 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Fast: Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models
Jun 05, 2026Many efforts to ensure frontier AI models are safe rely on monitoring their chain-of-thought (CoT) reasoning. If models become able to perform sufficiently complex reasoning internally, without explicit thinking tokens, this would undermine such oversight. We measure how well frontier models reason without CoT across a suite of over 30,000 questions spanning 43 benchmarks in domains including math, coding, puzzles, causality, theory-of-mind, and strategic reasoning. To compare models against humans, we estimate the $50\%$-task-completion time horizon (TH): the human time required for tasks a model completes with $50\%$ success rate. We complement this with a $50\%$ reasoning token horizon: the minimum number of o3-mini reasoning tokens needed for tasks a model solves with $50\%$ success rate. We find that the no-CoT $50\%$ TH of frontier models has been doubling roughly every year over the past six years, with GPT-5.5's TH reaching over 3 minutes and reasoning token horizon exceeding 1,500 tokens. Our median estimates predict that frontier no-CoT THs could exceed 7 minutes by 2028, and 25 minutes by 2030, though these projections carry substantial uncertainty. We recommend frontier developers track this explicitly.
Understanding Goal Generalisation in Sequential Reinforcement Learning
May 22, 2026Reinforcement learning agents often exhibit unintended goal-directed behaviour outside their training distribution, but we currently lack a principled understanding of how such agents will generalise to novel environments based on their training history. We address this gap for agents trained sequentially on one or more tasks. We study over 100 sequential training pipelines, evaluating behaviour across over 250 out-of-distribution environments. We find that salient features drive generalisation, and that goals learnt early in training can persist and influence those acquired later. To explain these phenomena, we introduce latent policy gradients, a method that predicts what out-of-distribution behaviour a training pipeline will likely induce. Our method simulates the evolution of low-dimensional latent variables during training according to what would achieve high reward on the training objective with respect to a simple model of how the latent variables map to behaviour. It achieves strong predictive accuracy, generalises to unseen types of training pipeline, and is interpretable. Our findings demonstrate that while out-of-distribution RL agent behaviour is dependent on the whole training pipeline, this dependence has an underlying structure we can capture, laying groundwork for understanding goal generalisation from a developmental perspective.
AgentMisalignment: Measuring the Propensity for Misaligned Behaviour in LLM-Based Agents
Jun 04, 2025As Large Language Model (LLM) agents become more widespread, associated misalignment risks increase. Prior work has examined agents' ability to enact misaligned behaviour (misalignment capability) and their compliance with harmful instructions (misuse propensity). However, the likelihood of agents attempting misaligned behaviours in real-world settings (misalignment propensity) remains poorly understood. We introduce a misalignment propensity benchmark, AgentMisalignment, consisting of a suite of realistic scenarios in which LLM agents have the opportunity to display misaligned behaviour. We organise our evaluations into subcategories of misaligned behaviours, including goal-guarding, resisting shutdown, sandbagging, and power-seeking. We report the performance of frontier models on our benchmark, observing higher misalignment on average when evaluating more capable models. Finally, we systematically vary agent personalities through different system prompts. We find that persona characteristics can dramatically and unpredictably influence misalignment tendencies -- occasionally far more than the choice of model itself -- highlighting the importance of careful system prompt engineering for deployed AI agents. Our work highlights the failure of current alignment methods to generalise to LLM agents, and underscores the need for further propensity evaluations as autonomous systems become more prevalent.
DARTFormer: Finding The Best Type Of Attention
Oct 02, 2022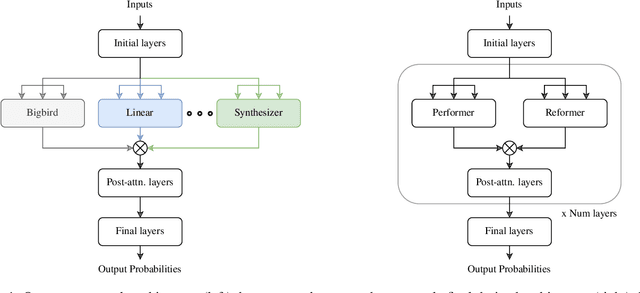
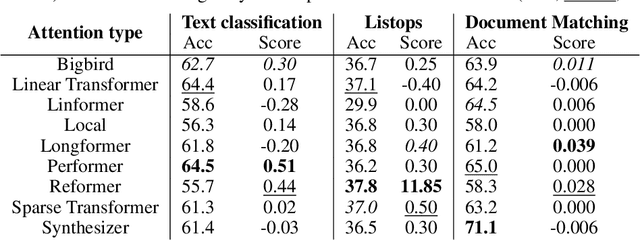
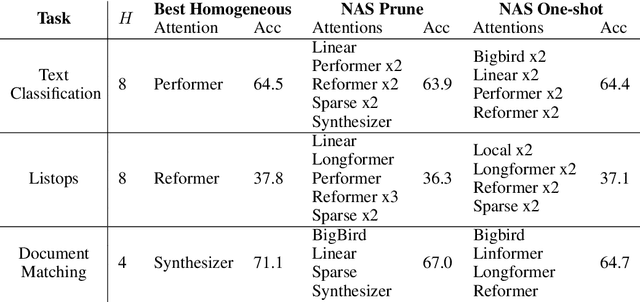
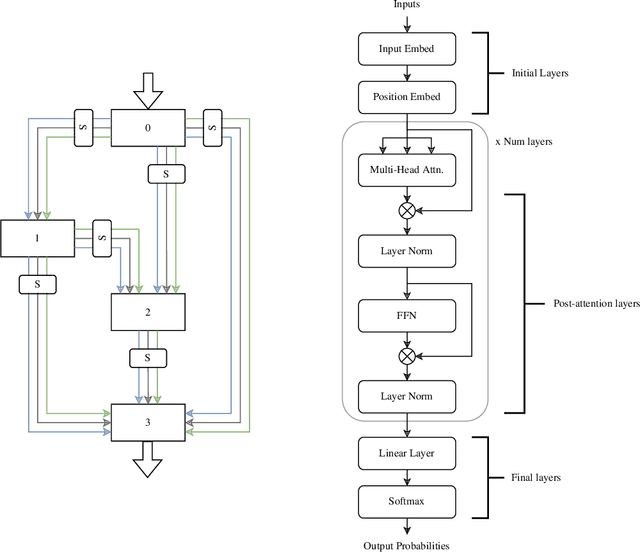
Given the wide and ever growing range of different efficient Transformer attention mechanisms, it is important to identify which attention is most effective when given a task. In this work, we are also interested in combining different attention types to build heterogeneous Transformers. We first propose a DARTS-like Neural Architecture Search (NAS) method to find the best attention for a given task, in this setup, all heads use the same attention (homogeneous models). Our results suggest that NAS is highly effective on this task, and it identifies the best attention mechanisms for IMDb byte level text classification and Listops. We then extend our framework to search for and build Transformers with multiple different attention types, and call them heterogeneous Transformers. We show that whilst these heterogeneous Transformers are better than the average homogeneous models, they cannot outperform the best. We explore the reasons why heterogeneous attention makes sense, and why it ultimately fails.
Wide Attention Is The Way Forward For Transformers
Oct 02, 2022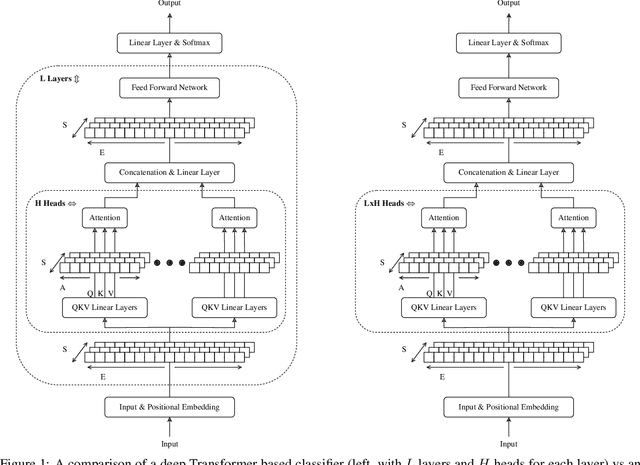

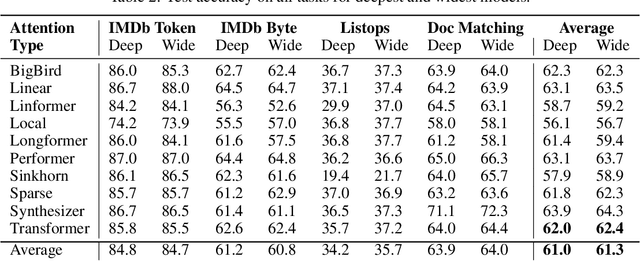
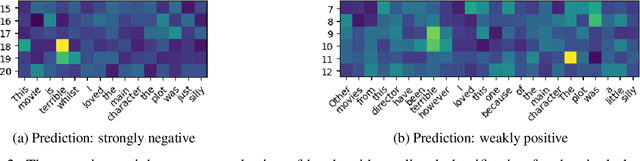
The Transformer is an extremely powerful and prominent deep learning architecture. In this work, we challenge the commonly held belief in deep learning that going deeper is better, and show an alternative design approach that is building wider attention Transformers. We demonstrate that wide single layer Transformer models can compete with or outperform deeper ones in a variety of Natural Language Processing (NLP) tasks when both are trained from scratch. The impact of changing the model aspect ratio on Transformers is then studied systematically. This ratio balances the number of layers and the number of attention heads per layer while keeping the total number of attention heads and all other hyperparameters constant. On average, across 4 NLP tasks and 10 attention types, single layer wide models perform 0.3% better than their deep counterparts. We show an in-depth evaluation and demonstrate how wide models require a far smaller memory footprint and can run faster on commodity hardware, in addition, these wider models are also more interpretable. For example, a single layer Transformer on the IMDb byte level text classification has 3.1x faster inference latency on a CPU than its equally accurate deeper counterpart, and is half the size. Our results suggest that the critical direction for building better Transformers for NLP is their width, and that their depth is less relevant.