 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJekaterina Novikova
Impact of Acoustic Noise on Alzheimer's Disease Detection from Speech: Should You Let Baby Cry?
Mar 31, 2022
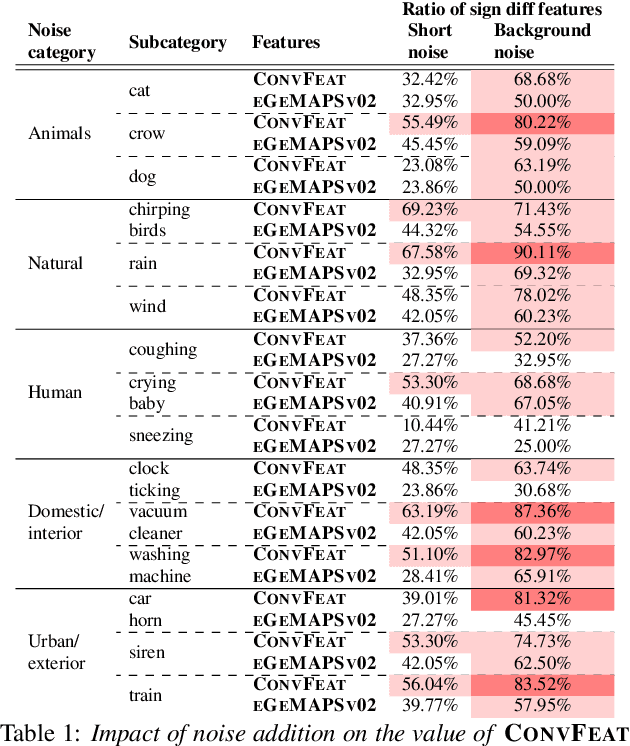
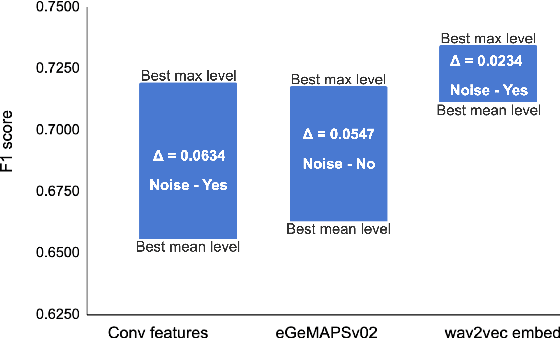
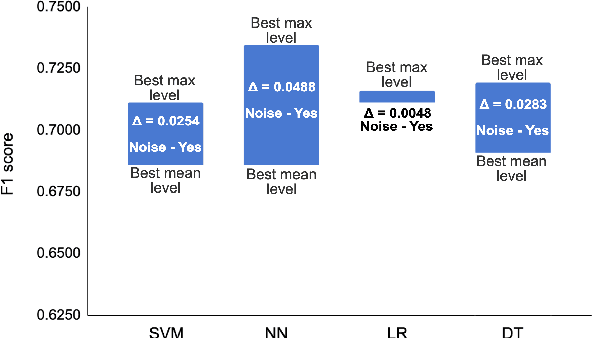
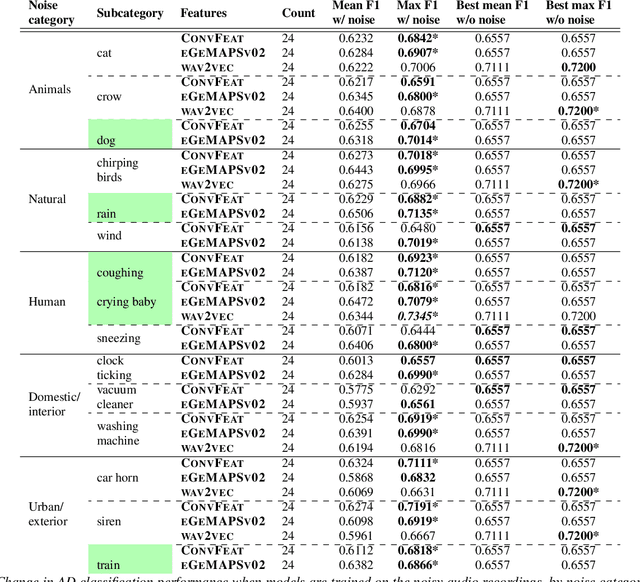
Research related to automatically detecting Alzheimer's disease (AD) is important, given the high prevalence of AD and the high cost of traditional methods. Since AD significantly affects the acoustics of spontaneous speech, speech processing and machine learning (ML) provide promising techniques for reliably detecting AD. However, speech audio may be affected by different types of background noise and it is important to understand how the noise influences the accuracy of ML models detecting AD from speech. In this paper, we study the effect of fifteen types of noise from five different categories on the performance of four ML models trained with three types of acoustic representations. We perform a thorough analysis showing how ML models and acoustic features are affected by different types of acoustic noise. We show that acoustic noise is not necessarily harmful - certain types of noise are beneficial for AD detection models and help increasing accuracy by up to 4.8\%. We provide recommendations on how to utilize acoustic noise in order to achieve the best performance results with the ML models deployed in real world.
Robustness and Sensitivity of BERT Models Predicting Alzheimer's Disease from Text
Sep 24, 2021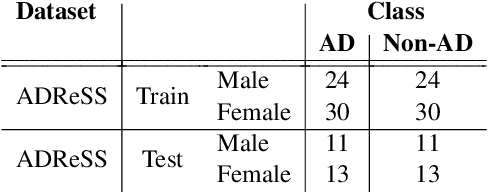
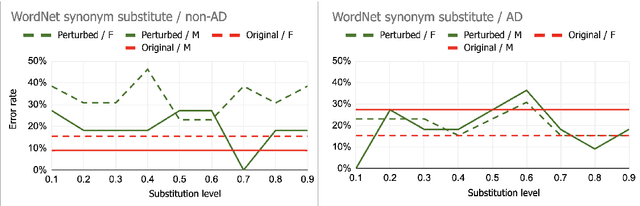
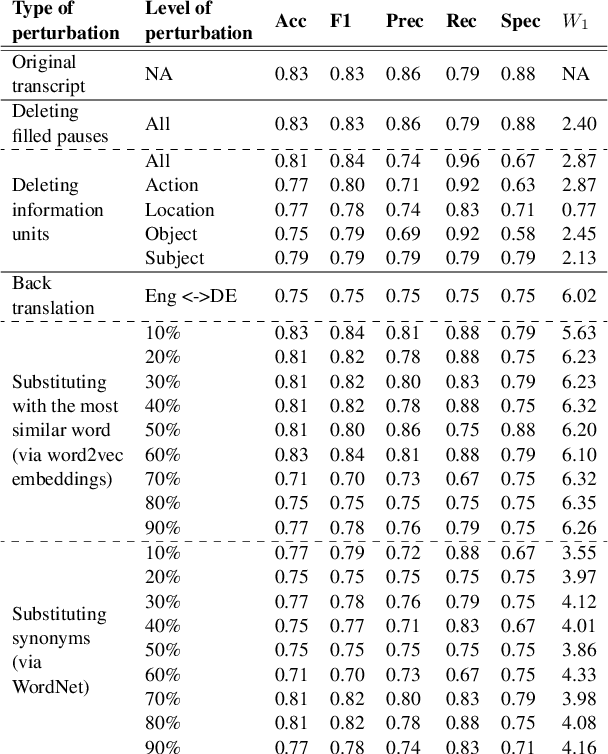
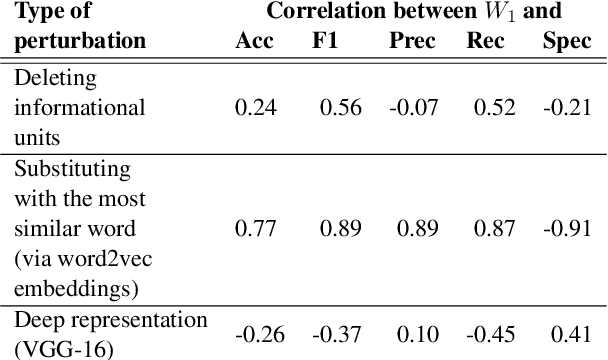
Understanding robustness and sensitivity of BERT models predicting Alzheimer's disease from text is important for both developing better classification models and for understanding their capabilities and limitations. In this paper, we analyze how a controlled amount of desired and undesired text alterations impacts performance of BERT. We show that BERT is robust to natural linguistic variations in text. On the other hand, we show that BERT is not sensitive to removing clinically important information from text.
Comparing Acoustic-based Approaches for Alzheimer's Disease Detection
Jun 03, 2021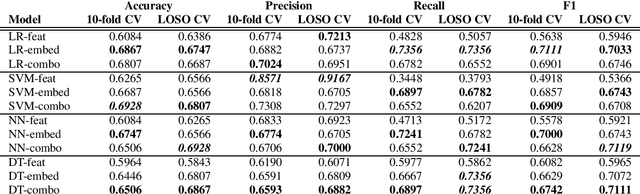
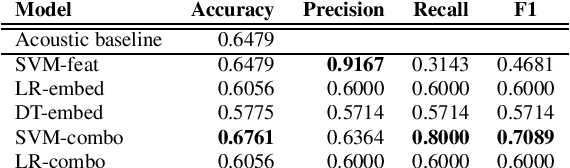

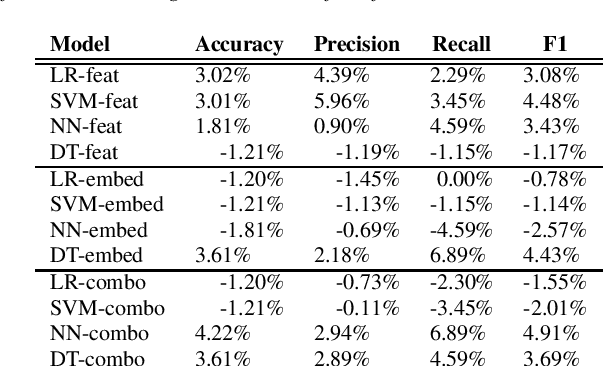
In this paper, we study the performance and generalizability of three approaches for AD detection from speech on the recent ADReSSo challenge dataset: 1) using conventional acoustic features 2) using novel pre-trained acoustic embeddings 3) combining acoustic features and embeddings. We find that while feature-based approaches have a higher precision, classification approaches relying on the combination of embeddings and features prove to have a higher, and more balanced performance across multiple metrics of performance. Our best model, using such a combined approach, outperforms the acoustic baseline in the challenge by 2.8\%.
Augmenting BERT Carefully with Underrepresented Linguistic Features
Nov 12, 2020
Fine-tuned Bidirectional Encoder Representations from Transformers (BERT)-based sequence classification models have proven to be effective for detecting Alzheimer's Disease (AD) from transcripts of human speech. However, previous research shows it is possible to improve BERT's performance on various tasks by augmenting the model with additional information. In this work, we use probing tasks as introspection techniques to identify linguistic information not well-represented in various layers of BERT, but important for the AD detection task. We supplement these linguistic features in which representations from BERT are found to be insufficient with hand-crafted features externally, and show that jointly fine-tuning BERT in combination with these features improves the performance of AD classification by upto 5\% over fine-tuned BERT alone.
Fantastic Features and Where to Find Them: Detecting Cognitive Impairment with a Subsequence Classification Guided Approach
Oct 13, 2020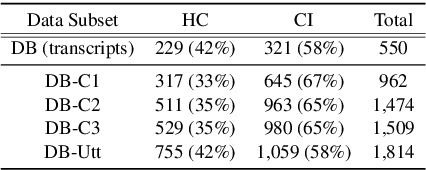

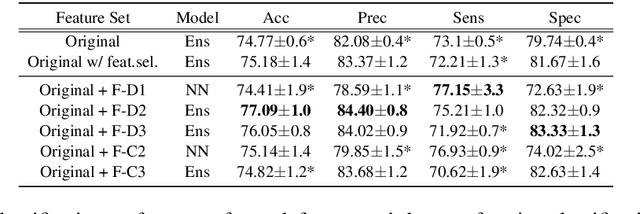

Despite the widely reported success of embedding-based machine learning methods on natural language processing tasks, the use of more easily interpreted engineered features remains common in fields such as cognitive impairment (CI) detection. Manually engineering features from noisy text is time and resource consuming, and can potentially result in features that do not enhance model performance. To combat this, we describe a new approach to feature engineering that leverages sequential machine learning models and domain knowledge to predict which features help enhance performance. We provide a concrete example of this method on a standard data set of CI speech and demonstrate that CI classification accuracy improves by 2.3% over a strong baseline when using features produced by this method. This demonstration provides an ex-ample of how this method can be used to assist classification in fields where interpretability is important, such as health care.
To BERT or Not To BERT: Comparing Speech and Language-based Approaches for Alzheimer's Disease Detection
Jul 26, 2020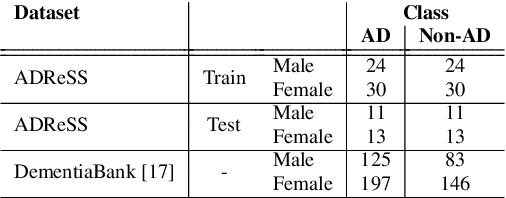

Research related to automatically detecting Alzheimer's disease (AD) is important, given the high prevalence of AD and the high cost of traditional methods. Since AD significantly affects the content and acoustics of spontaneous speech, natural language processing and machine learning provide promising techniques for reliably detecting AD. We compare and contrast the performance of two such approaches for AD detection on the recent ADReSS challenge dataset: 1) using domain knowledge-based hand-crafted features that capture linguistic and acoustic phenomena, and 2) fine-tuning Bidirectional Encoder Representations from Transformer (BERT)-based sequence classification models. We also compare multiple feature-based regression models for a neuropsychological score task in the challenge. We observe that fine-tuned BERT models, given the relative importance of linguistics in cognitive impairment detection, outperform feature-based approaches on the AD detection task.
Cross-Language Aphasia Detection using Optimal Transport Domain Adaptation
Dec 04, 2019
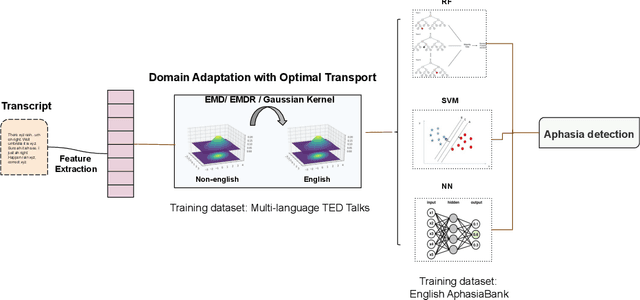
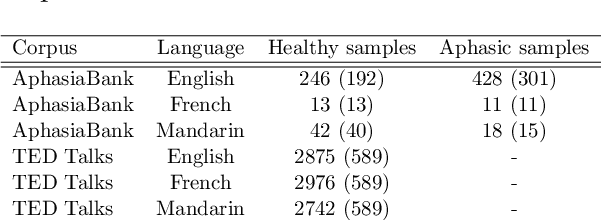
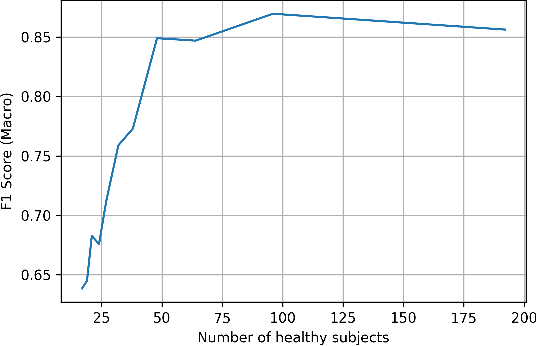
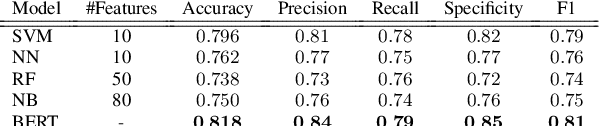
Multi-language speech datasets are scarce and often have small sample sizes in the medical domain. Robust transfer of linguistic features across languages could improve rates of early diagnosis and therapy for speakers of low-resource languages when detecting health conditions from speech. We utilize out-of-domain, unpaired, single-speaker, healthy speech data for training multiple Optimal Transport (OT) domain adaptation systems. We learn mappings from other languages to English and detect aphasia from linguistic characteristics of speech, and show that OT domain adaptation improves aphasia detection over unilingual baselines for French (6% increased F1) and Mandarin (5% increased F1). Further, we show that adding aphasic data to the domain adaptation system significantly increases performance for both French and Mandarin, increasing the F1 scores further (10% and 8% increase in F1 scores for French and Mandarin, respectively, over unilingual baselines).
Lexical Features Are More Vulnerable, Syntactic Features Have More Predictive Power
Sep 30, 2019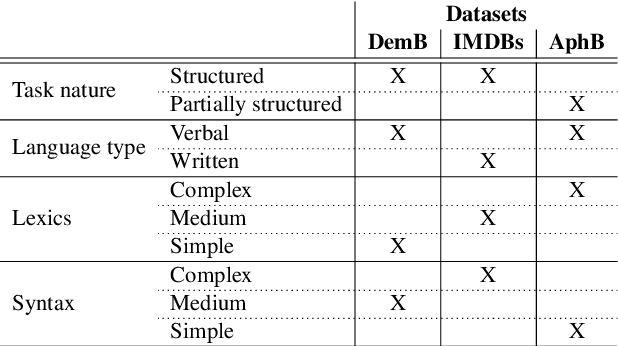
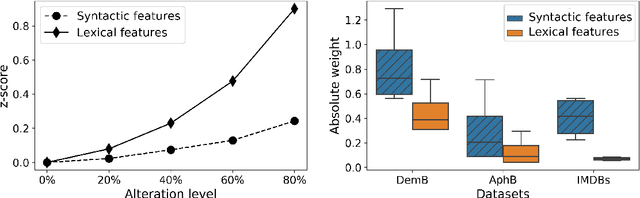
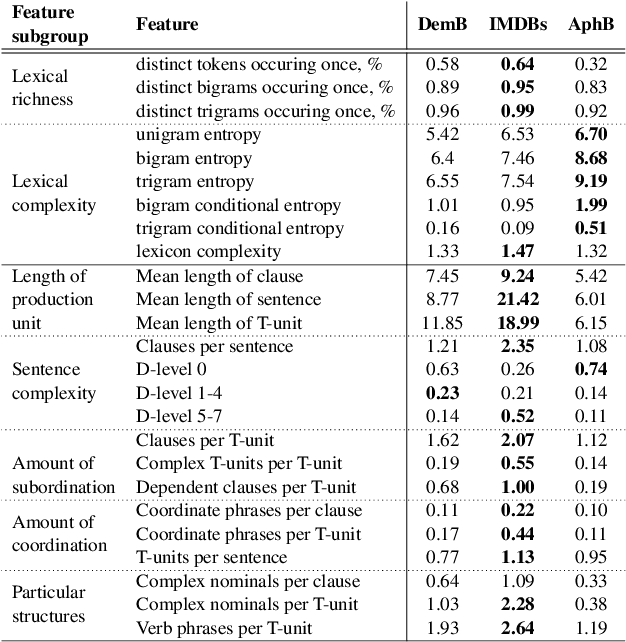
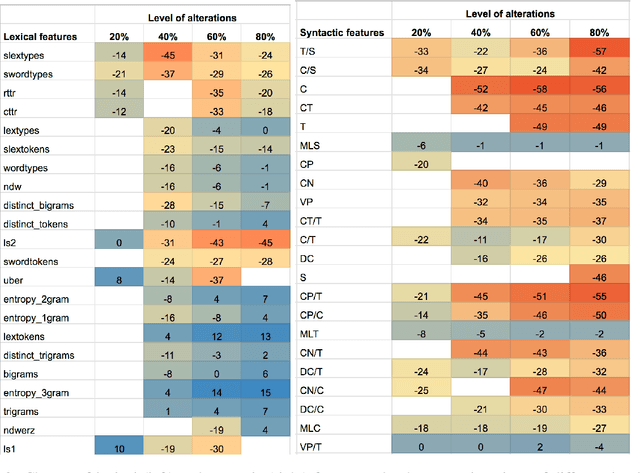
Understanding the vulnerability of linguistic features extracted from noisy text is important for both developing better health text classification models and for interpreting vulnerabilities of natural language models. In this paper, we investigate how generic language characteristics, such as syntax or the lexicon, are impacted by artificial text alterations. The vulnerability of features is analysed from two perspectives: (1) the level of feature value change, and (2) the level of change of feature predictive power as a result of text modifications. We show that lexical features are more sensitive to text modifications than syntactic ones. However, we also demonstrate that these smaller changes of syntactic features have a stronger influence on classification performance downstream, compared to the impact of changes to lexical features. Results are validated across three datasets representing different text-classification tasks, with different levels of lexical and syntactic complexity of both conversational and written language.
Variations on the Chebyshev-Lagrange Activation Function
Jun 24, 2019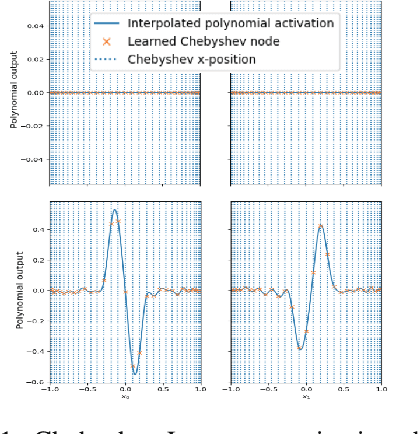
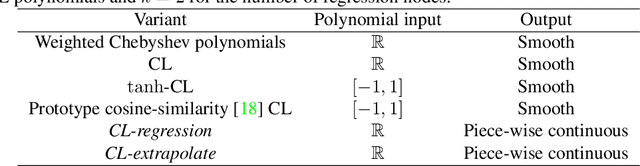
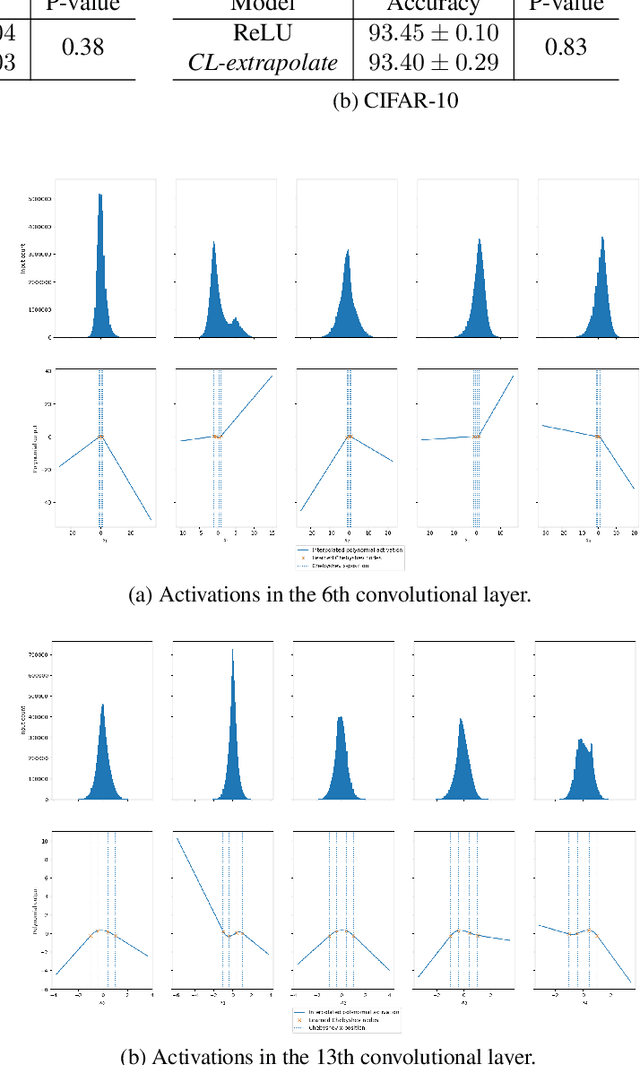

We seek to improve the data efficiency of neural networks and present novel implementations of parameterized piece-wise polynomial activation functions. The parameters are the y-coordinates of n+1 Chebyshev nodes per hidden unit and Lagrangian interpolation between the nodes produces the polynomial on [-1, 1]. We show results for different methods of handling inputs outside [-1, 1] on synthetic datasets, finding significant improvements in capacity of expression and accuracy of interpolation in models that compute some form of linear extrapolation from either ends. We demonstrate competitive or state-of-the-art performance on the classification of images (MNIST and CIFAR-10) and minimally-correlated vectors (DementiaBank) when we replace ReLU or tanh with linearly extrapolated Chebyshev-Lagrange activations in deep residual architectures.
Impact of ASR on Alzheimer's Disease Detection: All Errors are Equal, but Deletions are More Equal than Others
Apr 08, 2019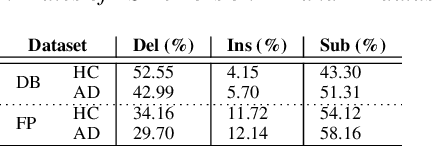
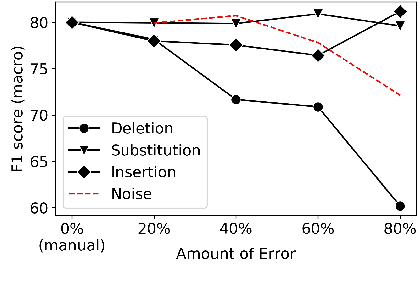
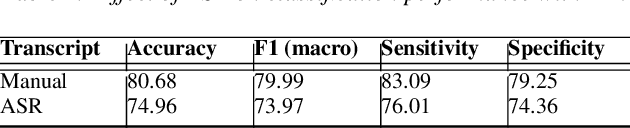
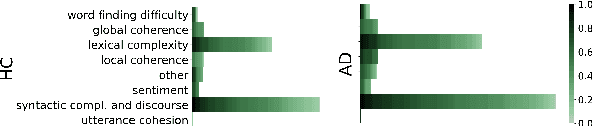
Automatic Speech Recognition (ASR) is a critical component of any fully-automated speech-based Alzheimer's disease (AD) detection model. However, despite years of speech recognition research, little is known about the impact of ASR performance on AD detection. In this paper, we experiment with controlled amounts of artificially generated ASR errors and investigate their influence on AD detection. We find that deletion errors affect AD detection performance the most, due to their impact on the features of syntactic complexity and discourse representation in speech. We show the trend to be generalisable across two different datasets and two different speech-related tasks. As a conclusion, we propose changing the ASR optimization functions to reflect a higher penalty for deletion errors when using ASR for AD detection.