 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Normalization of Temporal Expressions with Masked Language Models
May 20, 2022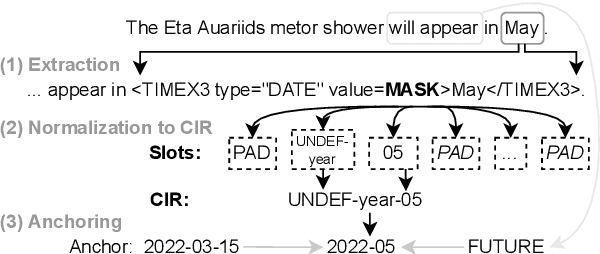
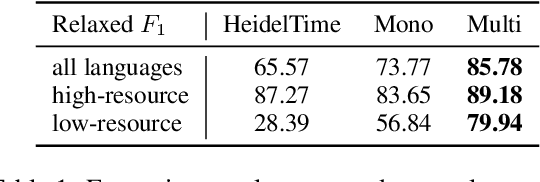
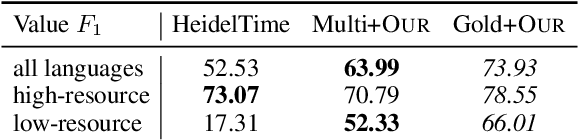
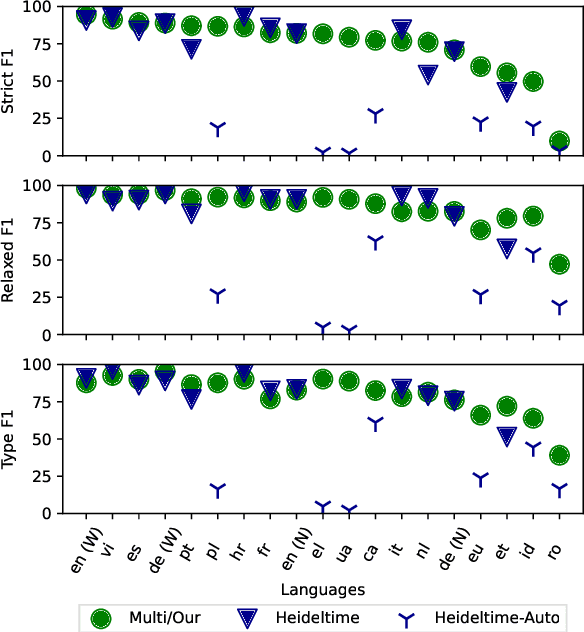
The detection and normalization of temporal expressions is an important task and a preprocessing step for many applications. However, prior work on normalization is rule-based, which severely limits the applicability in real-world multilingual settings, due to the costly creation of new rules. We propose a novel neural method for normalizing temporal expressions based on masked language modeling. Our multilingual method outperforms prior rule-based systems in many languages, and in particular, for low-resource languages with performance improvements of up to 35 F1 on average compared to the state of the art.
CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain
Dec 17, 2021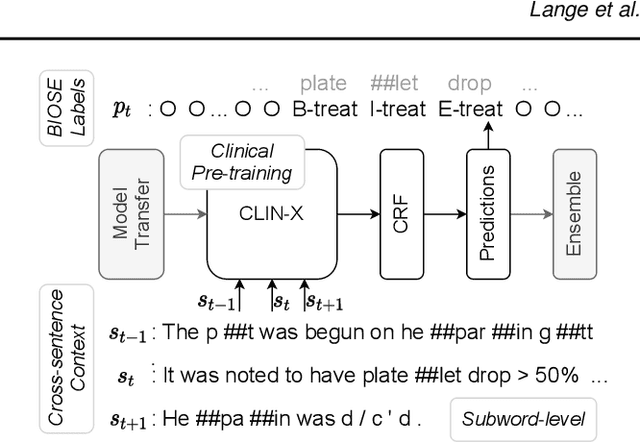
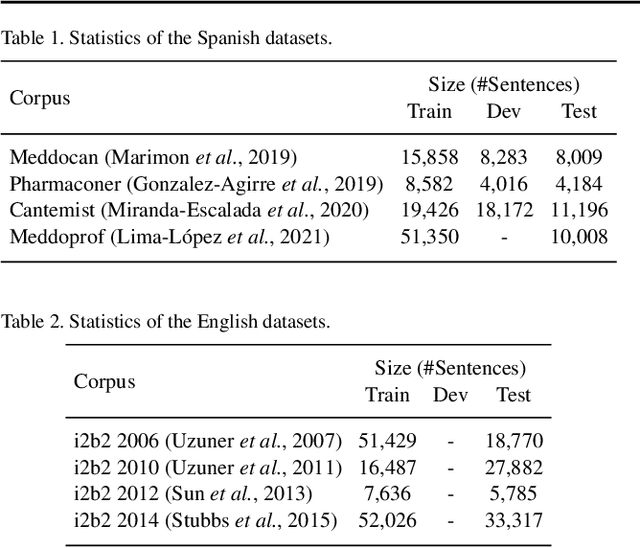
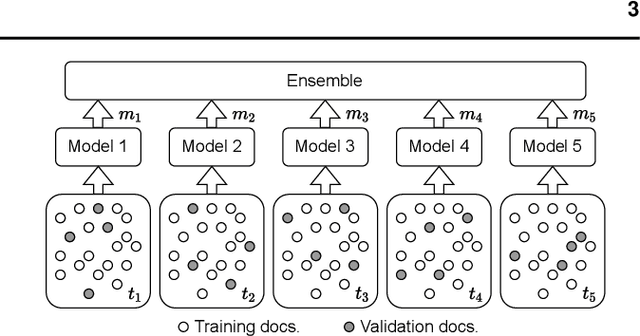
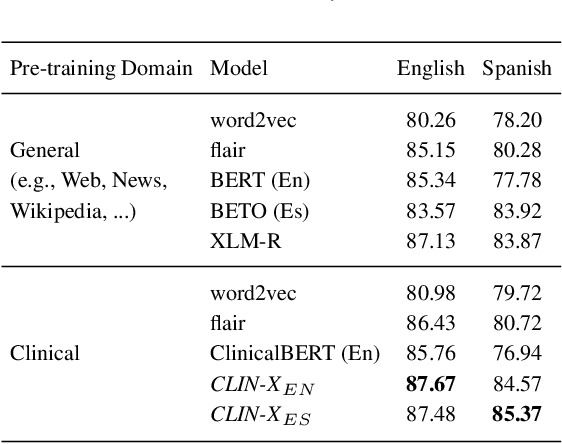
The field of natural language processing (NLP) has recently seen a large change towards using pre-trained language models for solving almost any task. Despite showing great improvements in benchmark datasets for various tasks, these models often perform sub-optimal in non-standard domains like the clinical domain where a large gap between pre-training documents and target documents is observed. In this paper, we aim at closing this gap with domain-specific training of the language model and we investigate its effect on a diverse set of downstream tasks and settings. We introduce the pre-trained CLIN-X (Clinical XLM-R) language models and show how CLIN-X outperforms other pre-trained transformer models by a large margin for ten clinical concept extraction tasks from two languages. In addition, we demonstrate how the transformer model can be further improved with our proposed task- and language-agnostic model architecture based on ensembles over random splits and cross-sentence context. Our studies in low-resource and transfer settings reveal stable model performance despite a lack of annotated data with improvements of up to 47 F1 points when only 250 labeled sentences are available. Our results highlight the importance of specialized language models as CLIN-X for concept extraction in non-standard domains, but also show that our task-agnostic model architecture is robust across the tested tasks and languages so that domain- or task-specific adaptations are not required.
Boosting Transformers for Job Expression Extraction and Classification in a Low-Resource Setting
Sep 17, 2021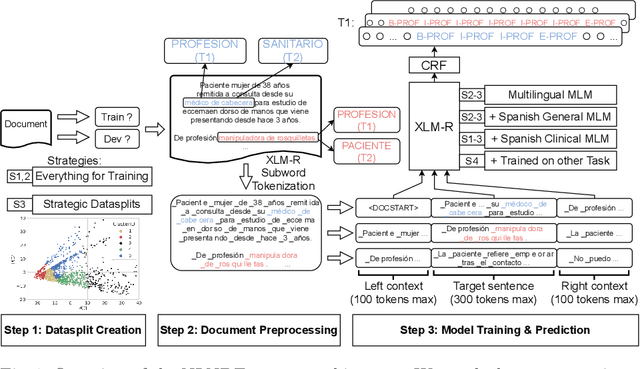
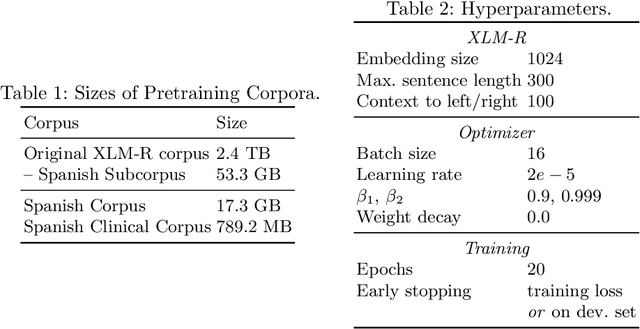
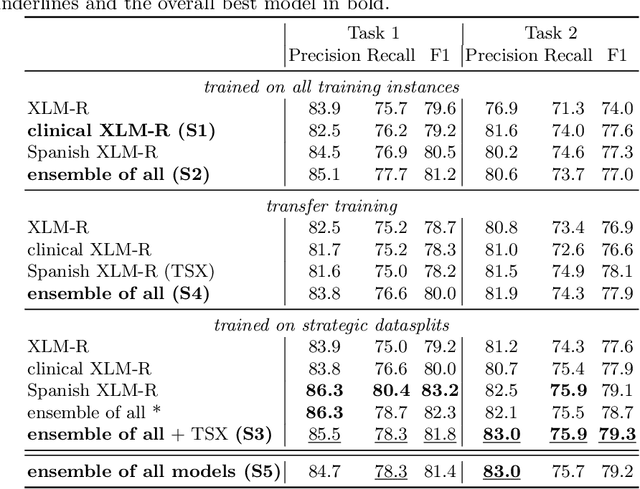
In this paper, we explore possible improvements of transformer models in a low-resource setting. In particular, we present our approaches to tackle the first two of three subtasks of the MEDDOPROF competition, i.e., the extraction and classification of job expressions in Spanish clinical texts. As neither language nor domain experts, we experiment with the multilingual XLM-R transformer model and tackle these low-resource information extraction tasks as sequence-labeling problems. We explore domain- and language-adaptive pretraining, transfer learning and strategic datasplits to boost the transformer model. Our results show strong improvements using these methods by up to 5.3 F1 points compared to a fine-tuned XLM-R model. Our best models achieve 83.2 and 79.3 F1 for the first two tasks, respectively.
Enriched Attention for Robust Relation Extraction
Apr 22, 2021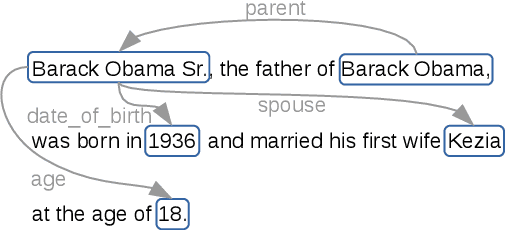

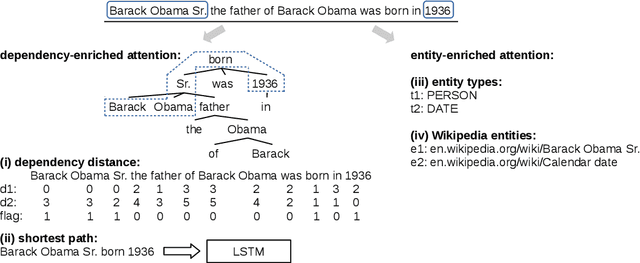
The performance of relation extraction models has increased considerably with the rise of neural networks. However, a key issue of neural relation extraction is robustness: the models do not scale well to long sentences with multiple entities and relations. In this work, we address this problem with an enriched attention mechanism. Attention allows the model to focus on parts of the input sentence that are relevant to relation extraction. We propose to enrich the attention function with features modeling knowledge about the relation arguments and the shortest dependency path between them. Thus, for different relation arguments, the model can pay attention to different parts of the sentence. Our model outperforms prior work using comparable setups on two popular benchmarks, and our analysis confirms that it indeed scales to long sentences with many entities.
To Share or not to Share: Predicting Sets of Sources for Model Transfer Learning
Apr 16, 2021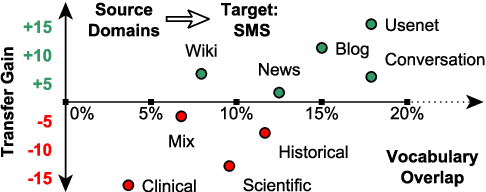
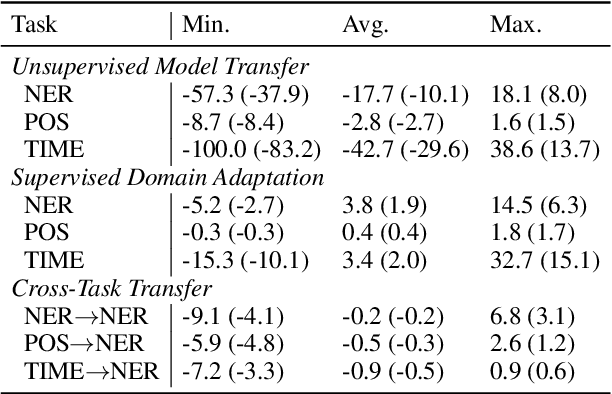
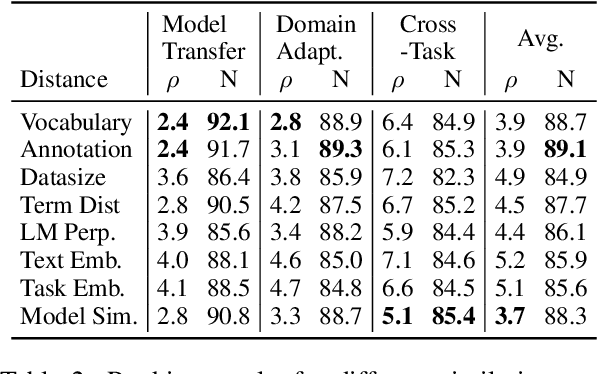
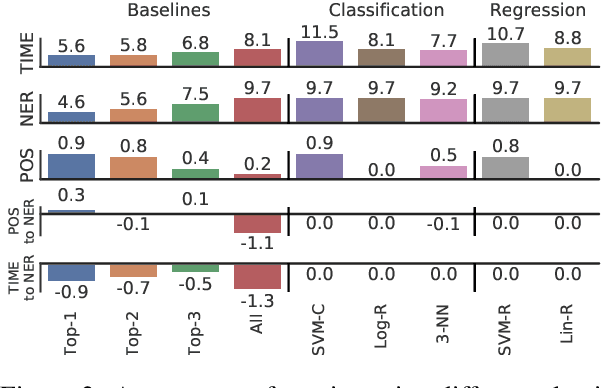
In low-resource settings, model transfer can help to overcome a lack of labeled data for many tasks and domains. However, predicting useful transfer sources is a challenging problem, as even the most similar sources might lead to unexpected negative transfer results. Thus, ranking methods based on task and text similarity may not be sufficient to identify promising sources. To tackle this problem, we propose a method to automatically determine which and how many sources should be exploited. For this, we study the effects of model transfer on sequence labeling across various domains and tasks and show that our methods based on model similarity and support vector machines are able to predict promising sources, resulting in performance increases of up to 24 F1 points.
NLNDE at CANTEMIST: Neural Sequence Labeling and Parsing Approaches for Clinical Concept Extraction
Oct 23, 2020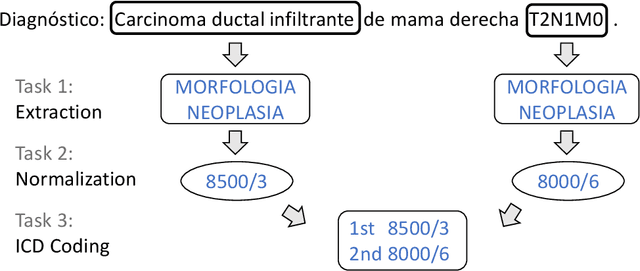

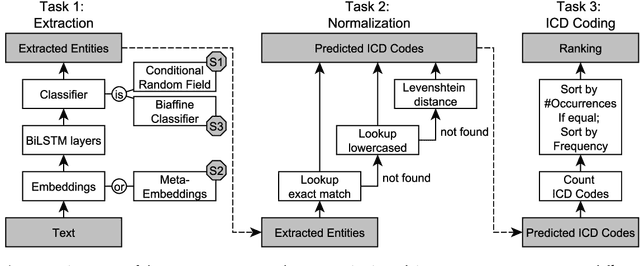

The recognition and normalization of clinical information, such as tumor morphology mentions, is an important, but complex process consisting of multiple subtasks. In this paper, we describe our system for the CANTEMIST shared task, which is able to extract, normalize and rank ICD codes from Spanish electronic health records using neural sequence labeling and parsing approaches with context-aware embeddings. Our best system achieves 85.3 F1, 76.7 F1, and 77.0 MAP for the three tasks, respectively.
A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios
Oct 23, 2020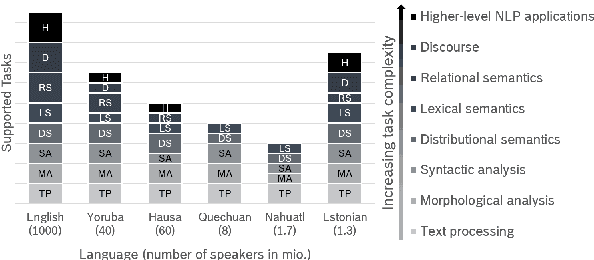
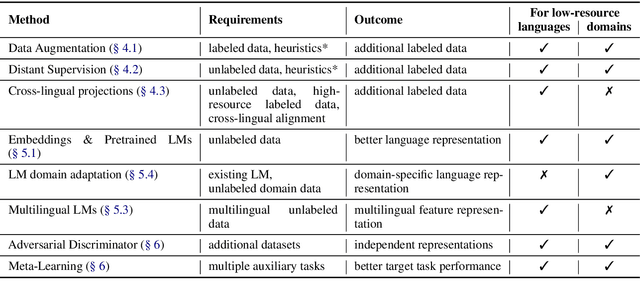

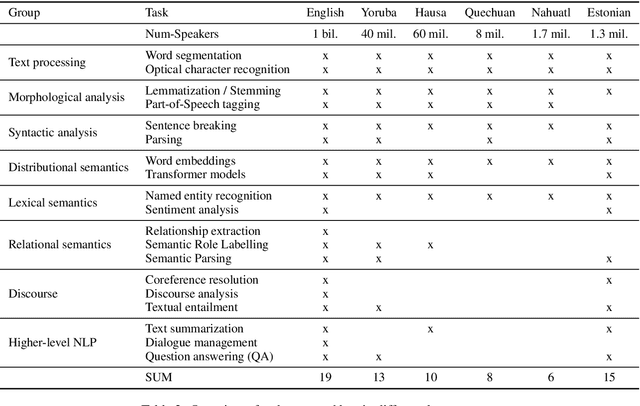
Current developments in natural language processing offer challenges and opportunities for low-resource languages and domains. Deep neural networks are known for requiring large amounts of training data which might not be available in resource-lean scenarios. However, there is also a growing body of works to improve the performance in low-resource settings. Motivated by fundamental changes towards neural models and the currently popular pre-train and fine-tune paradigm, we give an overview of promising approaches for low-resource natural language processing. After a discussion about the definition of low-resource scenarios and the different dimensions of data availability, we then examine methods that enable learning when training data is sparse. This includes mechanisms to create additional labeled data like data augmentation and distant supervision as well as transfer learning settings that reduce the need for target supervision. The survey closes with a brief look into methods suggested in non-NLP machine learning communities, which might be beneficial for NLP in low-resource scenarios
Adversarial Learning of Feature-based Meta-Embeddings
Oct 23, 2020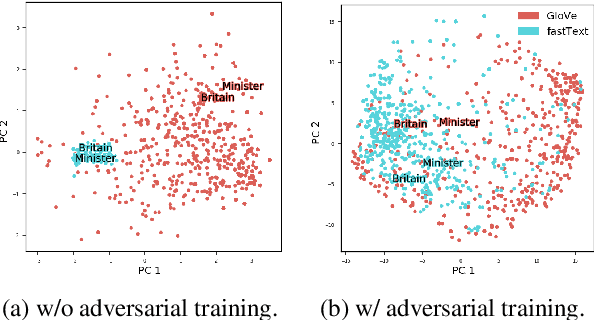
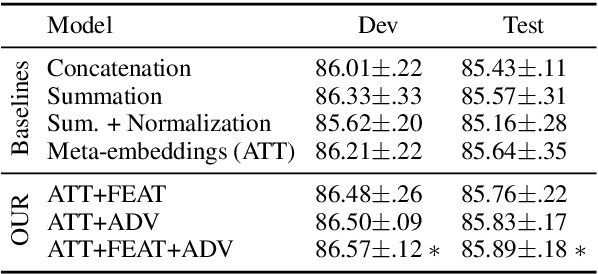
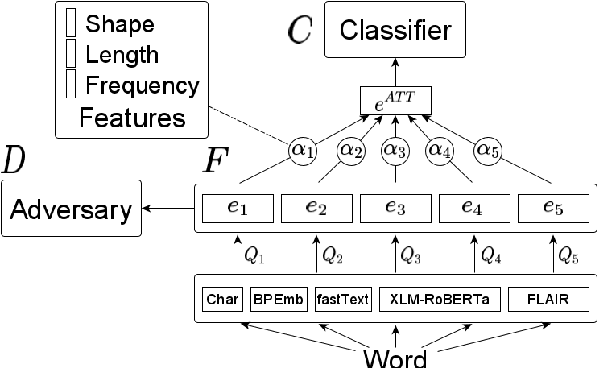
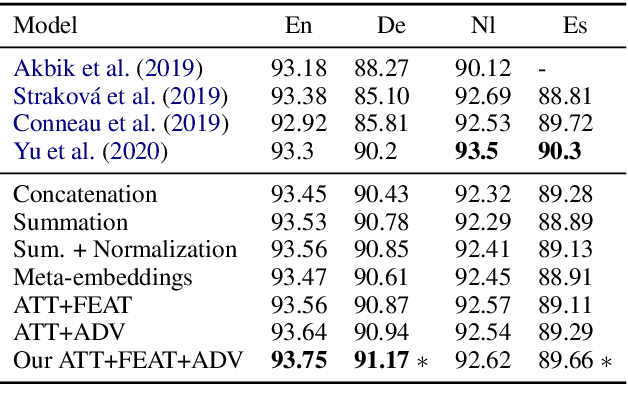
Certain embedding types outperform others in different scenarios, e.g., subword-based embeddings can model rare words well and domain-specific embeddings can better represent in-domain terms. Therefore, recent works consider attention-based meta-embeddings to combine different embedding types. We demonstrate that these methods have two shortcomings: First, the attention weights are calculated without knowledge of word properties. Second, the different embedding types can form clusters in the common embedding space, preventing the computation of a meaningful average of different embeddings and thus, reducing performance. We propose to solve these problems by using feature-based meta-embeddings learned with adversarial training. Our experiments and analysis on sentence classification and sequence tagging tasks show that our approach is effective. We set the new state of the art on various datasets across languages and domains.
NLNDE: The Neither-Language-Nor-Domain-Experts' Way of Spanish Medical Document De-Identification
Jul 02, 2020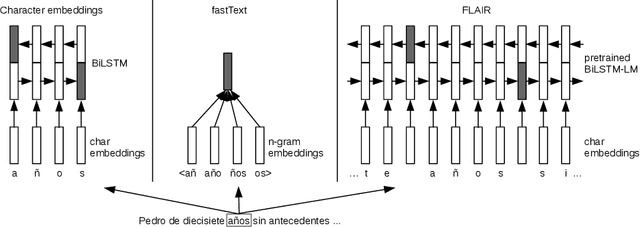
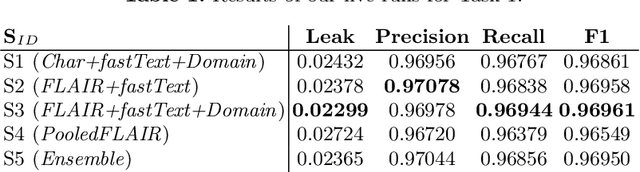
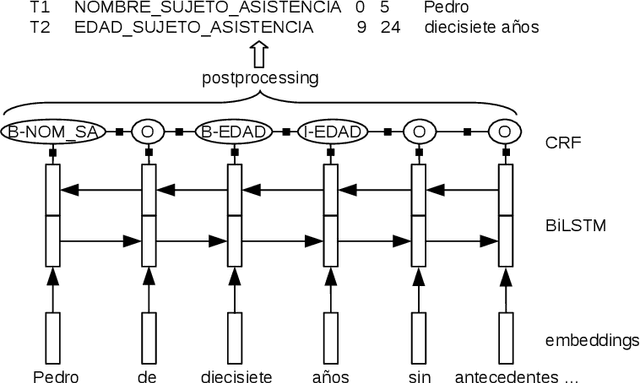

Natural language processing has huge potential in the medical domain which recently led to a lot of research in this field. However, a prerequisite of secure processing of medical documents, e.g., patient notes and clinical trials, is the proper de-identification of privacy-sensitive information. In this paper, we describe our NLNDE system, with which we participated in the MEDDOCAN competition, the medical document anonymization task of IberLEF 2019. We address the task of detecting and classifying protected health information from Spanish data as a sequence-labeling problem and investigate different embedding methods for our neural network. Despite dealing in a non-standard language and domain setting, the NLNDE system achieves promising results in the competition.
NLNDE: Enhancing Neural Sequence Taggers with Attention and Noisy Channel for Robust Pharmacological Entity Detection
Jul 02, 2020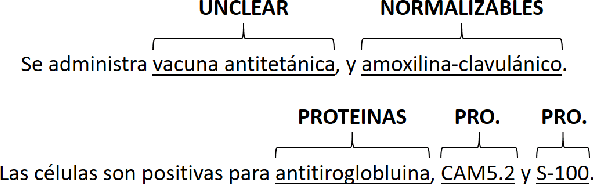
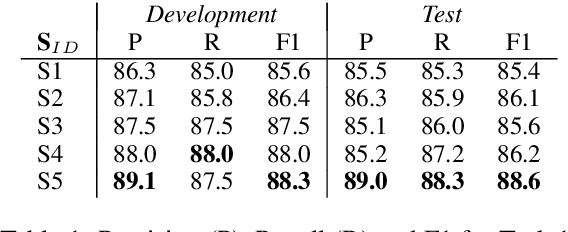
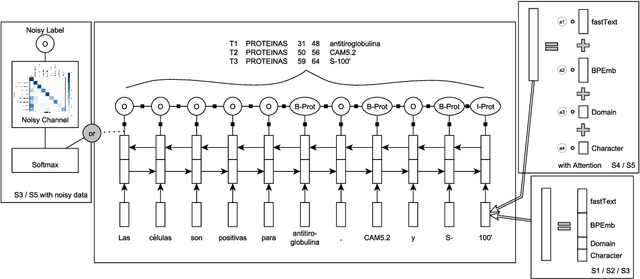
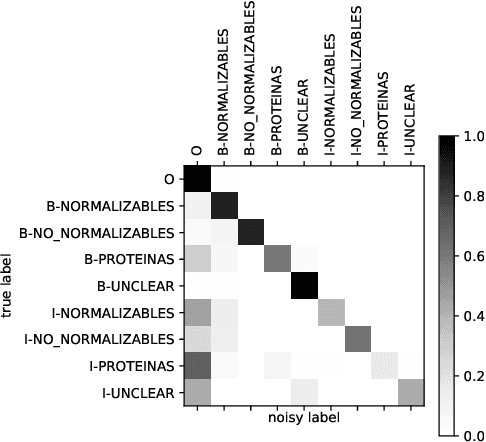
Named entity recognition has been extensively studied on English news texts. However, the transfer to other domains and languages is still a challenging problem. In this paper, we describe the system with which we participated in the first subtrack of the PharmaCoNER competition of the BioNLP Open Shared Tasks 2019. Aiming at pharmacological entity detection in Spanish texts, the task provides a non-standard domain and language setting. However, we propose an architecture that requires neither language nor domain expertise. We treat the task as a sequence labeling task and experiment with attention-based embedding selection and the training on automatically annotated data to further improve our system's performance. Our system achieves promising results, especially by combining the different techniques, and reaches up to 88.6% F1 in the competition.