 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREPE: Learnable Prompting With CLIP Improves Visual Relationship Prediction
Jul 19, 2023In this paper, we explore the potential of Vision-Language Models (VLMs), specifically CLIP, in predicting visual object relationships, which involves interpreting visual features from images into language-based relations. Current state-of-the-art methods use complex graphical models that utilize language cues and visual features to address this challenge. We hypothesize that the strong language priors in CLIP embeddings can simplify these graphical models paving for a simpler approach. We adopt the UVTransE relation prediction framework, which learns the relation as a translational embedding with subject, object, and union box embeddings from a scene. We systematically explore the design of CLIP-based subject, object, and union-box representations within the UVTransE framework and propose CREPE (CLIP Representation Enhanced Predicate Estimation). CREPE utilizes text-based representations for all three bounding boxes and introduces a novel contrastive training strategy to automatically infer the text prompt for union-box. Our approach achieves state-of-the-art performance in predicate estimation, mR@5 27.79, and mR@20 31.95 on the Visual Genome benchmark, achieving a 15.3\% gain in performance over recent state-of-the-art at mR@20. This work demonstrates CLIP's effectiveness in object relation prediction and encourages further research on VLMs in this challenging domain.
Target-Aware Generative Augmentations for Single-Shot Adaptation
May 22, 2023



In this paper, we address the problem of adapting models from a source domain to a target domain, a task that has become increasingly important due to the brittle generalization of deep neural networks. While several test-time adaptation techniques have emerged, they typically rely on synthetic toolbox data augmentations in cases of limited target data availability. We consider the challenging setting of single-shot adaptation and explore the design of augmentation strategies. We argue that augmentations utilized by existing methods are insufficient to handle large distribution shifts, and hence propose a new approach SiSTA, which first fine-tunes a generative model from the source domain using a single-shot target, and then employs novel sampling strategies for curating synthetic target data. Using experiments on a variety of benchmarks, distribution shifts and image corruptions, we find that SiSTA produces significantly improved generalization over existing baselines in face attribute detection and multi-class object recognition. Furthermore, SiSTA performs competitively to models obtained by training on larger target datasets. Our codes can be accessed at https://github.com/Rakshith-2905/SiSTA.
A Closer Look at Model Adaptation using Feature Distortion and Simplicity Bias
Mar 23, 2023Advances in the expressivity of pretrained models have increased interest in the design of adaptation protocols which enable safe and effective transfer learning. Going beyond conventional linear probing (LP) and fine tuning (FT) strategies, protocols that can effectively control feature distortion, i.e., the failure to update features orthogonal to the in-distribution, have been found to achieve improved out-of-distribution generalization (OOD). In order to limit this distortion, the LP+FT protocol, which first learns a linear probe and then uses this initialization for subsequent FT, was proposed. However, in this paper, we find when adaptation protocols (LP, FT, LP+FT) are also evaluated on a variety of safety objectives (e.g., calibration, robustness, etc.), a complementary perspective to feature distortion is helpful to explain protocol behavior. To this end, we study the susceptibility of protocols to simplicity bias (SB), i.e. the well-known propensity of deep neural networks to rely upon simple features, as SB has recently been shown to underlie several problems in robust generalization. Using a synthetic dataset, we demonstrate the susceptibility of existing protocols to SB. Given the strong effectiveness of LP+FT, we then propose modified linear probes that help mitigate SB, and lead to better initializations for subsequent FT. We verify the effectiveness of the proposed LP+FT variants for decreasing SB in a controlled setting, and their ability to improve OOD generalization and safety on three adaptation datasets.
A Closer Look at Scoring Functions and Generalization Prediction
Mar 23, 2023



Generalization error predictors (GEPs) aim to predict model performance on unseen distributions by deriving dataset-level error estimates from sample-level scores. However, GEPs often utilize disparate mechanisms (e.g., regressors, thresholding functions, calibration datasets, etc), to derive such error estimates, which can obfuscate the benefits of a particular scoring function. Therefore, in this work, we rigorously study the effectiveness of popular scoring functions (confidence, local manifold smoothness, model agreement), independent of mechanism choice. We find, absent complex mechanisms, that state-of-the-art confidence- and smoothness- based scores fail to outperform simple model-agreement scores when estimating error under distribution shifts and corruptions. Furthermore, on realistic settings where the training data has been compromised (e.g., label noise, measurement noise, undersampling), we find that model-agreement scores continue to perform well and that ensemble diversity is important for improving its performance. Finally, to better understand the limitations of scoring functions, we demonstrate that simplicity bias, or the propensity of deep neural networks to rely upon simple but brittle features, can adversely affect GEP performance. Overall, our work carefully studies the effectiveness of popular scoring functions in realistic settings and helps to better understand their limitations.
Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models
Mar 19, 2023



Generative Adversarial Networks (GANs) are notoriously difficult to train especially for complex distributions and with limited data. This has driven the need for tools to audit trained networks in human intelligible format, for example, to identify biases or ensure fairness. Existing GAN audit tools are restricted to coarse-grained, model-data comparisons based on summary statistics such as FID or recall. In this paper, we propose an alternative approach that compares a newly developed GAN against a prior baseline. To this end, we introduce Cross-GAN Auditing (xGA) that, given an established "reference" GAN and a newly proposed "client" GAN, jointly identifies intelligible attributes that are either common across both GANs, novel to the client GAN, or missing from the client GAN. This provides both users and model developers an intuitive assessment of similarity and differences between GANs. We introduce novel metrics to evaluate attribute-based GAN auditing approaches and use these metrics to demonstrate quantitatively that xGA outperforms baseline approaches. We also include qualitative results that illustrate the common, novel and missing attributes identified by xGA from GANs trained on a variety of image datasets.
DOLCE: A Model-Based Probabilistic Diffusion Framework for Limited-Angle CT Reconstruction
Nov 22, 2022Limited-Angle Computed Tomography (LACT) is a non-destructive evaluation technique used in a variety of applications ranging from security to medicine. The limited angle coverage in LACT is often a dominant source of severe artifacts in the reconstructed images, making it a challenging inverse problem. We present DOLCE, a new deep model-based framework for LACT that uses a conditional diffusion model as an image prior. Diffusion models are a recent class of deep generative models that are relatively easy to train due to their implementation as image denoisers. DOLCE can form high-quality images from severely under-sampled data by integrating data-consistency updates with the sampling updates of a diffusion model, which is conditioned on the transformed limited-angle data. We show through extensive experimentation on several challenging real LACT datasets that, the same pre-trained DOLCE model achieves the SOTA performance on drastically different types of images. Additionally, we show that, unlike standard LACT reconstruction methods, DOLCE naturally enables the quantification of the reconstruction uncertainty by generating multiple samples consistent with the measured data.
On-the-fly Object Detection using StyleGAN with CLIP Guidance
Oct 30, 2022We present a fully automated framework for building object detectors on satellite imagery without requiring any human annotation or intervention. We achieve this by leveraging the combined power of modern generative models (e.g., StyleGAN) and recent advances in multi-modal learning (e.g., CLIP). While deep generative models effectively encode the key semantics pertinent to a data distribution, this information is not immediately accessible for downstream tasks, such as object detection. In this work, we exploit CLIP's ability to associate image features with text descriptions to identify neurons in the generator network, which are subsequently used to build detectors on-the-fly.
Single-Shot Domain Adaptation via Target-Aware Generative Augmentation
Oct 29, 2022The problem of adapting models from a source domain using data from any target domain of interest has gained prominence, thanks to the brittle generalization in deep neural networks. While several test-time adaptation techniques have emerged, they typically rely on synthetic data augmentations in cases of limited target data availability. In this paper, we consider the challenging setting of single-shot adaptation and explore the design of augmentation strategies. We argue that augmentations utilized by existing methods are insufficient to handle large distribution shifts, and hence propose a new approach SiSTA (Single-Shot Target Augmentations), which first fine-tunes a generative model from the source domain using a single-shot target, and then employs novel sampling strategies for curating synthetic target data. Using experiments with a state-of-the-art domain adaptation method, we find that SiSTA produces improvements as high as 20\% over existing baselines under challenging shifts in face attribute detection, and that it performs competitively to oracle models obtained by training on a larger target dataset.
Analyzing Data-Centric Properties for Contrastive Learning on Graphs
Aug 04, 2022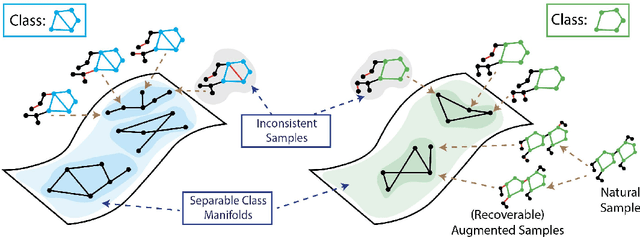

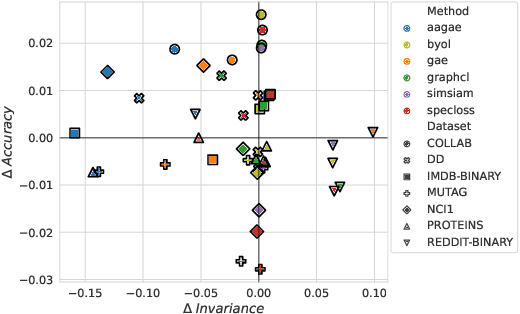

Recent analyses of self-supervised learning (SSL) find the following data-centric properties to be critical for learning good representations: invariance to task-irrelevant semantics, separability of classes in some latent space, and recoverability of labels from augmented samples. However, given their discrete, non-Euclidean nature, graph datasets and graph SSL methods are unlikely to satisfy these properties. This raises the question: how do graph SSL methods, such as contrastive learning (CL), work well? To systematically probe this question, we perform a generalization analysis for CL when using generic graph augmentations (GGAs), with a focus on data-centric properties. Our analysis yields formal insights into the limitations of GGAs and the necessity of task-relevant augmentations. As we empirically show, GGAs do not induce task-relevant invariances on common benchmark datasets, leading to only marginal gains over naive, untrained baselines. Our theory motivates a synthetic data generation process that enables control over task-relevant information and boasts pre-defined optimal augmentations. This flexible benchmark helps us identify yet unrecognized limitations in advanced augmentation techniques (e.g., automated methods). Overall, our work rigorously contextualizes, both empirically and theoretically, the effects of data-centric properties on augmentation strategies and learning paradigms for graph SSL.
Exploring the Design of Adaptation Protocols for Improved Generalization and Machine Learning Safety
Jul 26, 2022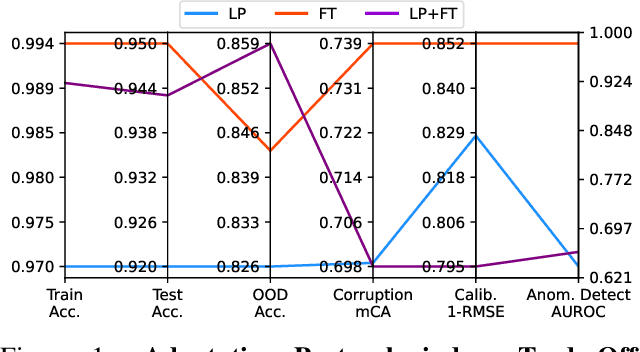

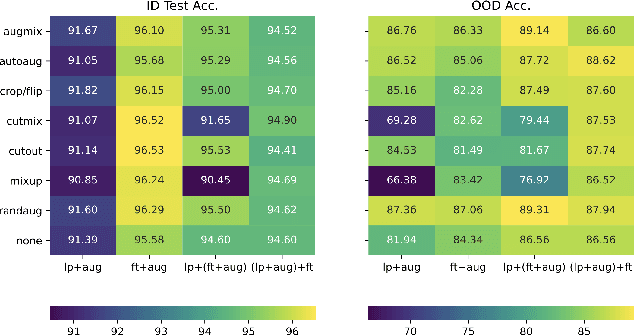
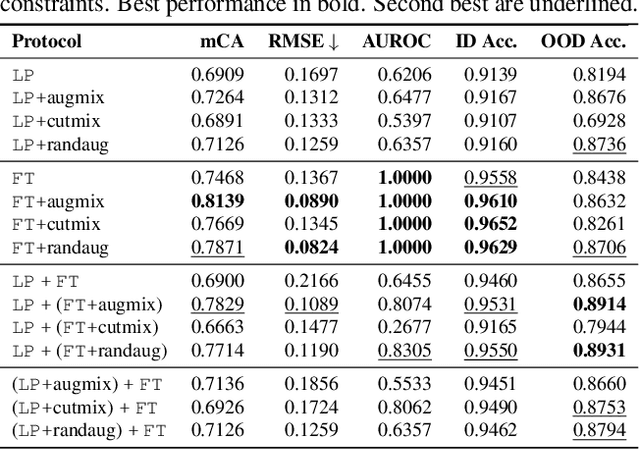
While directly fine-tuning (FT) large-scale, pretrained models on task-specific data is well-known to induce strong in-distribution task performance, recent works have demonstrated that different adaptation protocols, such as linear probing (LP) prior to FT, can improve out-of-distribution generalization. However, the design space of such adaptation protocols remains under-explored and the evaluation of such protocols has primarily focused on distribution shifts. Therefore, in this work, we evaluate common adaptation protocols across distributions shifts and machine learning safety metrics (e.g., anomaly detection, calibration, robustness to corruptions). We find that protocols induce disparate trade-offs that were not apparent from prior evaluation. Further, we demonstrate that appropriate pairing of data augmentation and protocol can substantially mitigate this trade-off. Finally, we hypothesize and empirically see that using hardness-promoting augmentations during LP and then FT with augmentations may be particularly effective for trade-off mitigation.