 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks
Feb 28, 2023As the size of large language models continue to scale, so does the computational resources required to run it. Spiking neural networks (SNNs) have emerged as an energy-efficient approach to deep learning that leverage sparse and event-driven activations to reduce the computational overhead associated with model inference. While they have become competitive with non-spiking models on many computer vision tasks, SNNs have also proven to be more challenging to train. As a result, their performance lags behind modern deep learning, and we are yet to see the effectiveness of SNNs in language generation. In this paper, inspired by the RWKV language model, we successfully implement `SpikeGPT', a generative language model with pure binary, event-driven spiking activation units. We train the proposed model on three model variants: 45M, 125M and 260M parameters. To the best of our knowledge, this is 4x larger than any functional backprop-trained SNN to date. We achieve this by modifying the transformer block to replace multi-head self attention to reduce quadratic computational complexity to linear with increasing sequence length. Input tokens are instead streamed in sequentially to our attention mechanism (as with typical SNNs). Our preliminary experiments show that SpikeGPT remains competitive with non-spiking models on tested benchmarks, while maintaining 5x less energy consumption when processed on neuromorphic hardware that can leverage sparse, event-driven activations. Our code implementation is available at https://github.com/ridgerchu/SpikeGPT.
OpenSpike: An OpenRAM SNN Accelerator
Feb 02, 2023This paper presents a spiking neural network (SNN) accelerator made using fully open-source EDA tools, process design kit (PDK), and memory macros synthesized using OpenRAM. The chip is taped out in the 130 nm SkyWater process and integrates over 1 million synaptic weights, and offers a reprogrammable architecture. It operates at a clock speed of 40 MHz, a supply of 1.8 V, uses a PicoRV32 core for control, and occupies an area of 33.3 mm^2. The throughput of the accelerator is 48,262 images per second with a wallclock time of 20.72 us, at 56.8 GOPS/W. The spiking neurons use hysteresis to provide an adaptive threshold (i.e., a Schmitt trigger) which can reduce state instability. This results in high performing SNNs across a range of benchmarks that remain competitive with state-of-the-art, full precision SNNs. The design is open sourced and available online: https://github.com/sfmth/OpenSpike
Intelligence Processing Units Accelerate Neuromorphic Learning
Nov 19, 2022



Spiking neural networks (SNNs) have achieved orders of magnitude improvement in terms of energy consumption and latency when performing inference with deep learning workloads. Error backpropagation is presently regarded as the most effective method for training SNNs, but in a twist of irony, when training on modern graphics processing units (GPUs) this becomes more expensive than non-spiking networks. The emergence of Graphcore's Intelligence Processing Units (IPUs) balances the parallelized nature of deep learning workloads with the sequential, reusable, and sparsified nature of operations prevalent when training SNNs. IPUs adopt multi-instruction multi-data (MIMD) parallelism by running individual processing threads on smaller data blocks, which is a natural fit for the sequential, non-vectorized steps required to solve spiking neuron dynamical state equations. We present an IPU-optimized release of our custom SNN Python package, snnTorch, which exploits fine-grained parallelism by utilizing low-level, pre-compiled custom operations to accelerate irregular and sparse data access patterns that are characteristic of training SNN workloads. We provide a rigorous performance assessment across a suite of commonly used spiking neuron models, and propose methods to further reduce training run-time via half-precision training. By amortizing the cost of sequential processing into vectorizable population codes, we ultimately demonstrate the potential for integrating domain-specific accelerators with the next generation of neural networks.
Spiking neural network for nonlinear regression
Oct 06, 2022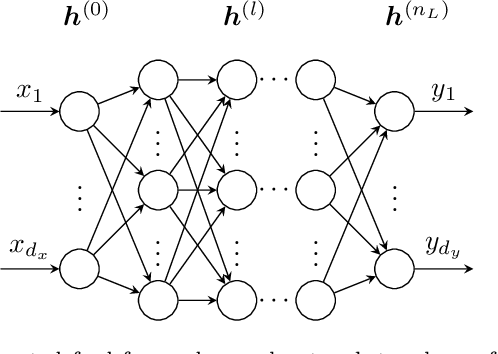
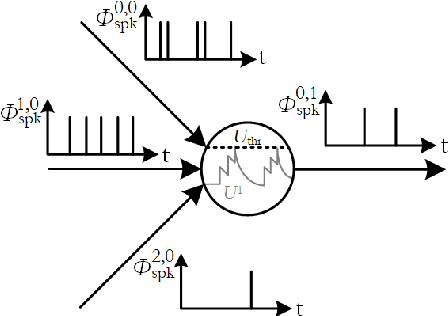
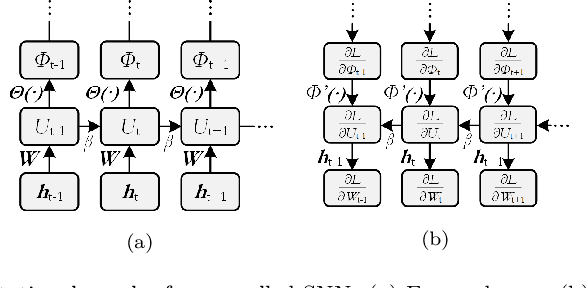
Spiking neural networks, also often referred to as the third generation of neural networks, carry the potential for a massive reduction in memory and energy consumption over traditional, second-generation neural networks. Inspired by the undisputed efficiency of the human brain, they introduce temporal and neuronal sparsity, which can be exploited by next-generation neuromorphic hardware. To open the pathway toward engineering applications, we introduce this exciting technology in the context of continuum mechanics. However, the nature of spiking neural networks poses a challenge for regression problems, which frequently arise in the modeling of engineering sciences. To overcome this problem, a framework for regression using spiking neural networks is proposed. In particular, a network topology for decoding binary spike trains to real numbers is introduced, utilizing the membrane potential of spiking neurons. As the aim of this contribution is a concise introduction to this new methodology, several different spiking neural architectures, ranging from simple spiking feed-forward to complex spiking long short-term memory neural networks, are derived. Several numerical experiments directed towards regression of linear and nonlinear, history-dependent material models are carried out. A direct comparison with counterparts of traditional neural networks shows that the proposed framework is much more efficient while retaining precision and generalizability. All code has been made publicly available in the interest of reproducibility and to promote continued enhancement in this new domain.
Gradient-based Neuromorphic Learning on Dynamical RRAM Arrays
Jun 26, 2022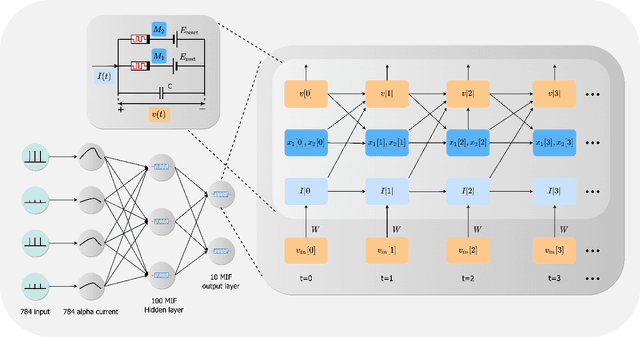
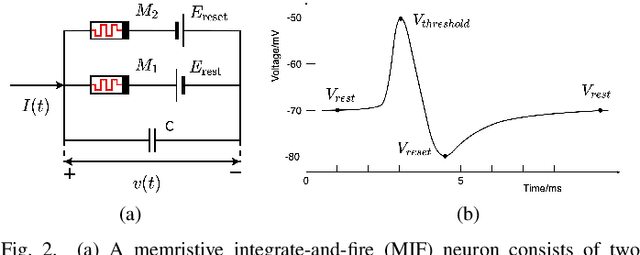
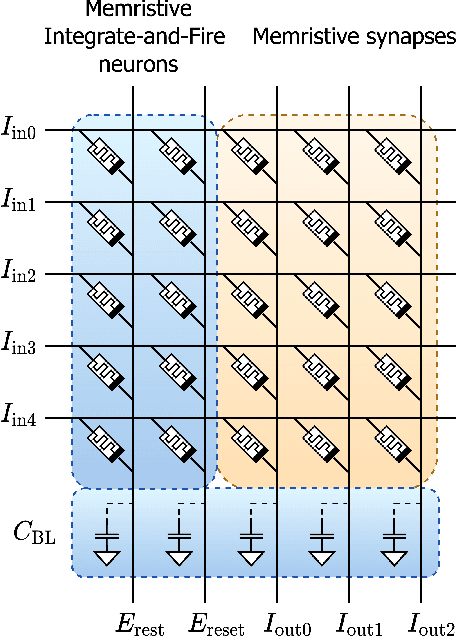
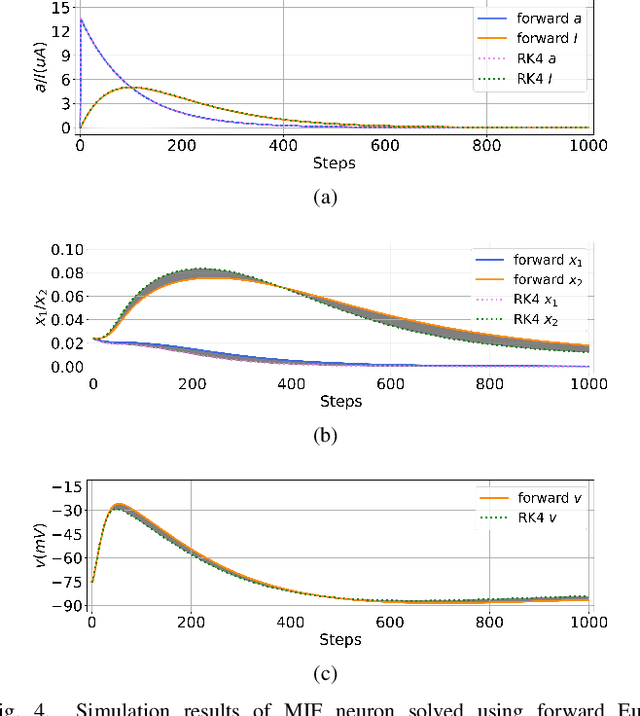
We present MEMprop, the adoption of gradient-based learning to train fully memristive spiking neural networks (MSNNs). Our approach harnesses intrinsic device dynamics to trigger naturally arising voltage spikes. These spikes emitted by memristive dynamics are analog in nature, and thus fully differentiable, which eliminates the need for surrogate gradient methods that are prevalent in the spiking neural network (SNN) literature. Memristive neural networks typically either integrate memristors as synapses that map offline-trained networks, or otherwise rely on associative learning mechanisms to train networks of memristive neurons. We instead apply the backpropagation through time (BPTT) training algorithm directly on analog SPICE models of memristive neurons and synapses. Our implementation is fully memristive, in that synaptic weights and spiking neurons are both integrated on resistive RAM (RRAM) arrays without the need for additional circuits to implement spiking dynamics, e.g., analog-to-digital converters (ADCs) or thresholded comparators. As a result, higher-order electrophysical effects are fully exploited to use the state-driven dynamics of memristive neurons at run time. By moving towards non-approximate gradient-based learning, we obtain highly competitive accuracy amongst previously reported lightweight dense fully MSNNs on several benchmarks.
A Fully Memristive Spiking Neural Network with Unsupervised Learning
Mar 10, 2022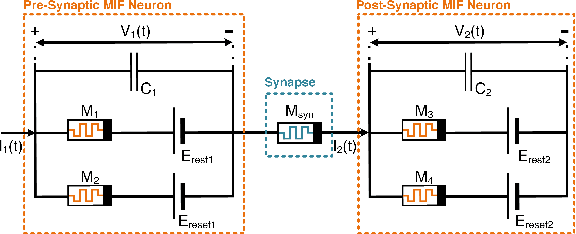
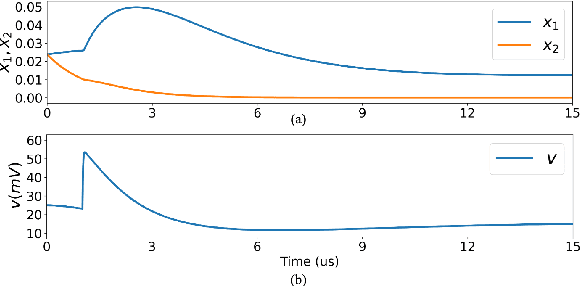
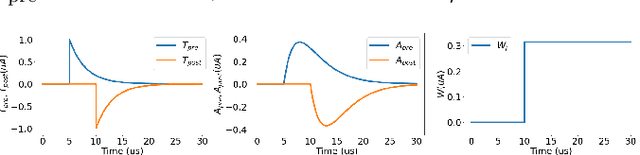
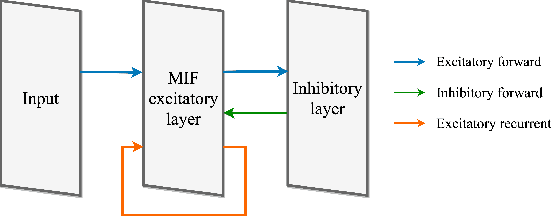
We present a fully memristive spiking neural network (MSNN) consisting of physically-realizable memristive neurons and memristive synapses to implement an unsupervised Spiking Time Dependent Plasticity (STDP) learning rule. The system is fully memristive in that both neuronal and synaptic dynamics can be realized by using memristors. The neuron is implemented using the SPICE-level memristive integrate-and-fire (MIF) model, which consists of a minimal number of circuit elements necessary to achieve distinct depolarization, hyperpolarization, and repolarization voltage waveforms. The proposed MSNN uniquely implements STDP learning by using cumulative weight changes in memristive synapses from the voltage waveform changes across the synapses, which arise from the presynaptic and postsynaptic spiking voltage signals during the training process. Two types of MSNN architectures are investigated: 1) a biologically plausible memory retrieval system, and 2) a multi-class classification system. Our circuit simulation results verify the MSNN's unsupervised learning efficacy by replicating biological memory retrieval mechanisms, and achieving 97.5% accuracy in a 4-pattern recognition problem in a large scale discriminative MSNN.
SPICEprop: Backpropagating Errors Through Memristive Spiking Neural Networks
Mar 10, 2022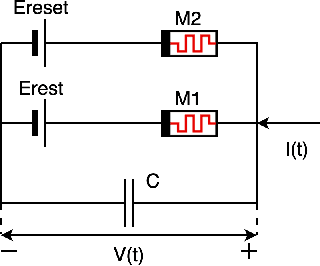
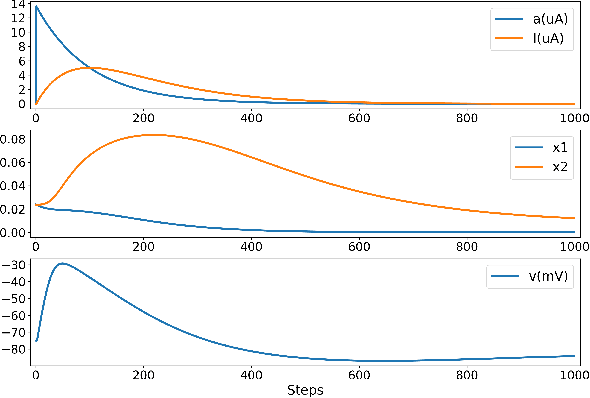
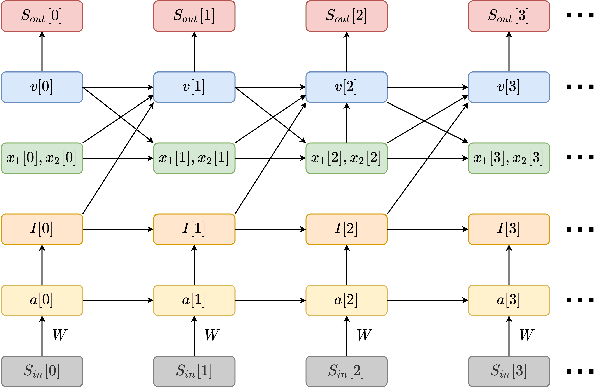
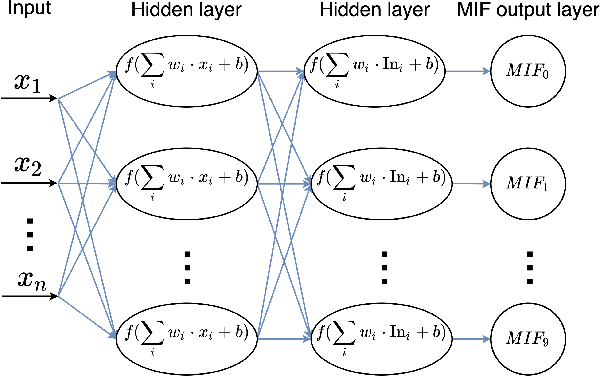
We present a fully memristive spiking neural network (MSNN) consisting of novel memristive neurons trained using the backpropagation through time (BPTT) learning rule. Gradient descent is applied directly to the memristive integrated-and-fire (MIF) neuron designed using analog SPICE circuit models, which generates distinct depolarization, hyperpolarization, and repolarization voltage waveforms. Synaptic weights are trained by BPTT using the membrane potential of the MIF neuron model and can be processed on memristive crossbars. The natural spiking dynamics of the MIF neuron model are fully differentiable, eliminating the need for gradient approximations that are prevalent in the spiking neural network literature. Despite the added complexity of training directly on SPICE circuit models, we achieve 97.58% accuracy on the MNIST testing dataset and 75.26% on the Fashion-MNIST testing dataset, the highest accuracies among all fully MSNNs.
Navigating Local Minima in Quantized Spiking Neural Networks
Feb 15, 2022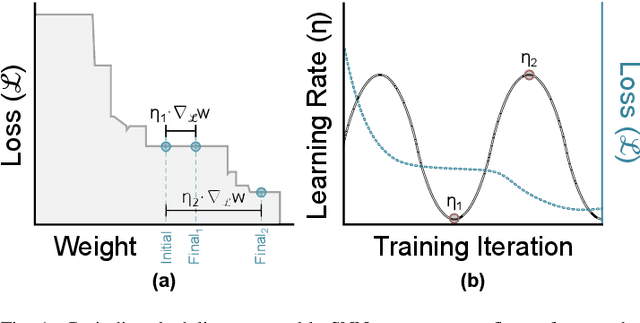
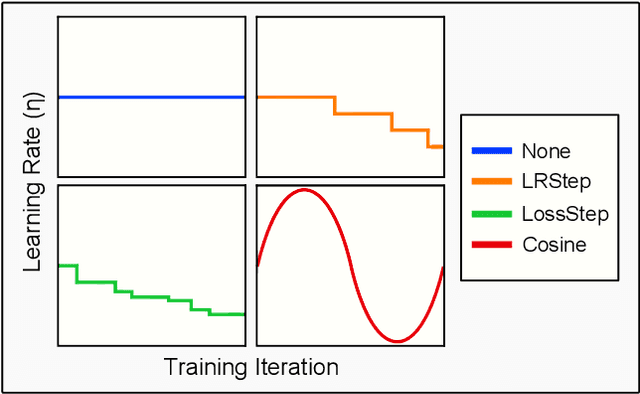
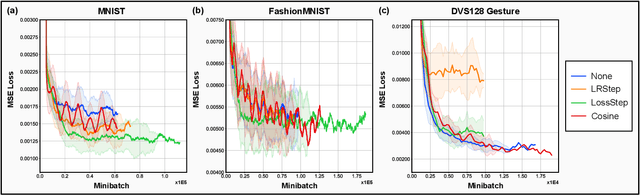
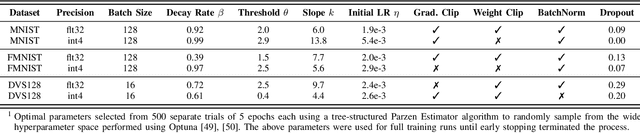
Spiking and Quantized Neural Networks (NNs) are becoming exceedingly important for hyper-efficient implementations of Deep Learning (DL) algorithms. However, these networks face challenges when trained using error backpropagation, due to the absence of gradient signals when applying hard thresholds. The broadly accepted trick to overcoming this is through the use of biased gradient estimators: surrogate gradients which approximate thresholding in Spiking Neural Networks (SNNs), and Straight-Through Estimators (STEs), which completely bypass thresholding in Quantized Neural Networks (QNNs). While noisy gradient feedback has enabled reasonable performance on simple supervised learning tasks, it is thought that such noise increases the difficulty of finding optima in loss landscapes, especially during the later stages of optimization. By periodically boosting the Learning Rate (LR) during training, we expect the network can navigate unexplored solution spaces that would otherwise be difficult to reach due to local minima, barriers, or flat surfaces. This paper presents a systematic evaluation of a cosine-annealed LR schedule coupled with weight-independent adaptive moment estimation as applied to Quantized SNNs (QSNNs). We provide a rigorous empirical evaluation of this technique on high precision and 4-bit quantized SNNs across three datasets, demonstrating (close to) state-of-the-art performance on the more complex datasets. Our source code is available at this link: https://github.com/jeshraghian/QSNNs.
The fine line between dead neurons and sparsity in binarized spiking neural networks
Jan 28, 2022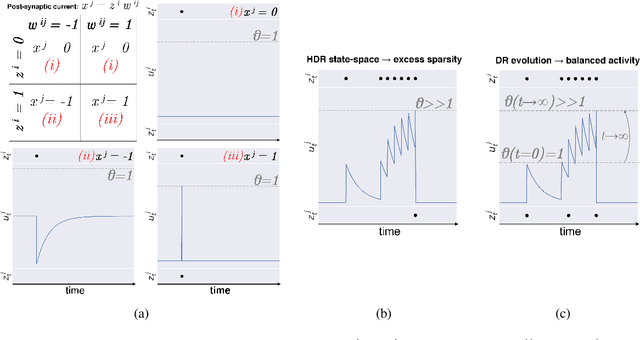
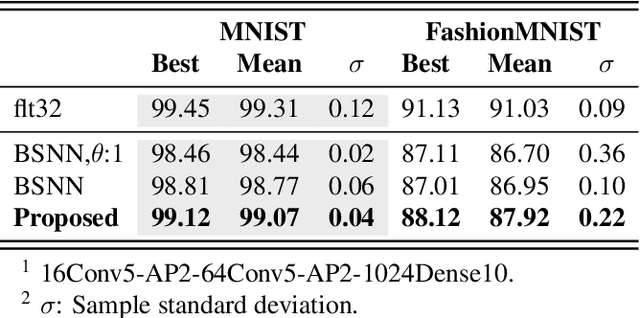
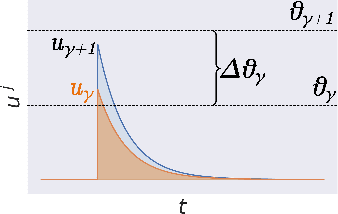
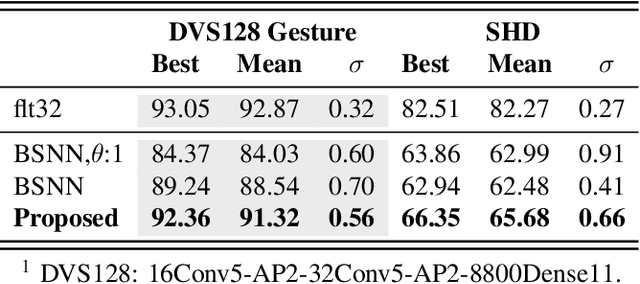
Spiking neural networks can compensate for quantization error by encoding information either in the temporal domain, or by processing discretized quantities in hidden states of higher precision. In theory, a wide dynamic range state-space enables multiple binarized inputs to be accumulated together, thus improving the representational capacity of individual neurons. This may be achieved by increasing the firing threshold, but make it too high and sparse spike activity turns into no spike emission. In this paper, we propose the use of `threshold annealing' as a warm-up method for firing thresholds. We show it enables the propagation of spikes across multiple layers where neurons would otherwise cease to fire, and in doing so, achieve highly competitive results on four diverse datasets, despite using binarized weights. Source code is available at https://github.com/jeshraghian/snn-tha/
Design Space Exploration of Dense and Sparse Mapping Schemes for RRAM Architectures
Jan 25, 2022The impact of device and circuit-level effects in mixed-signal Resistive Random Access Memory (RRAM) accelerators typically manifest as performance degradation of Deep Learning (DL) algorithms, but the degree of impact varies based on algorithmic features. These include network architecture, capacity, weight distribution, and the type of inter-layer connections. Techniques are continuously emerging to efficiently train sparse neural networks, which may have activation sparsity, quantization, and memristive noise. In this paper, we present an extended Design Space Exploration (DSE) methodology to quantify the benefits and limitations of dense and sparse mapping schemes for a variety of network architectures. While sparsity of connectivity promotes less power consumption and is often optimized for extracting localized features, its performance on tiled RRAM arrays may be more susceptible to noise due to under-parameterization, when compared to dense mapping schemes. Moreover, we present a case study quantifying and formalizing the trade-offs of typical non-idealities introduced into 1-Transistor-1-Resistor (1T1R) tiled memristive architectures and the size of modular crossbar tiles using the CIFAR-10 dataset.