 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Ontology and Instance Matching with MELT
Sep 20, 2020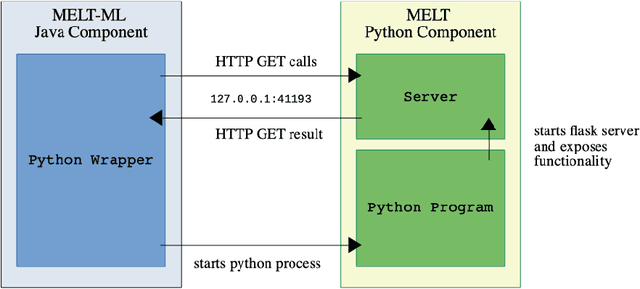

In this paper, we present MELT-ML, a machine learning extension to the Matching and EvaLuation Toolkit (MELT) which facilitates the application of supervised learning for ontology and instance matching. Our contributions are twofold: We present an open source machine learning extension to the matching toolkit as well as two supervised learning use cases demonstrating the capabilities of the new extension.
RDF2Vec Light -- A Lightweight Approach for Knowledge Graph Embeddings
Sep 17, 2020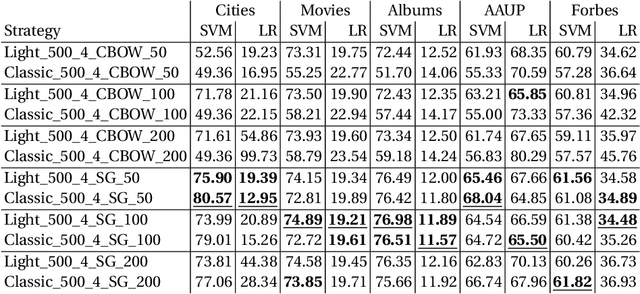

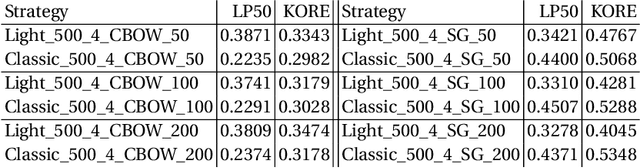
Knowledge graph embedding approaches represent nodes and edges of graphs as mathematical vectors. Current approaches focus on embedding complete knowledge graphs, i.e. all nodes and edges. This leads to very high computational requirements on large graphs such as DBpedia or Wikidata. However, for most downstream application scenarios, only a small subset of concepts is of actual interest. In this paper, we present RDF2Vec Light, a lightweight embedding approach based on RDF2Vec which generates vectors for only a subset of entities. To that end, RDF2Vec Light only traverses and processes a subgraph of the knowledge graph. Our method allows the application of embeddings of very large knowledge graphs in scenarios where such embeddings were not possible before due to a significantly lower runtime and significantly reduced hardware requirements.
Challenges of Linking Organizational Information in Open Government Data to Knowledge Graphs
Aug 14, 2020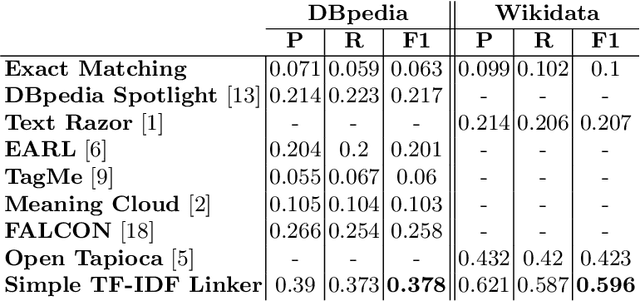
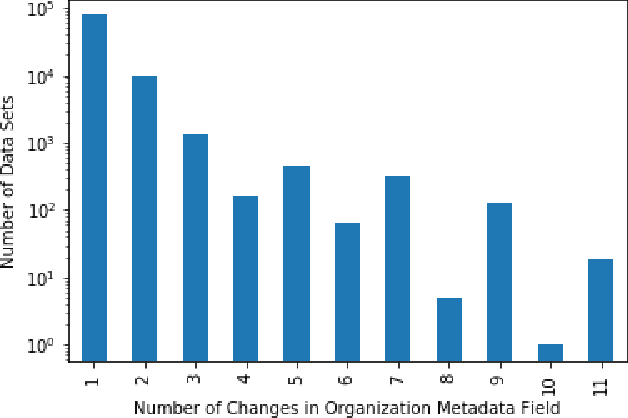
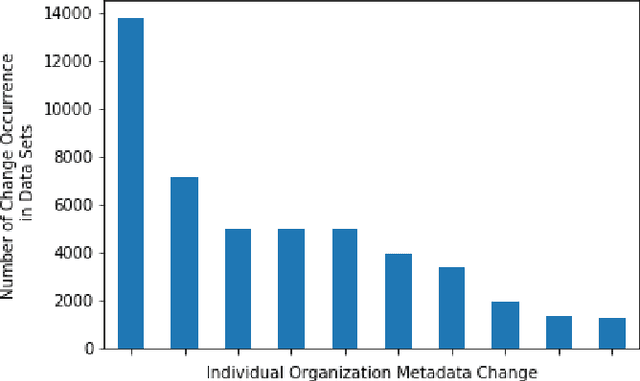
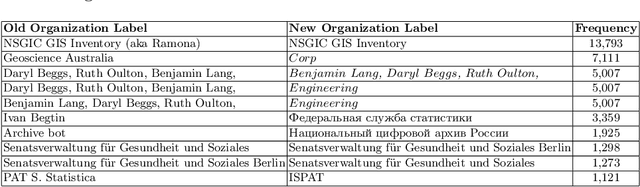
Open Government Data (OGD) is being published by various public administration organizations around the globe. Within the metadata of OGD data catalogs, the publishing organizations (1) are not uniquely and unambiguously identifiable and, even worse, (2) change over time, by public administration units being merged or restructured. In order to enable fine-grained analyses or searches on Open Government Data on the level of publishing organizations, linking those from OGD portals to publicly available knowledge graphs (KGs) such as Wikidata and DBpedia seems like an obvious solution. Still, as we show in this position paper, organization linking faces significant challenges, both in terms of available (portal) metadata and KGs in terms of data quality and completeness. We herein specifically highlight five main challenges, namely regarding (1) temporal changes in organizations and in the portal metadata, (2) lack of a base ontology for describing organizational structures and changes in public knowledge graphs, (3) metadata and KG data quality, (4) multilinguality, and (5) disambiguating public sector organizations. Based on available OGD portal metadata from the Open Data Portal Watch, we provide an in-depth analysis of these issues, make suggestions for concrete starting points on how to tackle them along with a call to the community to jointly work on these open challenges.
KGvec2go -- Knowledge Graph Embeddings as a Service
Mar 09, 2020
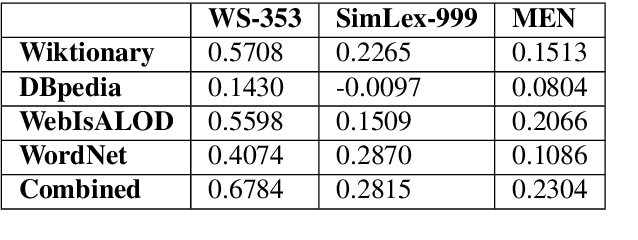
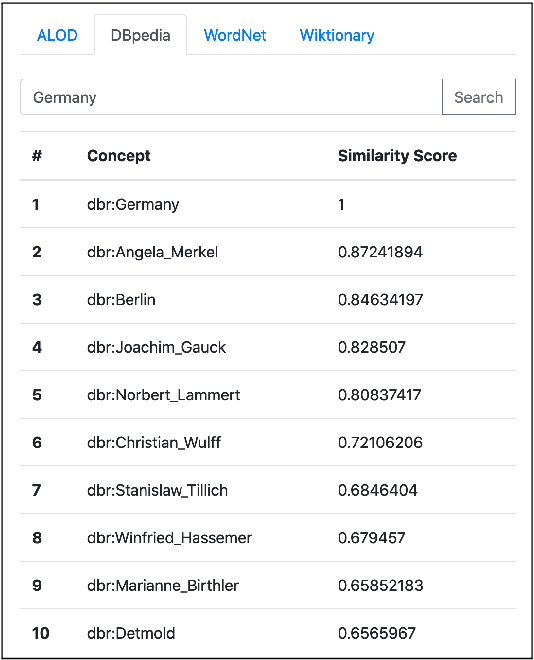
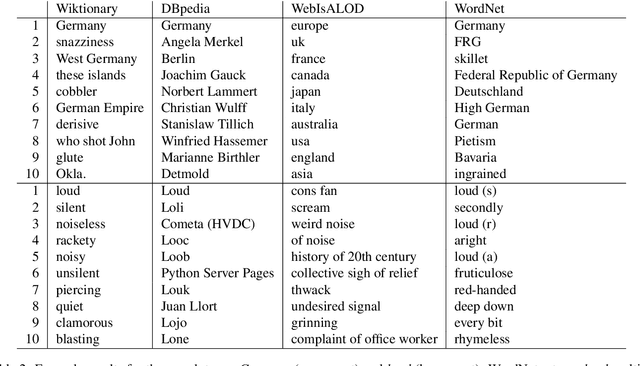
In this paper, we present KGvec2go, a Web API for accessing and consuming graph embeddings in a light-weight fashion in downstream applications. Currently, we serve pre-trained embeddings for four knowledge graphs. We introduce the service and its usage, and we show further that the trained models have semantic value by evaluating them on multiple semantic benchmarks. The evaluation also reveals that the combination of multiple models can lead to a better outcome than the best individual model.