 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
ES Is More Than Just a Traditional Finite-Difference Approximator
May 01, 2018
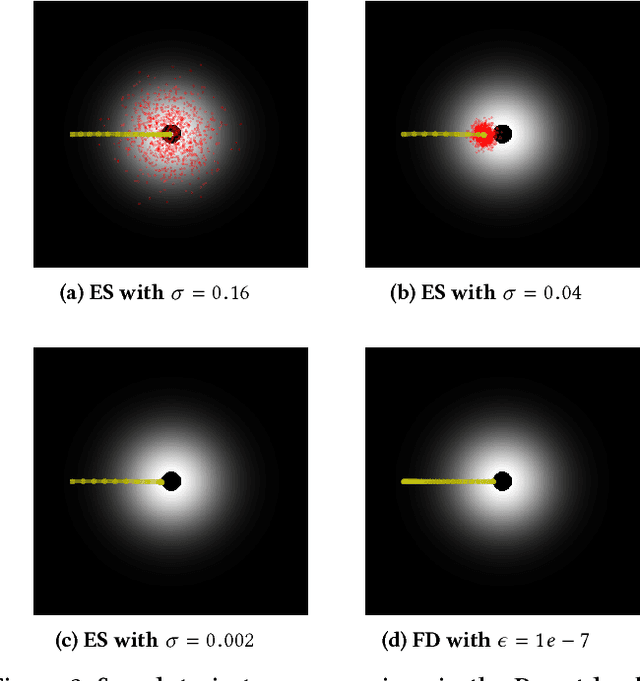
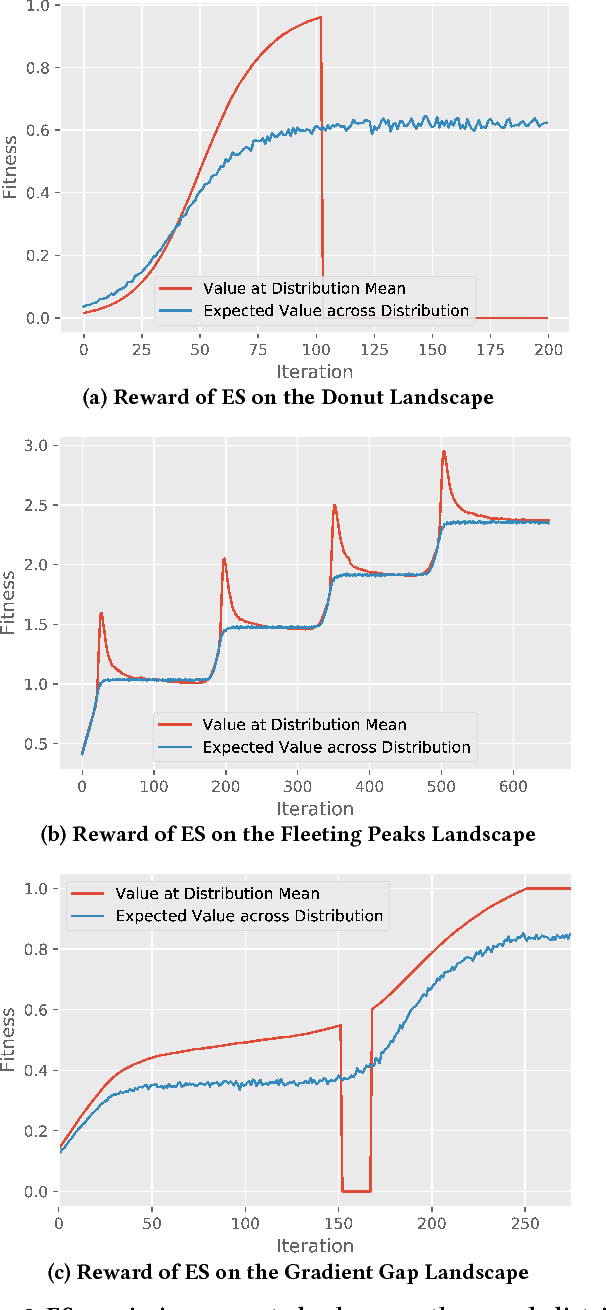
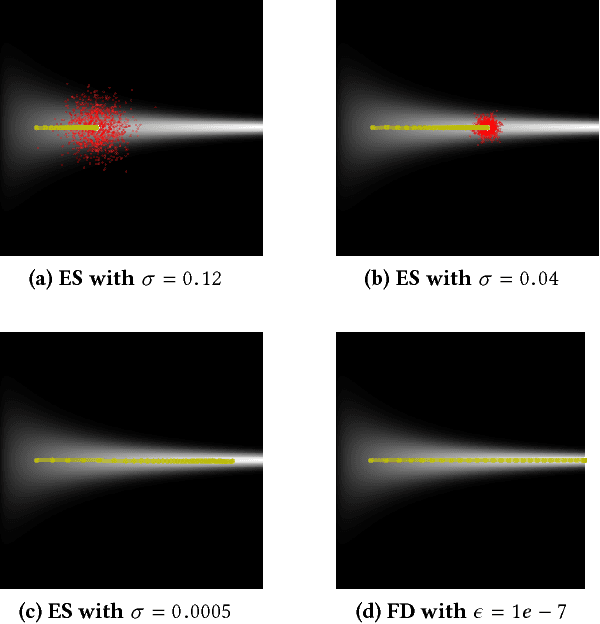
An evolution strategy (ES) variant based on a simplification of a natural evolution strategy recently attracted attention because it performs surprisingly well in challenging deep reinforcement learning domains. It searches for neural network parameters by generating perturbations to the current set of parameters, checking their performance, and moving in the aggregate direction of higher reward. Because it resembles a traditional finite-difference approximation of the reward gradient, it can naturally be confused with one. However, this ES optimizes for a different gradient than just reward: It optimizes for the average reward of the entire population, thereby seeking parameters that are robust to perturbation. This difference can channel ES into distinct areas of the search space relative to gradient descent, and also consequently to networks with distinct properties. This unique robustness-seeking property, and its consequences for optimization, are demonstrated in several domains. They include humanoid locomotion, where networks from policy gradient-based reinforcement learning are significantly less robust to parameter perturbation than ES-based policies solving the same task. While the implications of such robustness and robustness-seeking remain open to further study, this work's main contribution is to highlight such differences and their potential importance.
Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients
May 01, 2018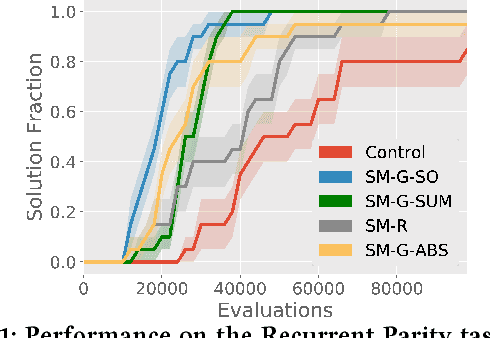
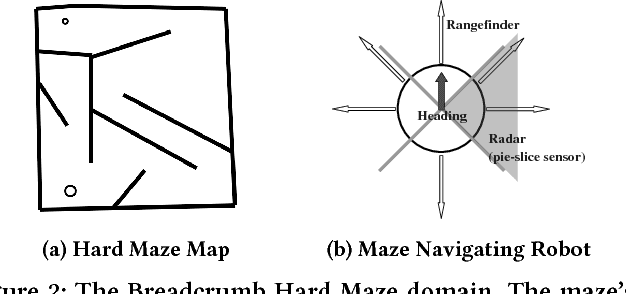
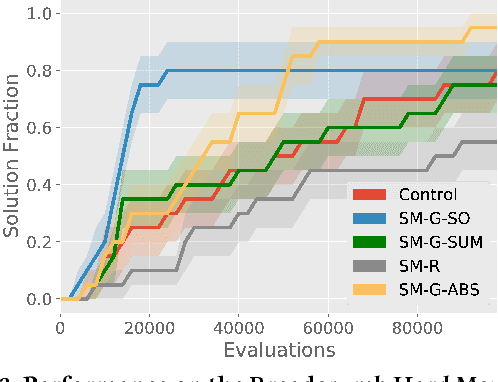
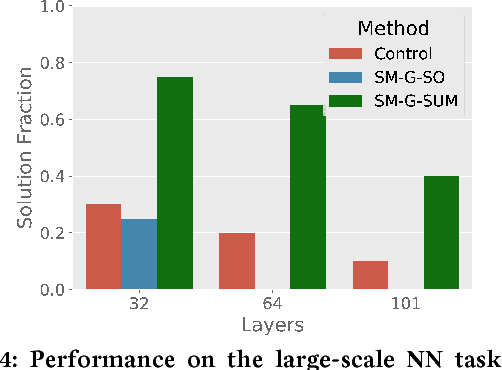
While neuroevolution (evolving neural networks) has a successful track record across a variety of domains from reinforcement learning to artificial life, it is rarely applied to large, deep neural networks. A central reason is that while random mutation generally works in low dimensions, a random perturbation of thousands or millions of weights is likely to break existing functionality, providing no learning signal even if some individual weight changes were beneficial. This paper proposes a solution by introducing a family of safe mutation (SM) operators that aim within the mutation operator itself to find a degree of change that does not alter network behavior too much, but still facilitates exploration. Importantly, these SM operators do not require any additional interactions with the environment. The most effective SM variant capitalizes on the intriguing opportunity to scale the degree of mutation of each individual weight according to the sensitivity of the network's outputs to that weight, which requires computing the gradient of outputs with respect to the weights (instead of the gradient of error, as in conventional deep learning). This safe mutation through gradients (SM-G) operator dramatically increases the ability of a simple genetic algorithm-based neuroevolution method to find solutions in high-dimensional domains that require deep and/or recurrent neural networks (which tend to be particularly brittle to mutation), including domains that require processing raw pixels. By improving our ability to evolve deep neural networks, this new safer approach to mutation expands the scope of domains amenable to neuroevolution.