 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Subset Tuning: Expanding the Operational Range of Parameter-Efficient Training for Large Language Models
Nov 13, 2024



We propose a novel parameter-efficient training (PET) method for large language models that adapts models to downstream tasks by optimizing a small subset of the existing model parameters. Unlike prior methods, this subset is not fixed in location but rather which parameters are modified evolves over the course of training. This dynamic parameter selection can yield good performance with many fewer parameters than extant methods. Our method enables a seamless scaling of the subset size across an arbitrary proportion of the total model size, while popular PET approaches like prompt tuning and LoRA cover only a small part of this spectrum. We match or outperform prompt tuning and LoRA in most cases on a variety of NLP tasks (MT, QA, GSM8K, SuperGLUE) for a given parameter budget across different model families and sizes.
Heterogeneous Federated Learning Using Knowledge Codistillation
Oct 04, 2023



Federated Averaging, and many federated learning algorithm variants which build upon it, have a limitation: all clients must share the same model architecture. This results in unused modeling capacity on many clients, which limits model performance. To address this issue, we propose a method that involves training a small model on the entire pool and a larger model on a subset of clients with higher capacity. The models exchange information bidirectionally via knowledge distillation, utilizing an unlabeled dataset on a server without sharing parameters. We present two variants of our method, which improve upon federated averaging on image classification and language modeling tasks. We show this technique can be useful even if only out-of-domain or limited in-domain distillation data is available. Additionally, the bi-directional knowledge distillation allows for domain transfer between the models when different pool populations introduce domain shift.
Simple and Effective Gradient-Based Tuning of Sequence-to-Sequence Models
Sep 10, 2022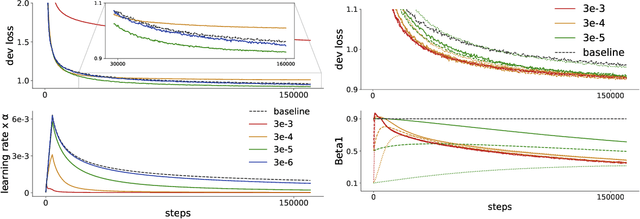
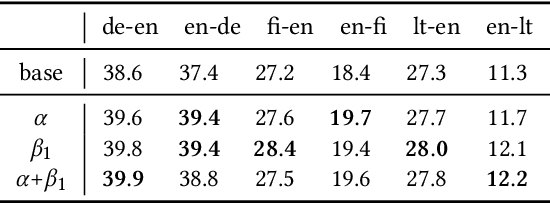
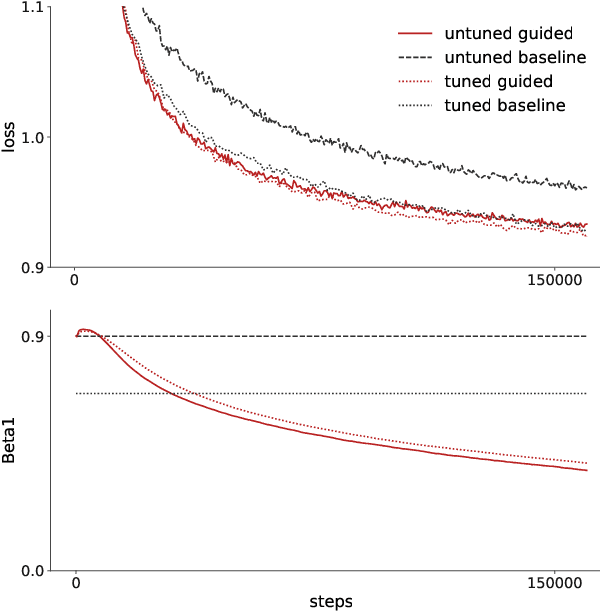
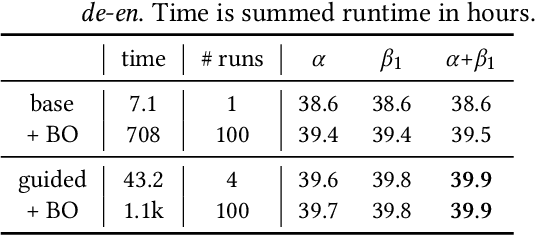
Recent trends towards training ever-larger language models have substantially improved machine learning performance across linguistic tasks. However, the huge cost of training larger models can make tuning them prohibitively expensive, motivating the study of more efficient methods. Gradient-based hyper-parameter optimization offers the capacity to tune hyper-parameters during training, yet has not previously been studied in a sequence-to-sequence setting. We apply a simple and general gradient-based hyperparameter optimization method to sequence-to-sequence tasks for the first time, demonstrating both efficiency and performance gains over strong baselines for both Neural Machine Translation and Natural Language Understanding (NLU) tasks (via T5 pretraining). For translation, we show the method generalizes across language pairs, is more efficient than Bayesian hyper-parameter optimization, and that learned schedules for some hyper-parameters can out-perform even optimal constant-valued tuning. For T5, we show that learning hyper-parameters during pretraining can improve performance across downstream NLU tasks. When learning multiple hyper-parameters concurrently, we show that the global learning rate can follow a schedule over training that improves performance and is not explainable by the `short-horizon bias' of greedy methods \citep{wu2018}. We release the code used to facilitate further research.
Data Weighted Training Strategies for Grammatical Error Correction
Sep 09, 2020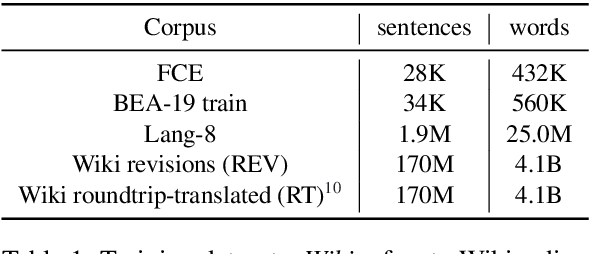
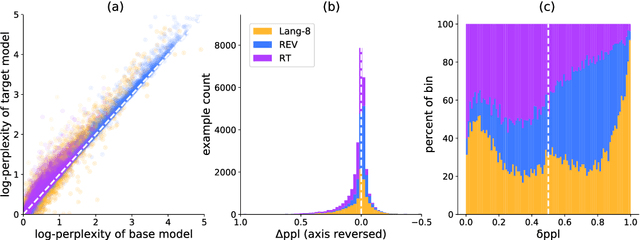
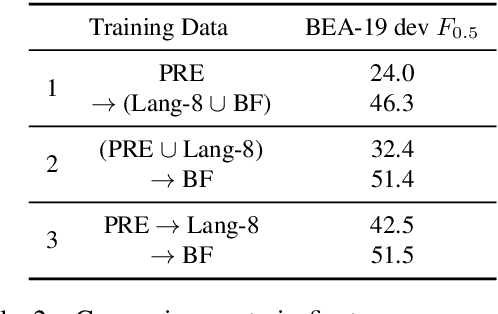
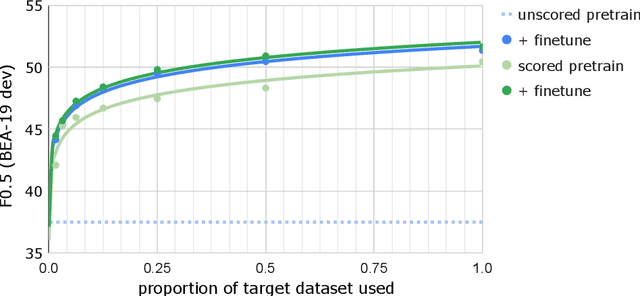
Recent progress in the task of Grammatical Error Correction (GEC) has been driven by addressing data sparsity, both through new methods for generating large and noisy pretraining data and through the publication of small and higher-quality finetuning data in the BEA-2019 shared task. Building upon recent work in Neural Machine Translation (NMT), we make use of both kinds of data by deriving example-level scores on our large pretraining data based on a smaller, higher-quality dataset. In this work, we perform an empirical study to discover how to best incorporate delta-log-perplexity, a type of example scoring, into a training schedule for GEC. In doing so, we perform experiments that shed light on the function and applicability of delta-log-perplexity. Models trained on scored data achieve state-of-the-art results on common GEC test sets.
Corpora Generation for Grammatical Error Correction
Apr 10, 2019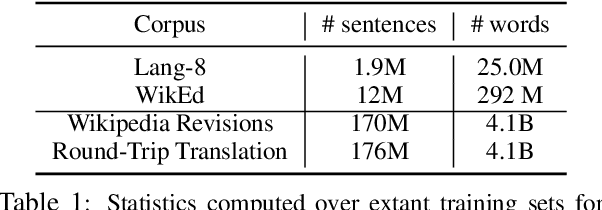
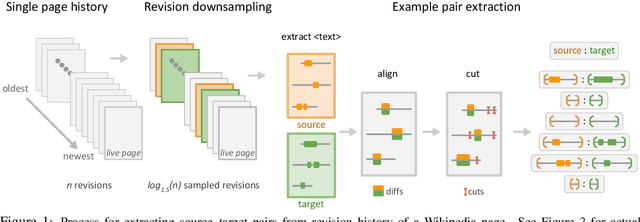
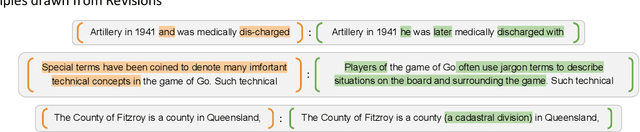

Grammatical Error Correction (GEC) has been recently modeled using the sequence-to-sequence framework. However, unlike sequence transduction problems such as machine translation, GEC suffers from the lack of plentiful parallel data. We describe two approaches for generating large parallel datasets for GEC using publicly available Wikipedia data. The first method extracts source-target pairs from Wikipedia edit histories with minimal filtration heuristics, while the second method introduces noise into Wikipedia sentences via round-trip translation through bridge languages. Both strategies yield similar sized parallel corpora containing around 4B tokens. We employ an iterative decoding strategy that is tailored to the loosely supervised nature of our constructed corpora. We demonstrate that neural GEC models trained using either type of corpora give similar performance. Fine-tuning these models on the Lang-8 corpus and ensembling allows us to surpass the state of the art on both the CoNLL-2014 benchmark and the JFLEG task. We provide systematic analysis that compares the two approaches to data generation and highlights the effectiveness of ensembling.
Weakly Supervised Grammatical Error Correction using Iterative Decoding
Oct 31, 2018
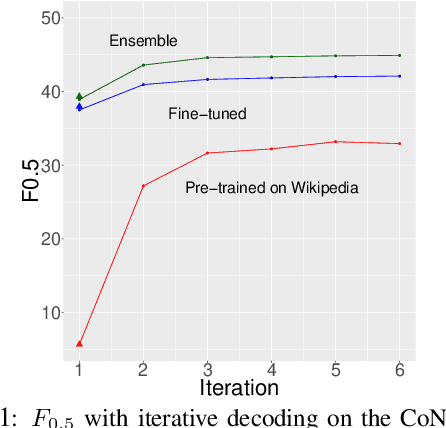
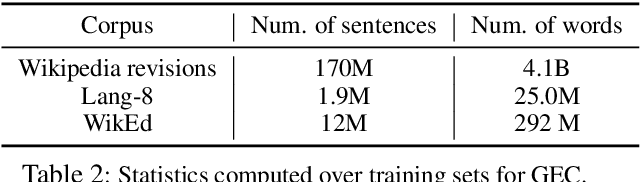

We describe an approach to Grammatical Error Correction (GEC) that is effective at making use of models trained on large amounts of weakly supervised bitext. We train the Transformer sequence-to-sequence model on 4B tokens of Wikipedia revisions and employ an iterative decoding strategy that is tailored to the loosely-supervised nature of the Wikipedia training corpus. Finetuning on the Lang-8 corpus and ensembling yields an F0.5 of 58.3 on the CoNLL'14 benchmark and a GLEU of 62.4 on JFLEG. The combination of weakly supervised training and iterative decoding obtains an F0.5 of 48.2 on CoNLL'14 even without using any labeled GEC data.