 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaguna M.1/XS.2 Technical Report
May 26, 2026We present Laguna M.1 and Laguna XS.2, two Mixture-of-Experts foundation models built for long-horizon, agentic coding: M.1 has $225.8$B total parameters ($23.4$B activated per token) and XS.2 has $33.4$B total ($3$B activated). Both models were trained from scratch end-to-end inside the same internal system that we refer to as our Model Factory: a tightly-integrated stack of versioned data, training, evaluation, and inference components that turn model development into an industrial process. We describe the principles and design choices of the Model Factory and also detail the end-to-end training process of our models, throughout pre-training data and architecture, post-training stages, evaluation, and quantization. On agentic software engineering and terminal benchmarks (SWE-bench Verified, SWE-bench Multilingual, SWE-Bench Pro, and Terminal-Bench 2.0) M.1 and XS.2 are competitive with state-of-the-art open models in their respective weight classes. Laguna XS.2 weights are released under Apache~2.0 at https://huggingface.co/collections/poolside/laguna-xs2.
Learning Obfuscations Of LLM Embedding Sequences: Stained Glass Transform
Jun 11, 2025The high cost of ownership of AI compute infrastructure and challenges of robust serving of large language models (LLMs) has led to a surge in managed Model-as-a-service deployments. Even when enterprises choose on-premises deployments, the compute infrastructure is typically shared across many teams in order to maximize the return on investment. In both scenarios the deployed models operate only on plaintext data, and so enterprise data owners must allow their data to appear in plaintext on a shared or multi-tenant compute infrastructure. This results in data owners with private or sensitive data being hesitant or restricted in what data they use with these types of deployments. In this work we introduce the Stained Glass Transform, a learned, stochastic, and sequence dependent transformation of the word embeddings of an LLM which information theoretically provides privacy to the input of the LLM while preserving the utility of model. We theoretically connect a particular class of Stained Glass Transforms to the theory of mutual information of Gaussian Mixture Models. We then calculate a-postiori privacy estimates, based on mutual information, and verify the privacy and utility of instances of transformed embeddings through token level metrics of privacy and standard LLM performance benchmarks.
THELMA: Task Based Holistic Evaluation of Large Language Model Applications-RAG Question Answering
May 16, 2025We propose THELMA (Task Based Holistic Evaluation of Large Language Model Applications), a reference free framework for RAG (Retrieval Augmented generation) based question answering (QA) applications. THELMA consist of six interdependent metrics specifically designed for holistic, fine grained evaluation of RAG QA applications. THELMA framework helps developers and application owners evaluate, monitor and improve end to end RAG QA pipelines without requiring labelled sources or reference responses.We also present our findings on the interplay of the proposed THELMA metrics, which can be interpreted to identify the specific RAG component needing improvement in QA applications.
On Frank-Wolfe Optimization for Adversarial Robustness and Interpretability
Dec 22, 2020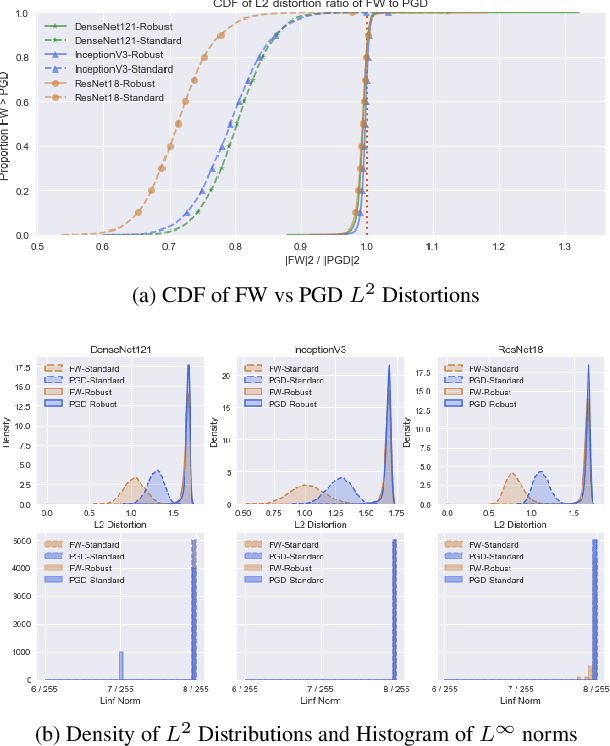

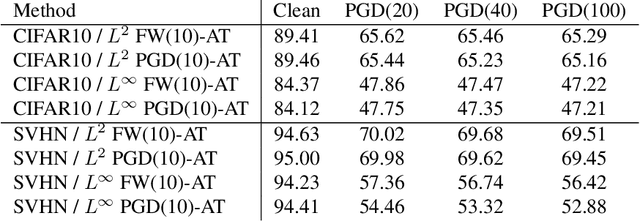

Deep neural networks are easily fooled by small perturbations known as adversarial attacks. Adversarial Training (AT) is a technique that approximately solves a robust optimization problem to minimize the worst-case loss and is widely regarded as the most effective defense against such attacks. While projected gradient descent (PGD) has received most attention for approximately solving the inner maximization of AT, Frank-Wolfe (FW) optimization is projection-free and can be adapted to any $L^p$ norm. A Frank-Wolfe adversarial training approach is presented and is shown to provide as competitive level of robustness as PGD-AT without much tuning for a variety of architectures. We empirically show that robustness is strongly connected to the $L^2$ magnitude of the adversarial perturbation and that more locally linear loss landscapes tend to have larger $L^2$ distortions despite having the same $L^\infty$ distortion. We provide theoretical guarantees on the magnitude of the distortion for FW that depend on local geometry which FW-AT exploits. It is empirically shown that FW-AT achieves strong robustness to white-box attacks and black-box attacks and offers improved resistance to gradient masking. Further, FW-AT allows networks to learn high-quality human-interpretable features which are then used to generate counterfactual explanations to model predictions by using dense and sparse adversarial perturbations.
Ultrasound Diagnosis of COVID-19: Robustness and Explainability
Nov 30, 2020



Diagnosis of COVID-19 at point of care is vital to the containment of the global pandemic. Point of care ultrasound (POCUS) provides rapid imagery of lungs to detect COVID-19 in patients in a repeatable and cost effective way. Previous work has used public datasets of POCUS videos to train an AI model for diagnosis that obtains high sensitivity. Due to the high stakes application we propose the use of robust and explainable techniques. We demonstrate experimentally that robust models have more stable predictions and offer improved interpretability. A framework of contrastive explanations based on adversarial perturbations is used to explain model predictions that aligns with human visual perception.
Second Order Optimization for Adversarial Robustness and Interpretability
Sep 10, 2020



Deep neural networks are easily fooled by small perturbations known as adversarial attacks. Adversarial Training (AT) is a technique aimed at learning features robust to such attacks and is widely regarded as a very effective defense. However, the computational cost of such training can be prohibitive as the network size and input dimensions grow. Inspired by the relationship between robustness and curvature, we propose a novel regularizer which incorporates first and second order information via a quadratic approximation to the adversarial loss. The worst case quadratic loss is approximated via an iterative scheme. It is shown that using only a single iteration in our regularizer achieves stronger robustness than prior gradient and curvature regularization schemes, avoids gradient obfuscation, and, with additional iterations, achieves strong robustness with significantly lower training time than AT. Further, it retains the interesting facet of AT that networks learn features which are well-aligned with human perception. We demonstrate experimentally that our method produces higher quality human-interpretable features than other geometric regularization techniques. These robust features are then used to provide human-friendly explanations to model predictions.