 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallelizable Approach for Characterizing NE in Zero-Sum Games After a Linear Number of Iterations of Gradient Descent
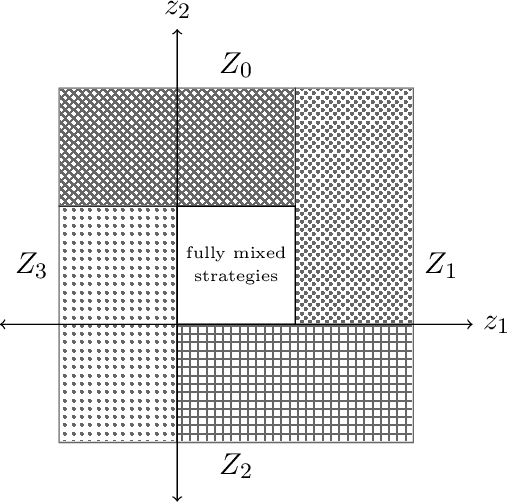
Jul 15, 2025We study online optimization methods for zero-sum games, a fundamental problem in adversarial learning in machine learning, economics, and many other domains. Traditional methods approximate Nash equilibria (NE) using either regret-based methods (time-average convergence) or contraction-map-based methods (last-iterate convergence). We propose a new method based on Hamiltonian dynamics in physics and prove that it can characterize the set of NE in a finite (linear) number of iterations of alternating gradient descent in the unbounded setting, modulo degeneracy, a first in online optimization. Unlike standard methods for computing NE, our proposed approach can be parallelized and works with arbitrary learning rates, both firsts in algorithmic game theory. Experimentally, we support our results by showing our approach drastically outperforms standard methods.
Fast and Furious Learning in Zero-Sum Games: Vanishing Regret with Non-Vanishing Step Sizes
May 11, 2019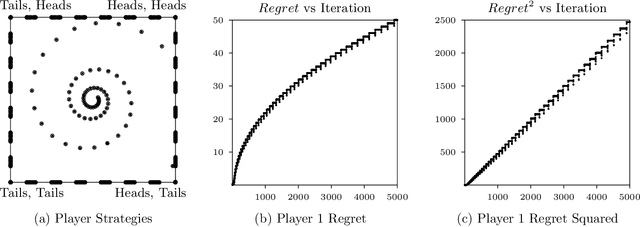
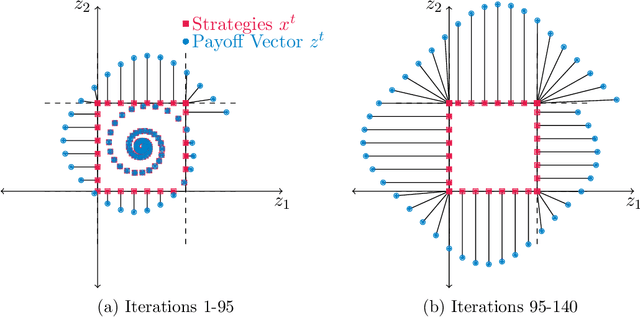
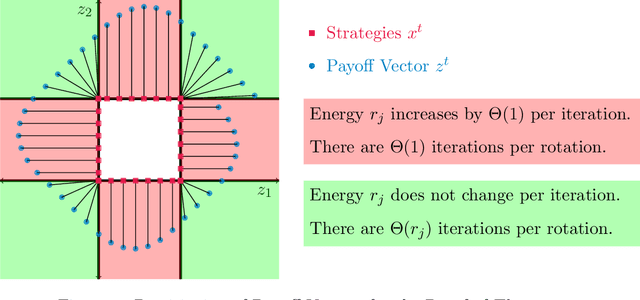
We show for the first time, to our knowledge, that it is possible to reconcile in online learning in zero-sum games two seemingly contradictory objectives: vanishing time-average regret and non-vanishing step sizes. This phenomenon, that we coin ``fast and furious" learning in games, sets a new benchmark about what is possible both in max-min optimization as well as in multi-agent systems. Our analysis does not depend on introducing a carefully tailored dynamic. Instead we focus on the most well studied online dynamic, gradient descent. Similarly, we focus on the simplest textbook class of games, two-agent two-strategy zero-sum games, such as Matching Pennies. Even for this simplest of benchmarks the best known bound for total regret, prior to our work, was the trivial one of $O(T)$, which is immediately applicable even to a non-learning agent. Based on a tight understanding of the geometry of the non-equilibrating trajectories in the dual space we prove a regret bound of $\Theta(\sqrt{T})$ matching the well known optimal bound for adaptive step sizes in the online setting. This guarantee holds for all fixed step-sizes without having to know the time horizon in advance and adapt the fixed step-size accordingly. As a corollary, we establish that even with fixed learning rates the time-average of mixed strategies, utilities converge to their exact Nash equilibrium values.
Multi-Agent Learning in Network Zero-Sum Games is a Hamiltonian System
Mar 05, 2019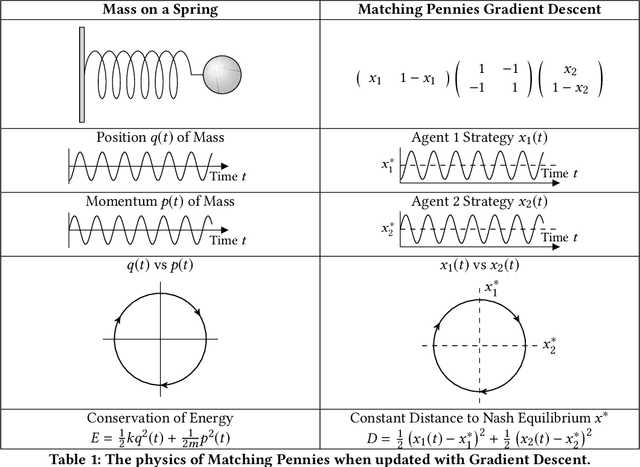
Zero-sum games are natural, if informal, analogues of closed physical systems where no energy/utility can enter or exit. This analogy can be extended even further if we consider zero-sum network (polymatrix) games where multiple agents interact in a closed economy. Typically, (network) zero-sum games are studied from the perspective of Nash equilibria. Nevertheless, this comes in contrast with the way we typically think about closed physical systems, e.g., Earth-moon systems which move perpetually along recurrent trajectories of constant energy. We establish a formal and robust connection between multi-agent systems and Hamiltonian dynamics -- the same dynamics that describe conservative systems in physics. Specifically, we show that no matter the size, or network structure of such closed economies, even if agents use different online learning dynamics from the standard class of Follow-the-Regularized-Leader, they yield Hamiltonian dynamics. This approach generalizes the known connection to Hamiltonians for the special case of replicator dynamics in two agent zero-sum games developed by Hofbauer. Moreover, our results extend beyond zero-sum settings and provide a type of a Rosetta stone (see e.g. Table 1) that helps to translate results and techniques between online optimization, convex analysis, games theory, and physics.