 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Adversarial Training
Jan 27, 2021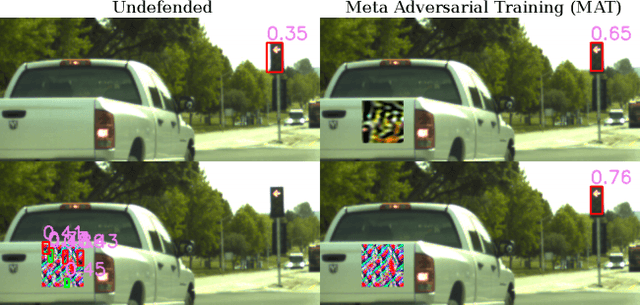
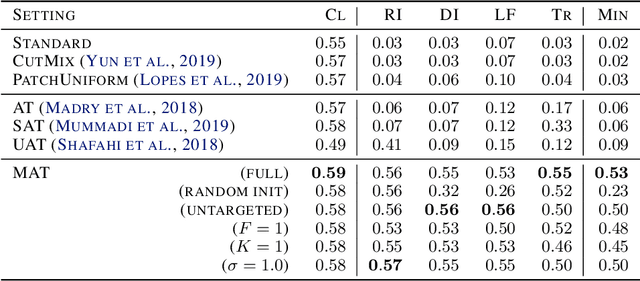
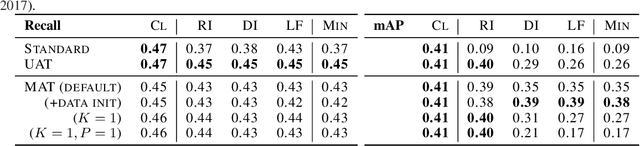
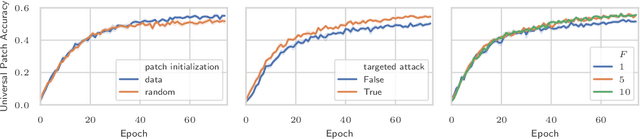
Recently demonstrated physical-world adversarial attacks have exposed vulnerabilities in perception systems that pose severe risks for safety-critical applications such as autonomous driving. These attacks place adversarial artifacts in the physical world that indirectly cause the addition of universal perturbations to inputs of a model that can fool it in a variety of contexts. Adversarial training is the most effective defense against image-dependent adversarial attacks. However, tailoring adversarial training to universal perturbations is computationally expensive since the optimal universal perturbations depend on the model weights which change during training. We propose meta adversarial training (MAT), a novel combination of adversarial training with meta-learning, which overcomes this challenge by meta-learning universal perturbations along with model training. MAT requires little extra computation while continuously adapting a large set of perturbations to the current model. We present results for universal patch and universal perturbation attacks on image classification and traffic-light detection. MAT considerably increases robustness against universal patch attacks compared to prior work.
Increasing the Robustness of Semantic Segmentation Models with Painting-by-Numbers
Oct 12, 2020
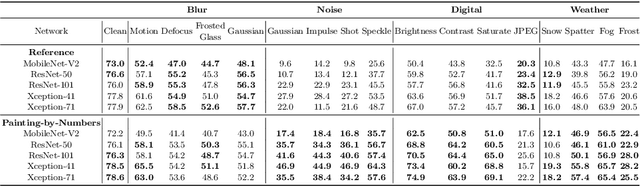

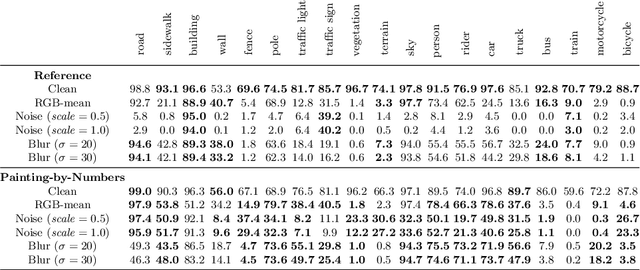
For safety-critical applications such as autonomous driving, CNNs have to be robust with respect to unavoidable image corruptions, such as image noise. While previous works addressed the task of robust prediction in the context of full-image classification, we consider it for dense semantic segmentation. We build upon an insight from image classification that output robustness can be improved by increasing the network-bias towards object shapes. We present a new training schema that increases this shape bias. Our basic idea is to alpha-blend a portion of the RGB training images with faked images, where each class-label is given a fixed, randomly chosen color that is not likely to appear in real imagery. This forces the network to rely more strongly on shape cues. We call this data augmentation technique ``Painting-by-Numbers''. We demonstrate the effectiveness of our training schema for DeepLabv3+ with various network backbones, MobileNet-V2, ResNets, and Xception, and evaluate it on the Cityscapes dataset. With respect to our 16 different types of image corruptions and 5 different network backbones, we are in 74% better than training with clean data. For cases where we are worse than a model trained without our training schema, it is mostly only marginally worse. However, for some image corruptions such as images with noise, we see a considerable performance gain of up to 25%.
Adversarial and Natural Perturbations for General Robustness
Oct 03, 2020
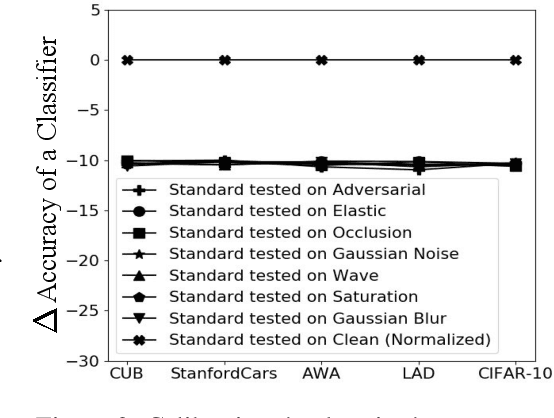
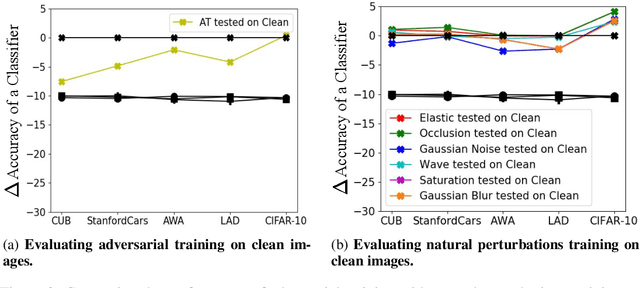
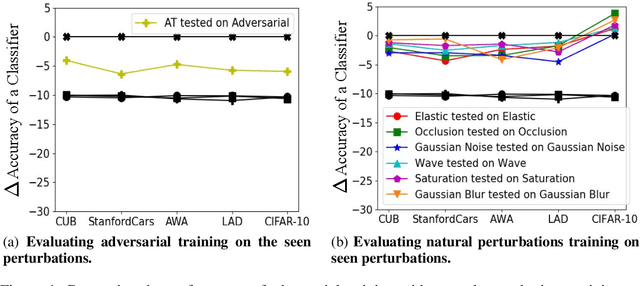
In this paper we aim to explore the general robustness of neural network classifiers by utilizing adversarial as well as natural perturbations. Different from previous works which mainly focus on studying the robustness of neural networks against adversarial perturbations, we also evaluate their robustness on natural perturbations before and after robustification. After standardizing the comparison between adversarial and natural perturbations, we demonstrate that although adversarial training improves the performance of the networks against adversarial perturbations, it leads to drop in the performance for naturally perturbed samples besides clean samples. In contrast, natural perturbations like elastic deformations, occlusions and wave does not only improve the performance against natural perturbations, but also lead to improvement in the performance for the adversarial perturbations. Additionally they do not drop the accuracy on the clean images.
Meta-Learning of Neural Architectures for Few-Shot Learning
Nov 25, 2019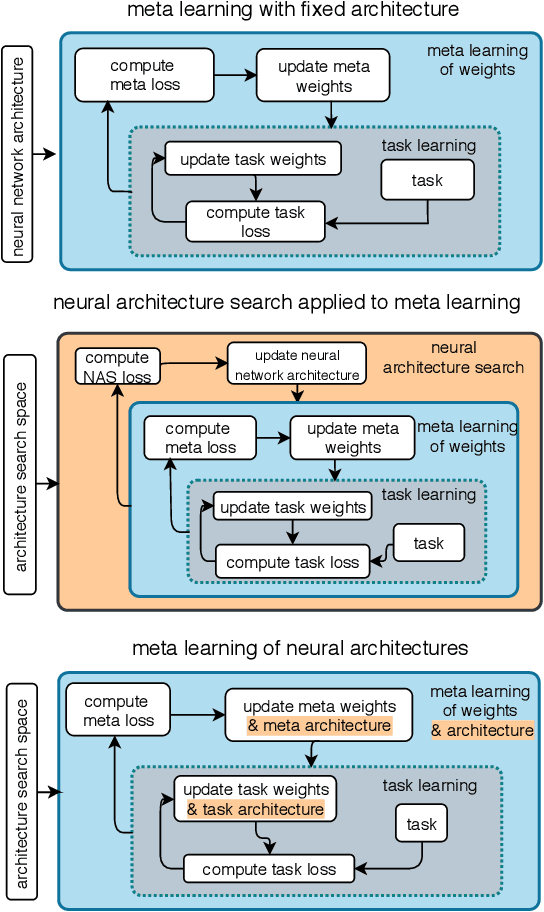
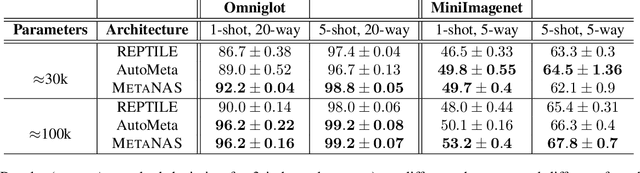
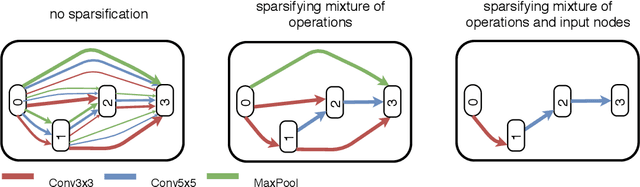
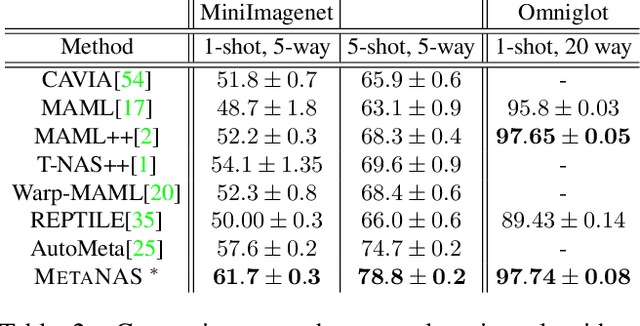
The recent progress in neural architectures search (NAS) has allowed scaling the automated design of neural architectures to real-world domains such as object detection and semantic segmentation. However, one prerequisite for the application of NAS are large amounts of labeled data and compute resources. This renders its application challenging in few-shot learning scenarios, where many related tasks need to be learned, each with limited amounts of data and compute time. Thus, few-shot learning is typically done with a fixed neural architecture. To improve upon this, we propose MetaNAS, the first method which fully integrates NAS with gradient-based meta-learning. MetaNAS optimizes a meta-architecture along with the meta-weights during meta-training. During meta-testing, architectures can be adapted to a novel task with a few steps of the task optimizer, that is: task adaptation becomes computationally cheap and requires only little data per task. Moreover, MetaNAS is agnostic in that it can be used with arbitrary model-agnostic meta-learning algorithms and arbitrary gradient-based NAS methods. Empirical results on standard few-shot classification benchmarks show that MetaNAS with a combination of DARTS and REPTILE yields state-of-the-art results.
Understanding Misclassifications by Attributes
Oct 15, 2019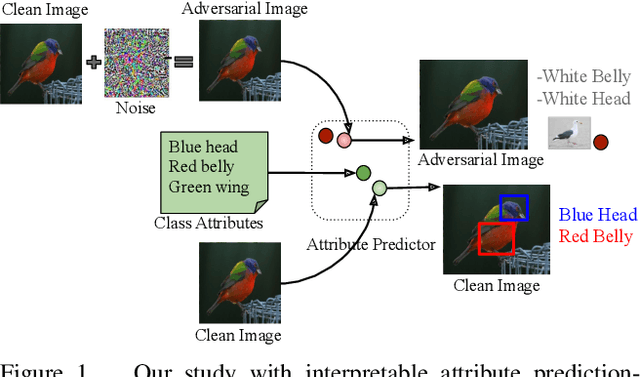

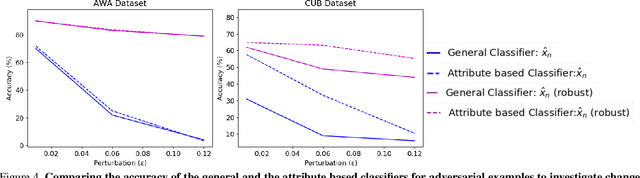
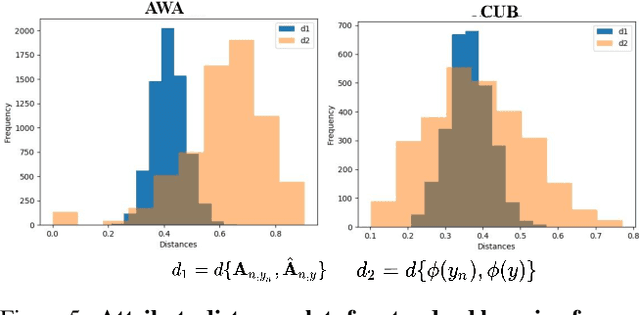
In this paper, we aim to understand and explain the decisions of deep neural networks by studying the behavior of predicted attributes when adversarial examples are introduced. We study the changes in attributes for clean as well as adversarial images in both standard and adversarially robust networks. We propose a metric to quantify the robustness of an adversarially robust network against adversarial attacks. In a standard network, attributes predicted for adversarial images are consistent with the wrong class, while attributes predicted for the clean images are consistent with the true class. In an adversarially robust network, the attributes predicted for adversarial images classified correctly are consistent with the true class. Finally, we show that the ability to robustify a network varies for different datasets. For the fine grained dataset, it is higher as compared to the coarse-grained dataset. Additionally, the ability to robustify a network increases with the increase in adversarial noise.
Interpreting Adversarial Examples with Attributes
Apr 17, 2019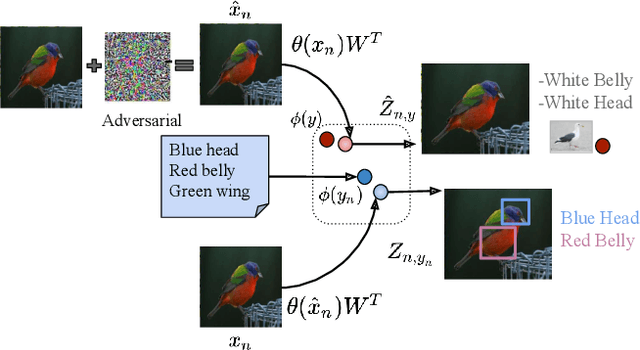

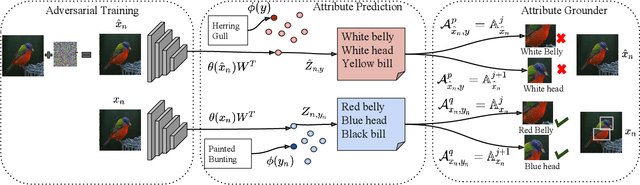

Deep computer vision systems being vulnerable to imperceptible and carefully crafted noise have raised questions regarding the robustness of their decisions. We take a step back and approach this problem from an orthogonal direction. We propose to enable black-box neural networks to justify their reasoning both for clean and for adversarial examples by leveraging attributes, i.e. visually discriminative properties of objects. We rank attributes based on their class relevance, i.e. how the classification decision changes when the input is visually slightly perturbed, as well as image relevance, i.e. how well the attributes can be localized on both clean and perturbed images. We present comprehensive experiments for attribute prediction, adversarial example generation, adversarially robust learning, and their qualitative and quantitative analysis using predicted attributes on three benchmark datasets.
Defending against Universal Perturbations with Shared Adversarial Training
Dec 10, 2018
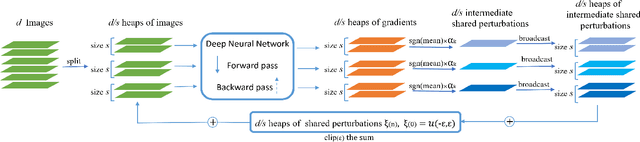
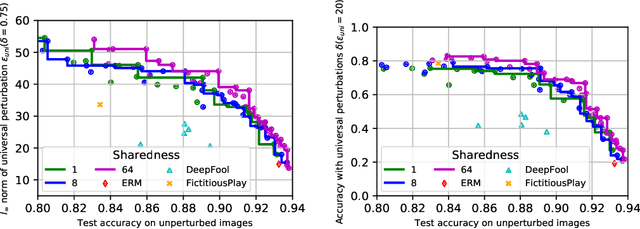
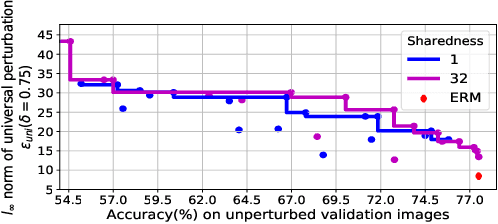
Classifiers such as deep neural networks have been shown to be vulnerable against adversarial perturbations on problems with high-dimensional input space. While adversarial training improves the robustness of image classifiers against such adversarial perturbations, it leaves them sensitive to perturbations on a non-negligible fraction of the inputs. In this work, we show that adversarial training is more effective in preventing universal perturbations, where the same perturbation needs to fool a classifier on many inputs. Moreover, we investigate the trade-off between robustness against universal perturbations and performance on unperturbed data and propose an extension of adversarial training that handles this trade-off more gracefully. We present results for image classification and semantic segmentation to showcase that universal perturbations that fool a model hardened with adversarial training become clearly perceptible and show patterns of the target scene.
Neural Architecture Search: A Survey
Sep 05, 2018
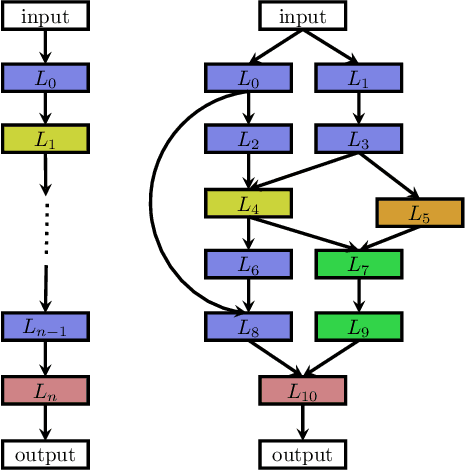
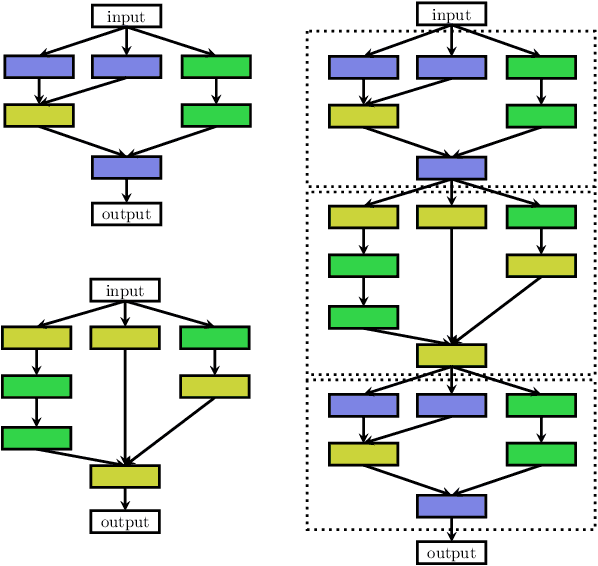
Deep Learning has enabled remarkable progress over the last years on a variety of tasks, such as image recognition, speech recognition, and machine translation. One crucial aspect for this progress are novel neural architectures. Currently employed architectures have mostly been developed manually by human experts, which is a time-consuming and error-prone process. Because of this, there is growing interest in automated neural architecture search methods. We provide an overview of existing work in this field of research and categorize them according to three dimensions: search space, search strategy, and performance estimation strategy.
Efficient Multi-objective Neural Architecture Search via Lamarckian Evolution
Jul 24, 2018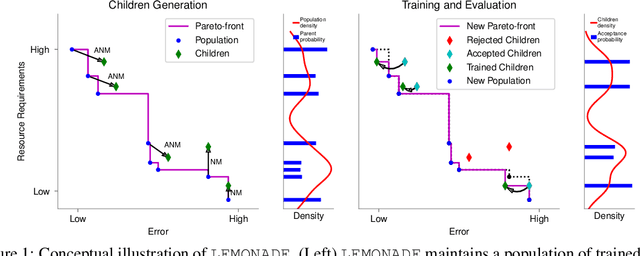
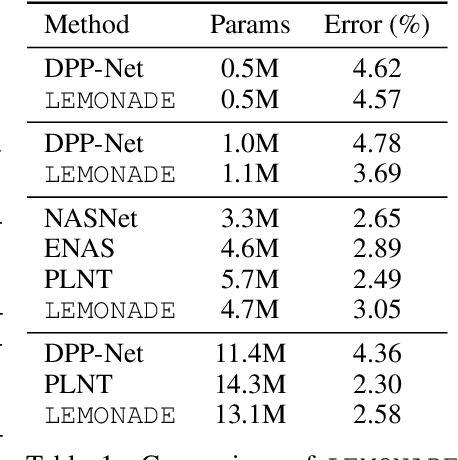
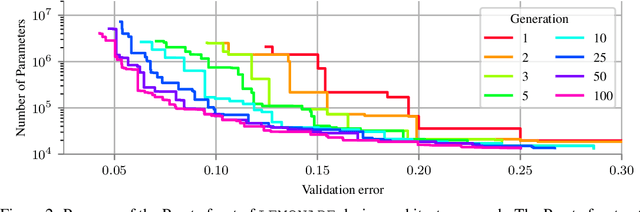

Architecture search aims at automatically finding neural architectures that are competitive with architectures designed by human experts. While recent approaches have achieved state-of-the-art predictive performance for image recognition, they are problematic under resource constraints for two reasons: (1) the neural architectures found are solely optimized for high predictive performance, without penalizing excessive resource consumption; (2) most architecture search methods require vast computational resources. We address the first shortcoming by proposing LEMONADE, an evolutionary algorithm for multi-objective architecture search that allows approximating the Pareto-front of architectures under multiple objectives, such as predictive performance and number of parameters, in a single run of the method. We address the second shortcoming by proposing a Lamarckian inheritance mechanism for LEMONADE which generates children networks that are warmstarted with the predictive performance of their trained parents. This is accomplished by using (approximate) network morphism operators for generating children. The combination of these two contributions allows finding models that are on par or even outperform different-sized NASNets, MobileNets, MobileNets V2 and Wide Residual Networks on CIFAR-10 and ImageNet64x64 within only one week on eight GPUs, which is about 20-40x less compute power than previous architecture search methods that yield state-of-the-art performance.
Scaling provable adversarial defenses
May 31, 2018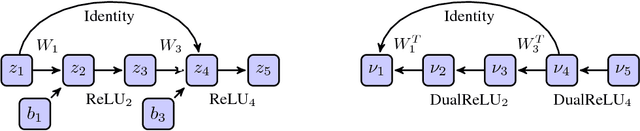
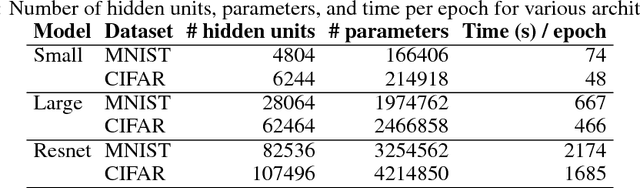
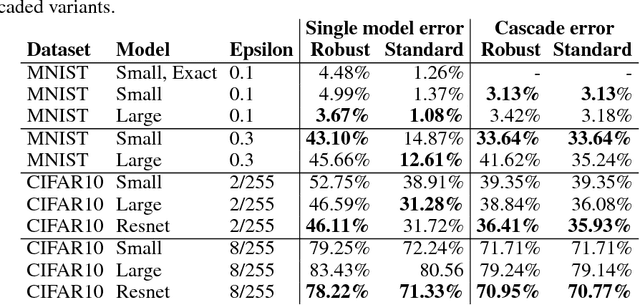
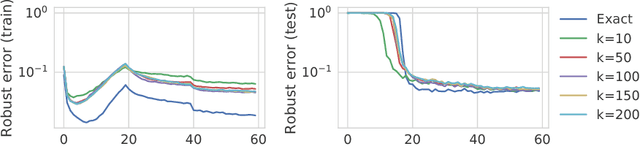
Recent work has developed methods for learning deep network classifiers that are provably robust to norm-bounded adversarial perturbation; however, these methods are currently only possible for relatively small feedforward networks. In this paper, in an effort to scale these approaches to substantially larger models, we extend previous work in three main directions. First, we present a technique for extending these training procedures to much more general networks, with skip connections (such as ResNets) and general nonlinearities; the approach is fully modular, and can be implemented automatically (analogous to automatic differentiation). Second, in the specific case of $\ell_\infty$ adversarial perturbations and networks with ReLU nonlinearities, we adopt a nonlinear random projection for training, which scales linearly in the number of hidden units (previous approaches scaled quadratically). Third, we show how to further improve robust error through cascade models. On both MNIST and CIFAR data sets, we train classifiers that improve substantially on the state of the art in provable robust adversarial error bounds: from 5.8% to 3.1% on MNIST (with $\ell_\infty$ perturbations of $\epsilon=0.1$), and from 80% to 36.4% on CIFAR (with $\ell_\infty$ perturbations of $\epsilon=2/255$). Code for all experiments in the paper is available at https://github.com/locuslab/convex_adversarial/.