 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Transformers: A Survey
Jan 16, 2022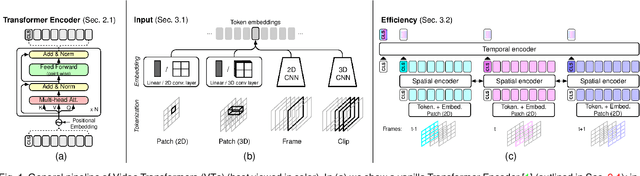
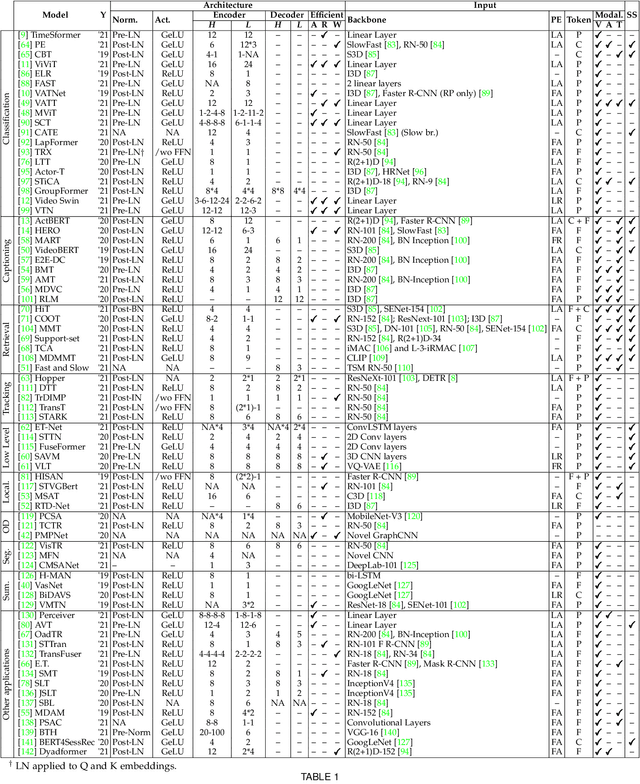
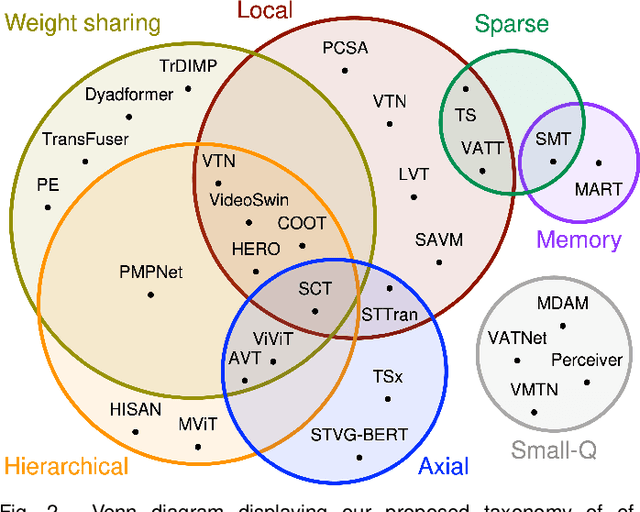
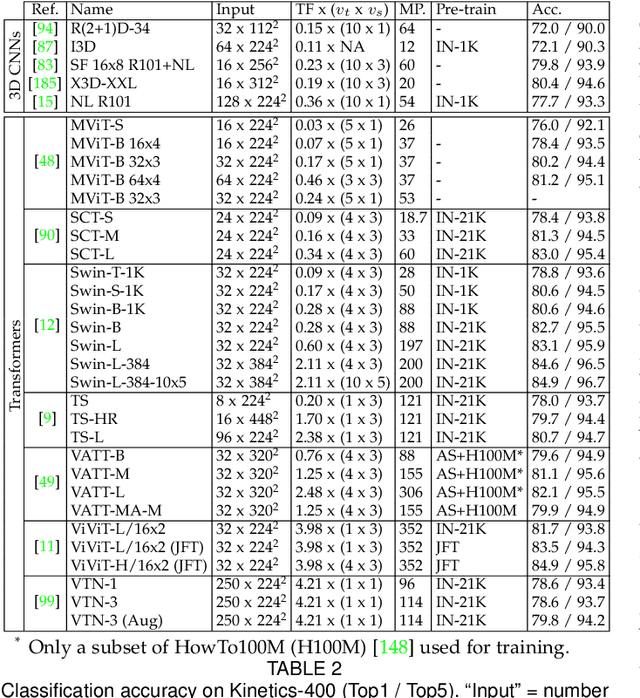
Transformer models have shown great success modeling long-range interactions. Nevertheless, they scale quadratically with input length and lack inductive biases. These limitations can be further exacerbated when dealing with the high dimensionality of video. Proper modeling of video, which can span from seconds to hours, requires handling long-range interactions. This makes Transformers a promising tool for solving video related tasks, but some adaptations are required. While there are previous works that study the advances of Transformers for vision tasks, there is none that focus on in-depth analysis of video-specific designs. In this survey we analyse and summarize the main contributions and trends for adapting Transformers to model video data. Specifically, we delve into how videos are embedded and tokenized, finding a very widspread use of large CNN backbones to reduce dimensionality and a predominance of patches and frames as tokens. Furthermore, we study how the Transformer layer has been tweaked to handle longer sequences, generally by reducing the number of tokens in single attention operation. Also, we analyse the self-supervised losses used to train Video Transformers, which to date are mostly constrained to contrastive approaches. Finally, we explore how other modalities are integrated with video and conduct a performance comparison on the most common benchmark for Video Transformers (i.e., action classification), finding them to outperform 3D CNN counterparts with equivalent FLOPs and no significant parameter increase.
Dyadformer: A Multi-modal Transformer for Long-Range Modeling of Dyadic Interactions
Sep 20, 2021



Personality computing has become an emerging topic in computer vision, due to the wide range of applications it can be used for. However, most works on the topic have focused on analyzing the individual, even when applied to interaction scenarios, and for short periods of time. To address these limitations, we present the Dyadformer, a novel multi-modal multi-subject Transformer architecture to model individual and interpersonal features in dyadic interactions using variable time windows, thus allowing the capture of long-term interdependencies. Our proposed cross-subject layer allows the network to explicitly model interactions among subjects through attentional operations. This proof-of-concept approach shows how multi-modality and joint modeling of both interactants for longer periods of time helps to predict individual attributes. With Dyadformer, we improve state-of-the-art self-reported personality inference results on individual subjects on the UDIVA v0.5 dataset.
Context-Aware Personality Inference in Dyadic Scenarios: Introducing the UDIVA Dataset
Dec 28, 2020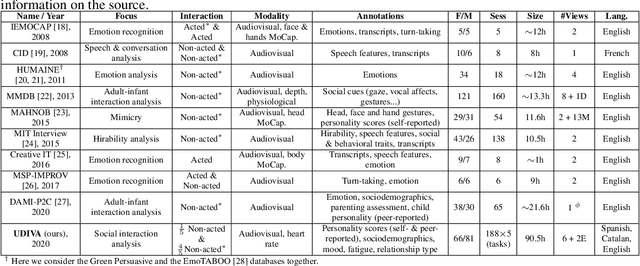


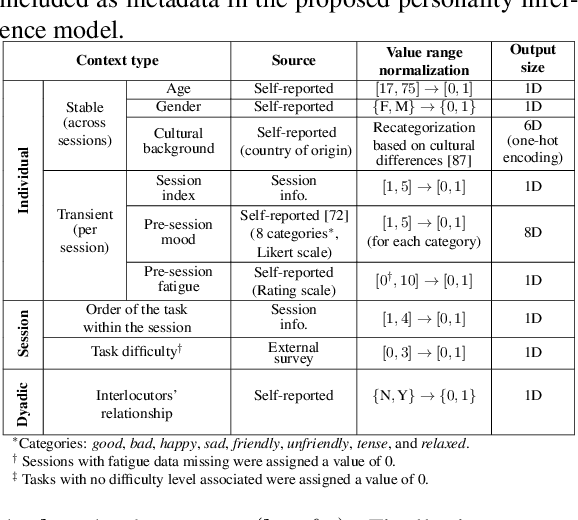
This paper introduces UDIVA, a new non-acted dataset of face-to-face dyadic interactions, where interlocutors perform competitive and collaborative tasks with different behavior elicitation and cognitive workload. The dataset consists of 90.5 hours of dyadic interactions among 147 participants distributed in 188 sessions, recorded using multiple audiovisual and physiological sensors. Currently, it includes sociodemographic, self- and peer-reported personality, internal state, and relationship profiling from participants. As an initial analysis on UDIVA, we propose a transformer-based method for self-reported personality inference in dyadic scenarios, which uses audiovisual data and different sources of context from both interlocutors to regress a target person's personality traits. Preliminary results from an incremental study show consistent improvements when using all available context information.
Recurrent CNN for 3D Gaze Estimation using Appearance and Shape Cues
Sep 17, 2018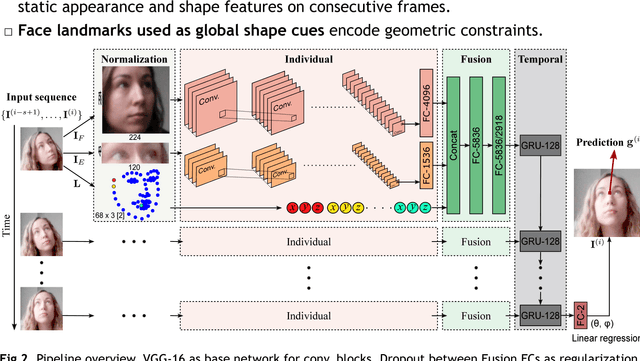

Gaze behavior is an important non-verbal cue in social signal processing and human-computer interaction. In this paper, we tackle the problem of person- and head pose-independent 3D gaze estimation from remote cameras, using a multi-modal recurrent convolutional neural network (CNN). We propose to combine face, eyes region, and face landmarks as individual streams in a CNN to estimate gaze in still images. Then, we exploit the dynamic nature of gaze by feeding the learned features of all the frames in a sequence to a many-to-one recurrent module that predicts the 3D gaze vector of the last frame. Our multi-modal static solution is evaluated on a wide range of head poses and gaze directions, achieving a significant improvement of 14.6% over the state of the art on EYEDIAP dataset, further improved by 4% when the temporal modality is included.
Folded Recurrent Neural Networks for Future Video Prediction
Mar 16, 2018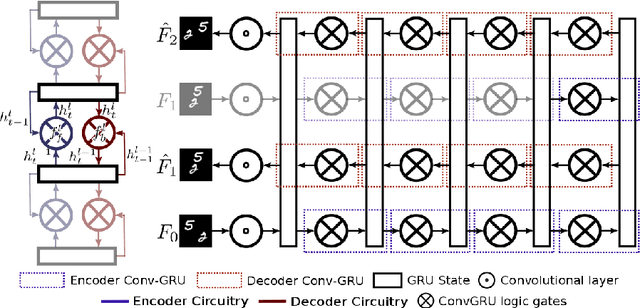

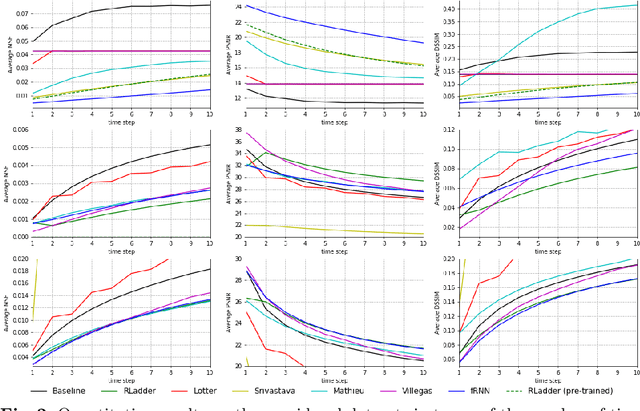
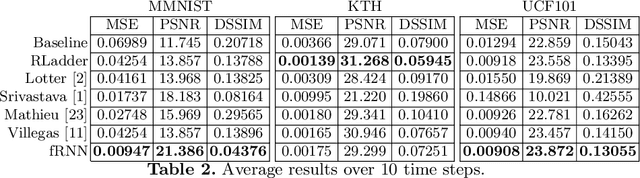
Future video prediction is an ill-posed Computer Vision problem that recently received much attention. Its main challenges are the high variability in video content, the propagation of errors through time, and the non-specificity of the future frames: given a sequence of past frames there is a continuous distribution of possible futures. This work introduces bijective Gated Recurrent Units, a double mapping between the input and output of a GRU layer. This allows for recurrent auto-encoders with state sharing between encoder and decoder, stratifying the sequence representation and helping to prevent capacity problems. We show how with this topology only the encoder or decoder needs to be applied for input encoding and prediction, respectively. This reduces the computational cost and avoids re-encoding the predictions when generating a sequence of frames, mitigating the propagation of errors. Furthermore, it is possible to remove layers from an already trained model, giving an insight to the role performed by each layer and making the model more explainable. We evaluate our approach on three video datasets, outperforming state of the art prediction results on MMNIST and UCF101, and obtaining competitive results on KTH with 2 and 3 times less memory usage and computational cost than the best scored approach.