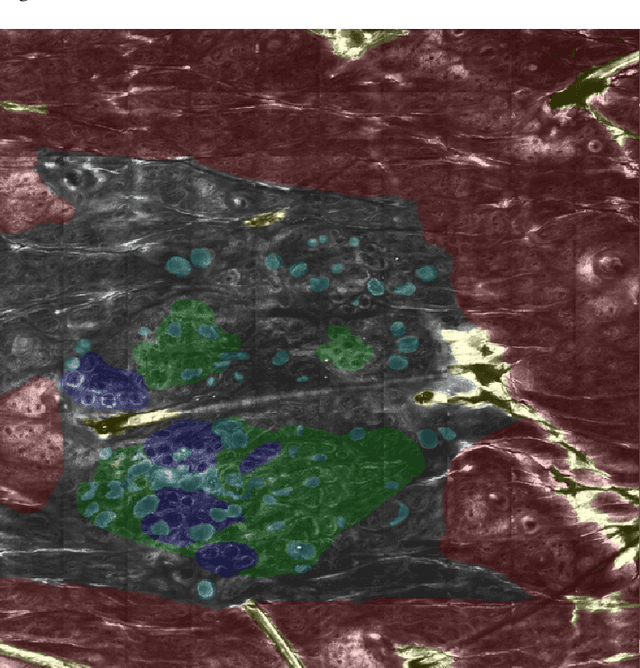
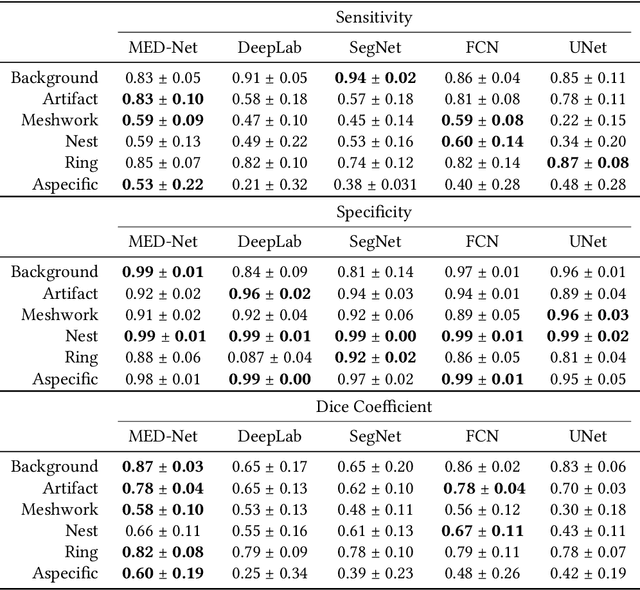
In-vivo optical microscopy is advancing into routine clinical practice for non-invasively guiding diagnosis and treatment of cancer and other diseases, and thus beginning to reduce the need for traditional biopsy. However, reading and analysis of the optical microscopic images are generally still qualitative, relying mainly on visual examination. Here we present an automated semantic segmentation method called "Multiscale Encoder-Decoder Network (MED-Net)" that provides pixel-wise labeling into classes of patterns in a quantitative manner. The novelty in our approach is the modeling of textural patterns at multiple scales. This mimics the procedure for examining pathology images, which routinely starts with low magnification (low resolution, large field of view) followed by closer inspection of suspicious areas with higher magnification (higher resolution, smaller fields of view). We trained and tested our model on non-overlapping partitions of 117 reflectance confocal microscopy (RCM) mosaics of melanocytic lesions, an extensive dataset for this application, collected at four clinics in the US, and two in Italy. With patient-wise cross-validation, we achieved pixel-wise mean sensitivity and specificity of $70\pm11\%$ and $95\pm2\%$, respectively, with $0.71\pm0.09$ Dice coefficient over six classes. In the scenario, we partitioned the data clinic-wise and tested the generalizability of the model over multiple clinics. In this setting, we achieved pixel-wise mean sensitivity and specificity of $74\%$ and $95\%$, respectively, with $0.75$ Dice coefficient. We compared MED-Net against the state-of-the-art semantic segmentation models and achieved better quantitative segmentation performance. Our results also suggest that, due to its nested multiscale architecture, the MED-Net model annotated RCM mosaics more coherently, avoiding unrealistic-fragmented annotations.
Solving Interpretable Kernel Dimension Reduction
Sep 25, 2019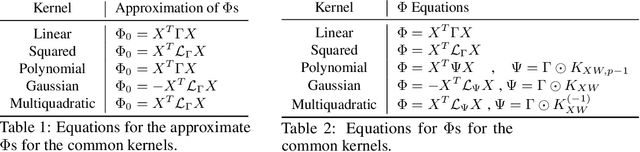

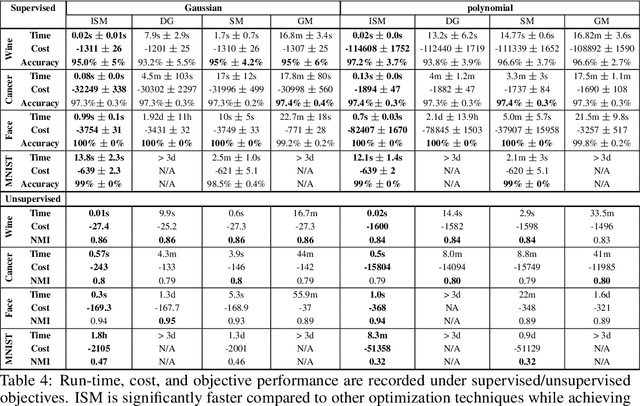
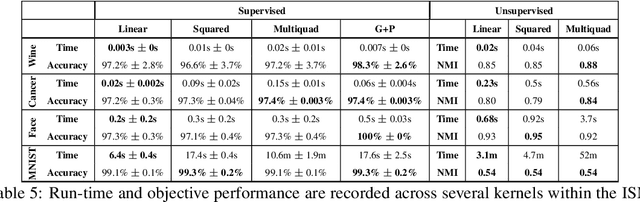
Kernel dimensionality reduction (KDR) algorithms find a low dimensional representation of the original data by optimizing kernel dependency measures that are capable of capturing nonlinear relationships. The standard strategy is to first map the data into a high dimensional feature space using kernels prior to a projection onto a low dimensional space. While KDR methods can be easily solved by keeping the most dominant eigenvectors of the kernel matrix, its features are no longer easy to interpret. Alternatively, Interpretable KDR (IKDR) is different in that it projects onto a subspace \textit{before} the kernel feature mapping, therefore, the projection matrix can indicate how the original features linearly combine to form the new features. Unfortunately, the IKDR objective requires a non-convex manifold optimization that is difficult to solve and can no longer be solved by eigendecomposition. Recently, an efficient iterative spectral (eigendecomposition) method (ISM) has been proposed for this objective in the context of alternative clustering. However, ISM only provides theoretical guarantees for the Gaussian kernel. This greatly constrains ISM's usage since any kernel method using ISM is now limited to a single kernel. This work extends the theoretical guarantees of ISM to an entire family of kernels, thereby empowering ISM to solve any kernel method of the same objective. In identifying this family, we prove that each kernel within the family has a surrogate $\Phi$ matrix and the optimal projection is formed by its most dominant eigenvectors. With this extension, we establish how a wide range of IKDR applications across different learning paradigms can be solved by ISM. To support reproducible results, the source code is made publicly available on \url{https://github.com/chieh-neu/ISM_supervised_DR}.