 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Inverse Design for High-Level Synthesis
Jul 11, 2024High-level synthesis (HLS) has significantly advanced the automation of digital circuits design, yet the need for expertise and time in pragma tuning remains challenging. Existing solutions for the design space exploration (DSE) adopt either heuristic methods, lacking essential information for further optimization potential, or predictive models, missing sufficient generalization due to the time-consuming nature of HLS and the exponential growth of the design space. To address these challenges, we propose Deep Inverse Design for HLS (DID4HLS), a novel approach that integrates graph neural networks and generative models. DID4HLS iteratively optimizes hardware designs aimed at compute-intensive algorithms by learning conditional distributions of design features from post-HLS data. Compared to four state-of-the-art DSE baselines, our method achieved an average improvement of 42.5% on average distance to reference set (ADRS) compared to the best-performing baselines across six benchmarks, while demonstrating high robustness and efficiency.
Knowledge Distillation Under Ideal Joint Classifier Assumption
Apr 19, 2023



Knowledge distillation is a powerful technique to compress large neural networks into smaller, more efficient networks. Softmax regression representation learning is a popular approach that uses a pre-trained teacher network to guide the learning of a smaller student network. While several studies explored the effectiveness of softmax regression representation learning, the underlying mechanism that provides knowledge transfer is not well understood. This paper presents Ideal Joint Classifier Knowledge Distillation (IJCKD), a unified framework that provides a clear and comprehensive understanding of the existing knowledge distillation methods and a theoretical foundation for future research. Using mathematical techniques derived from a theory of domain adaptation, we provide a detailed analysis of the student network's error bound as a function of the teacher. Our framework enables efficient knowledge transfer between teacher and student networks and can be applied to various applications.
TDSTF: Transformer-based Diffusion probabilistic model for Sparse Time series Forecasting
Jan 16, 2023



Time series probabilistic forecasting with multi-dimensional and sporadic data (known as sparse data) has potential to implement monitoring kinds of physiological indices of patients in Intensive Care Unit (ICU). In this paper, we propose Transformer-based Diffusion probabilistic model for Sparse Time series Forecasting (TDSTF), a new model to predict distribution of highly sparse time series. There are many works that focus on probabilistic forecasting, but few of them avoid noise that come from extreme sparsity of data. We take advantage of Triplet, a data organization that represents sparse time series in a much efficient way, for our model to bypass data redundancy in the traditional matrix form. The proposed model performed better on MIMIC-III ICU dataset than the current state-of-the-art probabilistic forecasting models. We obtained normalized average continuous ranked probability score (CRPS) of $\mathbf{0.4379}$, and mean squared error (MSE) of $\mathbf{0.4008}$ when adopting the median of the model samplings as the deterministic forecasting. Our code is provided at https://github.com/PingChang818/TDSTF.
DeScoD-ECG: Deep Score-Based Diffusion Model for ECG Baseline Wander and Noise Removal
Jul 31, 2022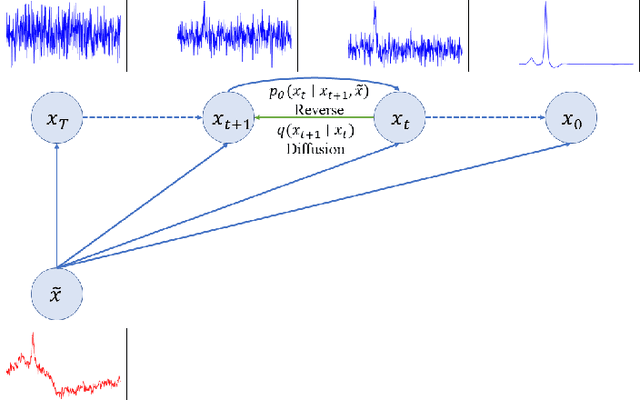
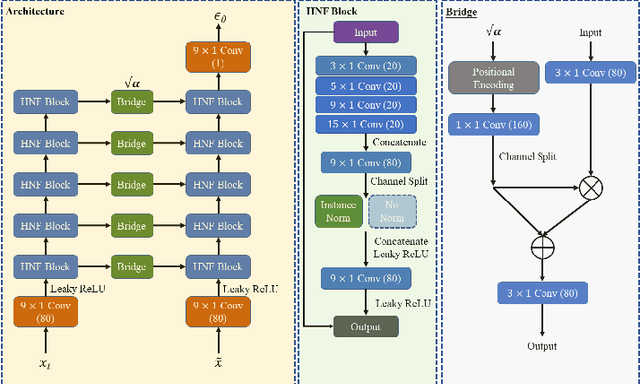
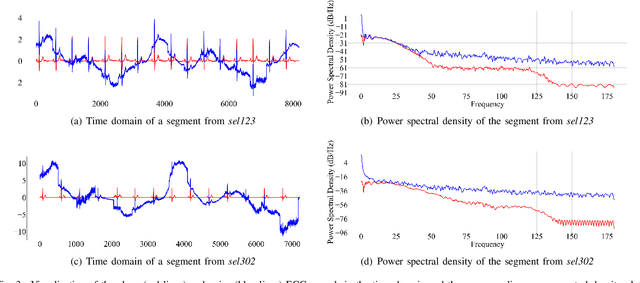
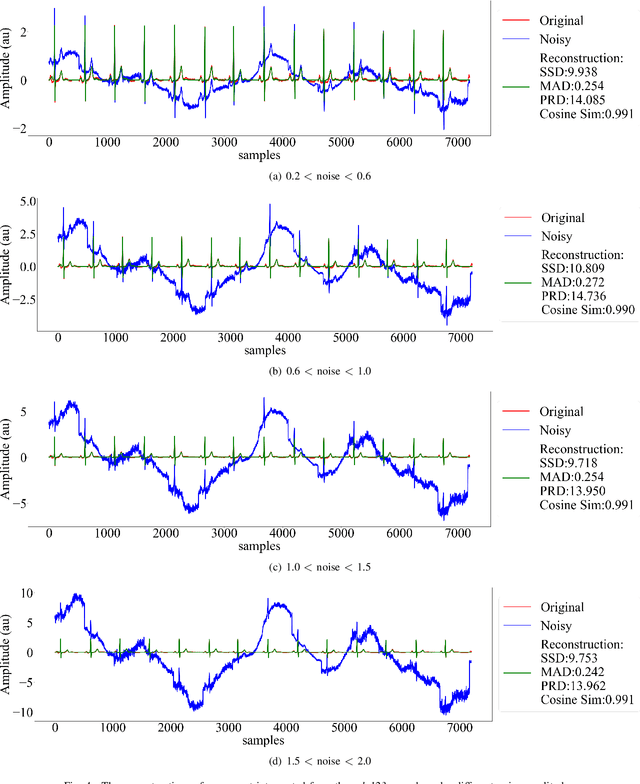
Objective: Electrocardiogram (ECG) signals commonly suffer noise interference, such as baseline wander. High-quality and high-fidelity reconstruction of the ECG signals is of great significance to diagnosing cardiovascular diseases. Therefore, this paper proposes a novel ECG baseline wander and noise removal technology. Methods: We extended the diffusion model in a conditional manner that was specific to the ECG signals, namely the Deep Score-Based Diffusion model for Electrocardiogram baseline wander and noise removal (DeScoD-ECG). Moreover, we deployed a multi-shots averaging strategy that improved signal reconstructions. We conducted the experiments on the QT Database and the MIT-BIH Noise Stress Test Database to verify the feasibility of the proposed method. Baseline methods are adopted for comparison, including traditional digital filter-based and deep learning-based methods. Results: The quantities evaluation results show that the proposed method obtained outstanding performance on four distance-based similarity metrics (the sum of squared distance, maximum absolute square, percentage of root distance, and cosine similarity) with 3.771 $\pm$ 5.713 au, 0.329 $\pm$ 0.258 au, 40.527 $\pm$ 26.258 \%, and 0.926 $\pm$ 0.087. This led to at least 20\% overall improvement compared with the best baseline method. Conclusion: This paper demonstrates the state-of-the-art performance of the DeScoD-ECG for ECG noise removal, which has better approximations of the true data distribution and higher stability under extreme noise corruptions. Significance: This study is one of the first to extend the conditional diffusion-based generative model for ECG noise removal, and the DeScoD-ECG has the potential to be widely used in biomedical applications.