 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergy and Symmetry in Deep Learning: Interactions between the Data, Model, and Inference Algorithm
Jul 11, 2022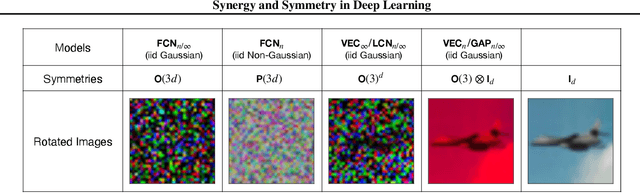
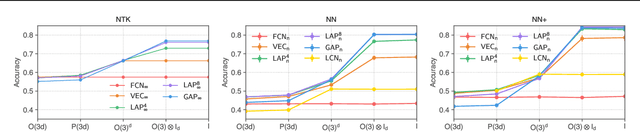
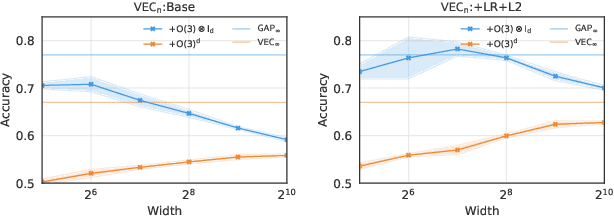
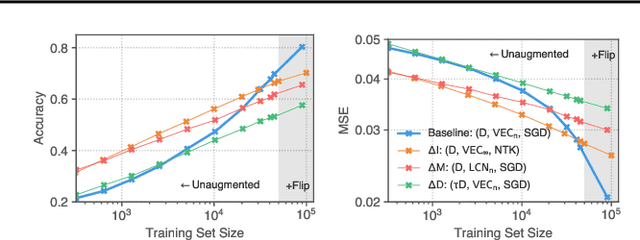
Although learning in high dimensions is commonly believed to suffer from the curse of dimensionality, modern machine learning methods often exhibit an astonishing power to tackle a wide range of challenging real-world learning problems without using abundant amounts of data. How exactly these methods break this curse remains a fundamental open question in the theory of deep learning. While previous efforts have investigated this question by studying the data (D), model (M), and inference algorithm (I) as independent modules, in this paper, we analyze the triplet (D, M, I) as an integrated system and identify important synergies that help mitigate the curse of dimensionality. We first study the basic symmetries associated with various learning algorithms (M, I), focusing on four prototypical architectures in deep learning: fully-connected networks (FCN), locally-connected networks (LCN), and convolutional networks with and without pooling (GAP/VEC). We find that learning is most efficient when these symmetries are compatible with those of the data distribution and that performance significantly deteriorates when any member of the (D, M, I) triplet is inconsistent or suboptimal.
Wide Bayesian neural networks have a simple weight posterior: theory and accelerated sampling
Jun 15, 2022

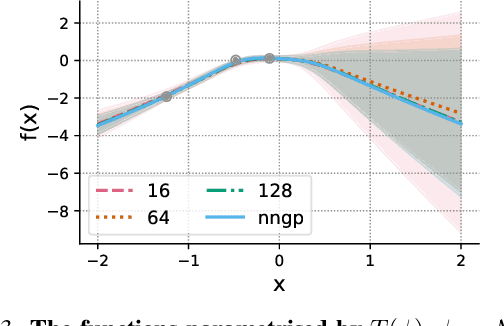
We introduce repriorisation, a data-dependent reparameterisation which transforms a Bayesian neural network (BNN) posterior to a distribution whose KL divergence to the BNN prior vanishes as layer widths grow. The repriorisation map acts directly on parameters, and its analytic simplicity complements the known neural network Gaussian process (NNGP) behaviour of wide BNNs in function space. Exploiting the repriorisation, we develop a Markov chain Monte Carlo (MCMC) posterior sampling algorithm which mixes faster the wider the BNN. This contrasts with the typically poor performance of MCMC in high dimensions. We observe up to 50x higher effective sample size relative to no reparametrisation for both fully-connected and residual networks. Improvements are achieved at all widths, with the margin between reparametrised and standard BNNs growing with layer width.
Implicit Regularization or Implicit Conditioning? Exact Risk Trajectories of SGD in High Dimensions
Jun 15, 2022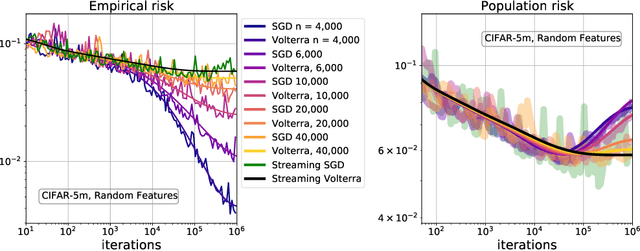
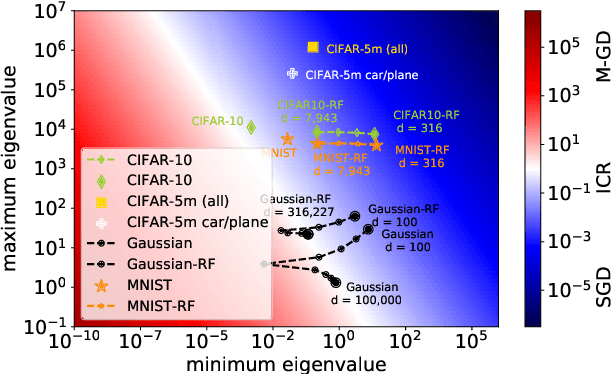
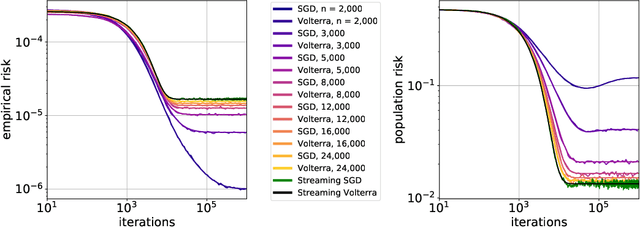
Stochastic gradient descent (SGD) is a pillar of modern machine learning, serving as the go-to optimization algorithm for a diverse array of problems. While the empirical success of SGD is often attributed to its computational efficiency and favorable generalization behavior, neither effect is well understood and disentangling them remains an open problem. Even in the simple setting of convex quadratic problems, worst-case analyses give an asymptotic convergence rate for SGD that is no better than full-batch gradient descent (GD), and the purported implicit regularization effects of SGD lack a precise explanation. In this work, we study the dynamics of multi-pass SGD on high-dimensional convex quadratics and establish an asymptotic equivalence to a stochastic differential equation, which we call homogenized stochastic gradient descent (HSGD), whose solutions we characterize explicitly in terms of a Volterra integral equation. These results yield precise formulas for the learning and risk trajectories, which reveal a mechanism of implicit conditioning that explains the efficiency of SGD relative to GD. We also prove that the noise from SGD negatively impacts generalization performance, ruling out the possibility of any type of implicit regularization in this context. Finally, we show how to adapt the HSGD formalism to include streaming SGD, which allows us to produce an exact prediction for the excess risk of multi-pass SGD relative to that of streaming SGD (bootstrap risk).
Precise Learning Curves and Higher-Order Scaling Limits for Dot Product Kernel Regression
May 30, 2022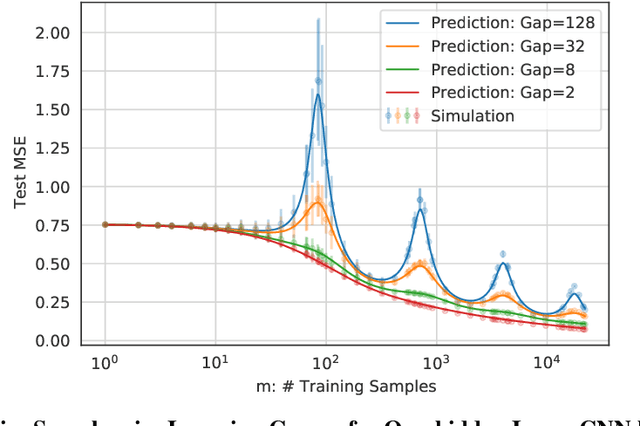
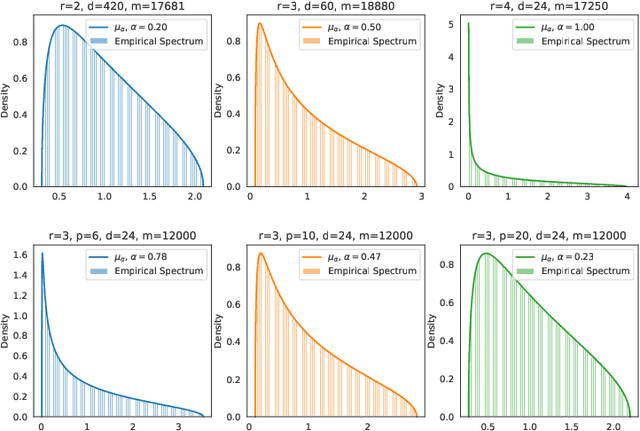
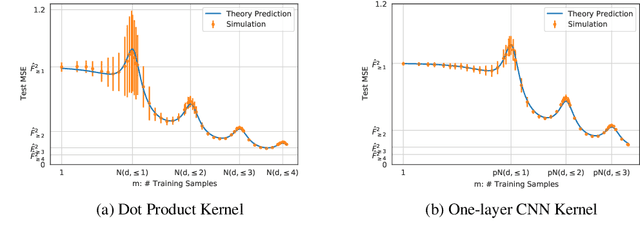
As modern machine learning models continue to advance the computational frontier, it has become increasingly important to develop precise estimates for expected performance improvements under different model and data scaling regimes. Currently, theoretical understanding of the learning curves that characterize how the prediction error depends on the number of samples is restricted to either large-sample asymptotics ($m\to\infty$) or, for certain simple data distributions, to the high-dimensional asymptotics in which the number of samples scales linearly with the dimension ($m\propto d$). There is a wide gulf between these two regimes, including all higher-order scaling relations $m\propto d^r$, which are the subject of the present paper. We focus on the problem of kernel ridge regression for dot-product kernels and present precise formulas for the test error, bias, and variance, for data drawn uniformly from the sphere in the $r$th-order asymptotic scaling regime $m\to\infty$ with $m/d^r$ held constant. We observe a peak in the learning curve whenever $m \approx d^r/r!$ for any integer $r$, leading to multiple sample-wise descent and nontrivial behavior at multiple scales.
Homogenization of SGD in high-dimensions: Exact dynamics and generalization properties
May 14, 2022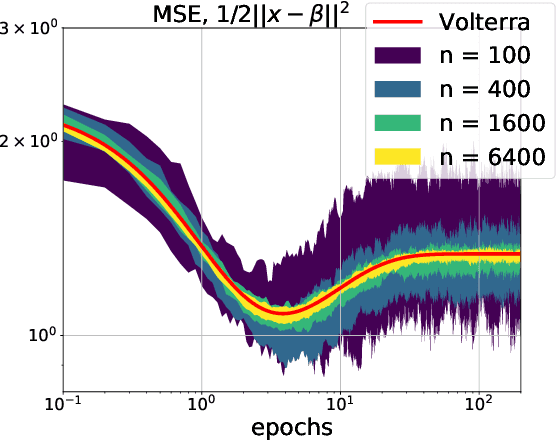

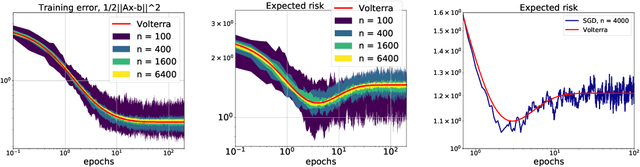
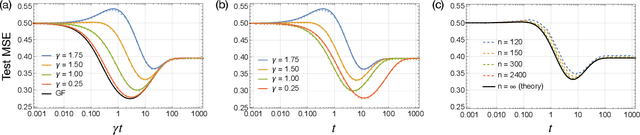
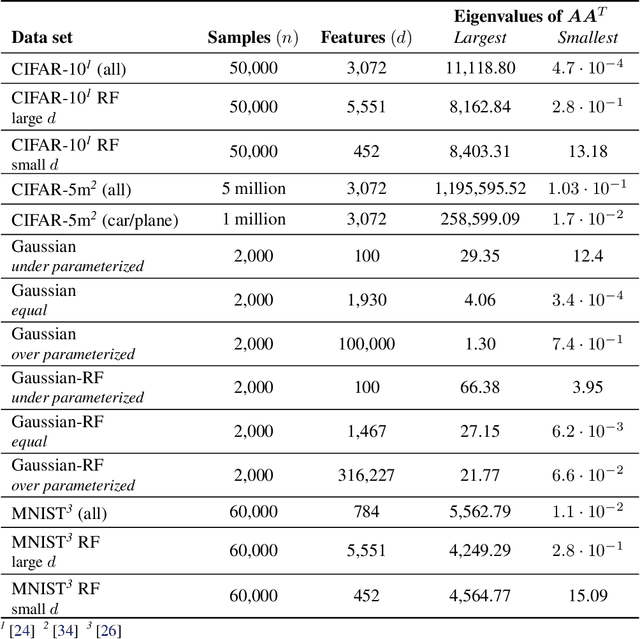
We develop a stochastic differential equation, called homogenized SGD, for analyzing the dynamics of stochastic gradient descent (SGD) on a high-dimensional random least squares problem with $\ell^2$-regularization. We show that homogenized SGD is the high-dimensional equivalence of SGD -- for any quadratic statistic (e.g., population risk with quadratic loss), the statistic under the iterates of SGD converges to the statistic under homogenized SGD when the number of samples $n$ and number of features $d$ are polynomially related ($d^c < n < d^{1/c}$ for some $c > 0$). By analyzing homogenized SGD, we provide exact non-asymptotic high-dimensional expressions for the generalization performance of SGD in terms of a solution of a Volterra integral equation. Further we provide the exact value of the limiting excess risk in the case of quadratic losses when trained by SGD. The analysis is formulated for data matrices and target vectors that satisfy a family of resolvent conditions, which can roughly be viewed as a weak (non-quantitative) form of delocalization of sample-side singular vectors of the data. Several motivating applications are provided including sample covariance matrices with independent samples and random features with non-generative model targets.
Covariate Shift in High-Dimensional Random Feature Regression
Nov 16, 2021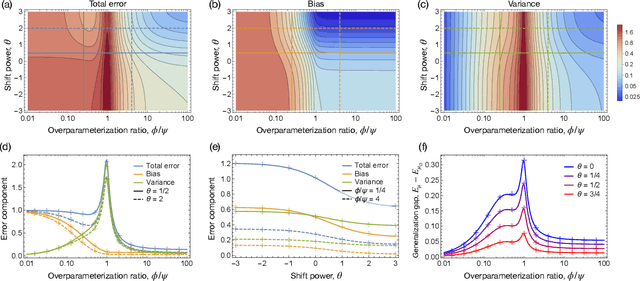
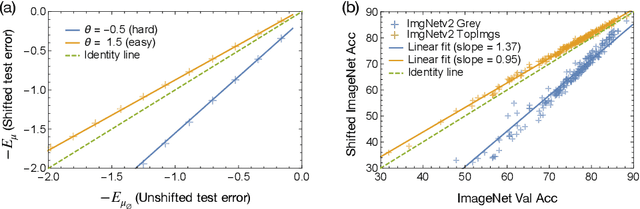
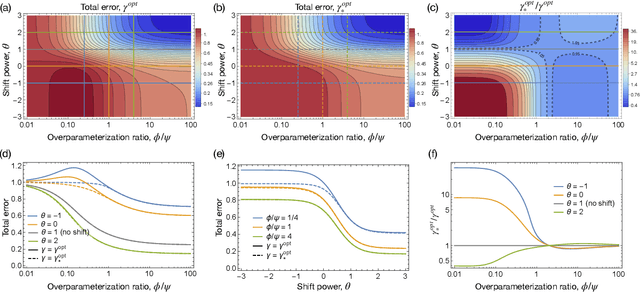
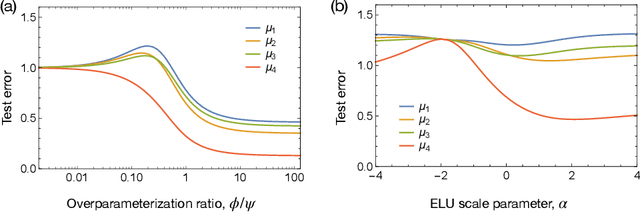
A significant obstacle in the development of robust machine learning models is covariate shift, a form of distribution shift that occurs when the input distributions of the training and test sets differ while the conditional label distributions remain the same. Despite the prevalence of covariate shift in real-world applications, a theoretical understanding in the context of modern machine learning has remained lacking. In this work, we examine the exact high-dimensional asymptotics of random feature regression under covariate shift and present a precise characterization of the limiting test error, bias, and variance in this setting. Our results motivate a natural partial order over covariate shifts that provides a sufficient condition for determining when the shift will harm (or even help) test performance. We find that overparameterized models exhibit enhanced robustness to covariate shift, providing one of the first theoretical explanations for this intriguing phenomenon. Additionally, our analysis reveals an exact linear relationship between in-distribution and out-of-distribution generalization performance, offering an explanation for this surprising recent empirical observation.
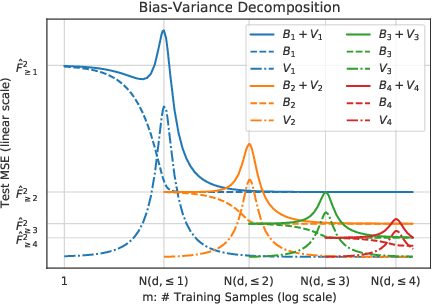
Understanding Double Descent Requires a Fine-Grained Bias-Variance Decomposition
Nov 04, 2020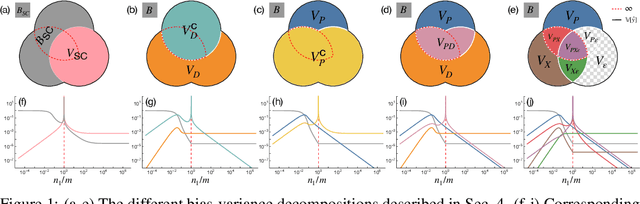
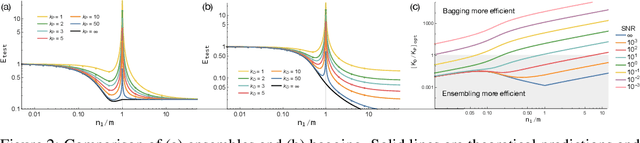
Classical learning theory suggests that the optimal generalization performance of a machine learning model should occur at an intermediate model complexity, with simpler models exhibiting high bias and more complex models exhibiting high variance of the predictive function. However, such a simple trade-off does not adequately describe deep learning models that simultaneously attain low bias and variance in the heavily overparameterized regime. A primary obstacle in explaining this behavior is that deep learning algorithms typically involve multiple sources of randomness whose individual contributions are not visible in the total variance. To enable fine-grained analysis, we describe an interpretable, symmetric decomposition of the variance into terms associated with the randomness from sampling, initialization, and the labels. Moreover, we compute the high-dimensional asymptotic behavior of this decomposition for random feature kernel regression, and analyze the strikingly rich phenomenology that arises. We find that the bias decreases monotonically with the network width, but the variance terms exhibit non-monotonic behavior and can diverge at the interpolation boundary, even in the absence of label noise. The divergence is caused by the \emph{interaction} between sampling and initialization and can therefore be eliminated by marginalizing over samples (i.e. bagging) \emph{or} over the initial parameters (i.e. ensemble learning).
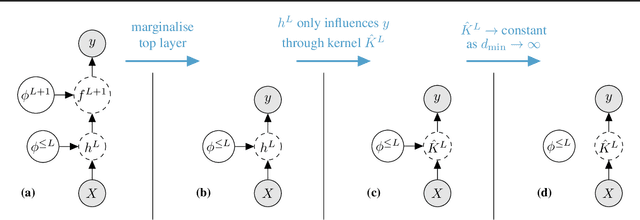
Exploring the Uncertainty Properties of Neural Networks' Implicit Priors in the Infinite-Width Limit
Oct 14, 2020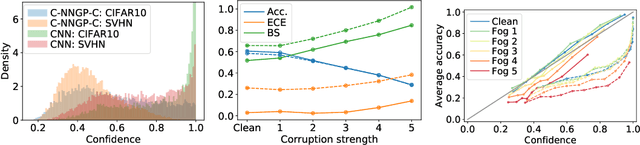
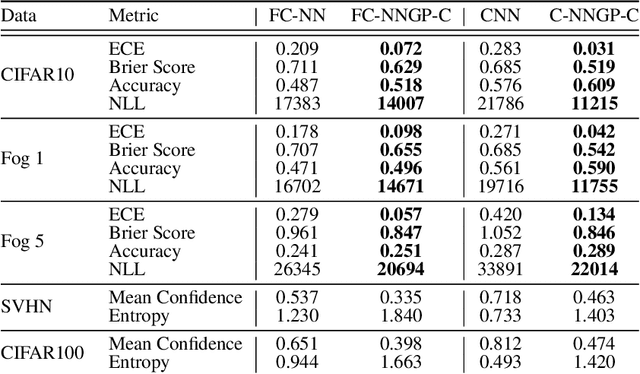
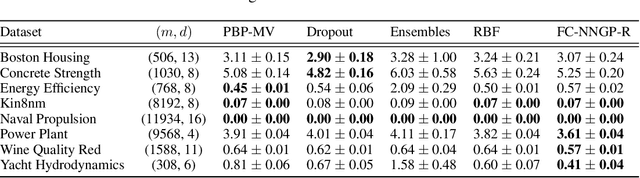

Modern deep learning models have achieved great success in predictive accuracy for many data modalities. However, their application to many real-world tasks is restricted by poor uncertainty estimates, such as overconfidence on out-of-distribution (OOD) data and ungraceful failing under distributional shift. Previous benchmarks have found that ensembles of neural networks (NNs) are typically the best calibrated models on OOD data. Inspired by this, we leverage recent theoretical advances that characterize the function-space prior of an ensemble of infinitely-wide NNs as a Gaussian process, termed the neural network Gaussian process (NNGP). We use the NNGP with a softmax link function to build a probabilistic model for multi-class classification and marginalize over the latent Gaussian outputs to sample from the posterior. This gives us a better understanding of the implicit prior NNs place on function space and allows a direct comparison of the calibration of the NNGP and its finite-width analogue. We also examine the calibration of previous approaches to classification with the NNGP, which treat classification problems as regression to the one-hot labels. In this case the Bayesian posterior is exact, and we compare several heuristics to generate a categorical distribution over classes. We find these methods are well calibrated under distributional shift. Finally, we consider an infinite-width final layer in conjunction with a pre-trained embedding. This replicates the important practical use case of transfer learning and allows scaling to significantly larger datasets. As well as achieving competitive predictive accuracy, this approach is better calibrated than its finite width analogue.
Temperature check: theory and practice for training models with softmax-cross-entropy losses
Oct 14, 2020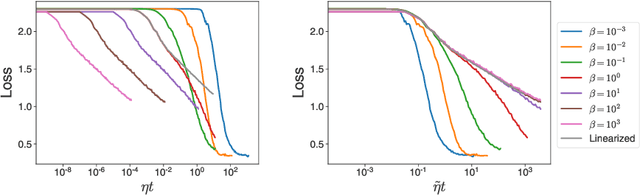
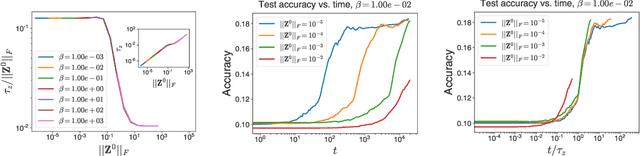
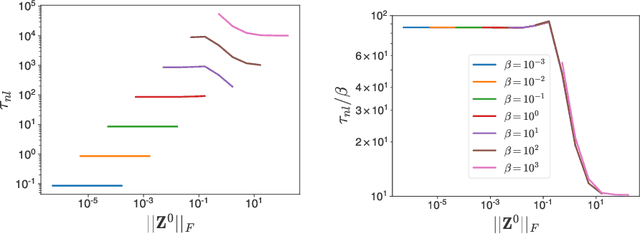
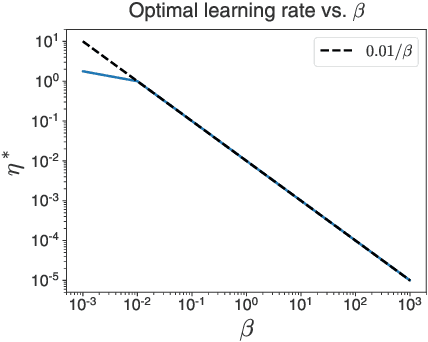
The softmax function combined with a cross-entropy loss is a principled approach to modeling probability distributions that has become ubiquitous in deep learning. The softmax function is defined by a lone hyperparameter, the temperature, that is commonly set to one or regarded as a way to tune model confidence after training; however, less is known about how the temperature impacts training dynamics or generalization performance. In this work we develop a theory of early learning for models trained with softmax-cross-entropy loss and show that the learning dynamics depend crucially on the inverse-temperature $\beta$ as well as the magnitude of the logits at initialization, $||\beta{\bf z}||_{2}$. We follow up these analytic results with a large-scale empirical study of a variety of model architectures trained on CIFAR10, ImageNet, and IMDB sentiment analysis. We find that generalization performance depends strongly on the temperature, but only weakly on the initial logit magnitude. We provide evidence that the dependence of generalization on $\beta$ is not due to changes in model confidence, but is a dynamical phenomenon. It follows that the addition of $\beta$ as a tunable hyperparameter is key to maximizing model performance. Although we find the optimal $\beta$ to be sensitive to the architecture, our results suggest that tuning $\beta$ over the range $10^{-2}$ to $10^1$ improves performance over all architectures studied. We find that smaller $\beta$ may lead to better peak performance at the cost of learning stability.
Finite Versus Infinite Neural Networks: an Empirical Study
Sep 08, 2020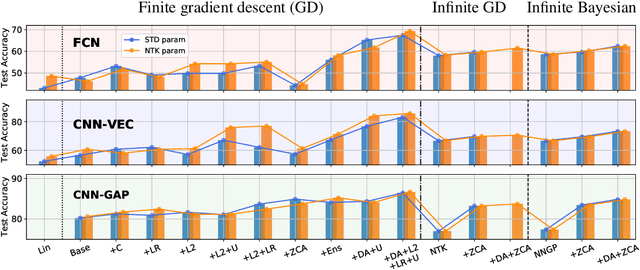



We perform a careful, thorough, and large scale empirical study of the correspondence between wide neural networks and kernel methods. By doing so, we resolve a variety of open questions related to the study of infinitely wide neural networks. Our experimental results include: kernel methods outperform fully-connected finite-width networks, but underperform convolutional finite width networks; neural network Gaussian process (NNGP) kernels frequently outperform neural tangent (NT) kernels; centered and ensembled finite networks have reduced posterior variance and behave more similarly to infinite networks; weight decay and the use of a large learning rate break the correspondence between finite and infinite networks; the NTK parameterization outperforms the standard parameterization for finite width networks; diagonal regularization of kernels acts similarly to early stopping; floating point precision limits kernel performance beyond a critical dataset size; regularized ZCA whitening improves accuracy; finite network performance depends non-monotonically on width in ways not captured by double descent phenomena; equivariance of CNNs is only beneficial for narrow networks far from the kernel regime. Our experiments additionally motivate an improved layer-wise scaling for weight decay which improves generalization in finite-width networks. Finally, we develop improved best practices for using NNGP and NT kernels for prediction, including a novel ensembling technique. Using these best practices we achieve state-of-the-art results on CIFAR-10 classification for kernels corresponding to each architecture class we consider.