 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Structure Do LLMs Need? Evaluating LLMs for Bibliometric Cluster Description
May 23, 2026Large language models (LLMs) can support scientific literature synthesis, but remain prone to hallucinated references, uneven coverage, and weakly grounded thematic organization. We evaluate whether bibliometric structure improves LLM-assisted synthesis by comparing six pipelines for generating cluster descriptions under different levels of evidence and structure. Using 100 published bibliometric analyses, we reconstruct Scopus corpora, extract human-written cluster descriptions, and assess outputs by human alignment, semantic coverage, clustering quality, graph quality, and reference grounding. Results show that LLMs produce descriptions semantically close to human-written ones, but are unreliable when asked to infer bibliometric structure from scratch. Performance improves when bibliometric algorithms define the clusters and the LLM interprets them. Overall, LLM-assisted bibliometric synthesis is most promising as a hybrid workflow in which algorithms provide auditable structure and LLMs generate readable descriptions.
When Can Digital Personas Reliably Approximate Human Survey Findings?
May 11, 2026Digital personas powered by Large Language Models (LLMs) are increasingly proposed as substitutes for human survey respondents, yet it remains unclear when they can reliably approximate human survey findings. We answer this question using the LISS panel, constructing personas from respondents' background variables and pre-2023 survey histories, then testing them against the same respondents' held-out post-cutoff answers. Across four persona architectures, three LLMs, and two prediction tasks, we assess performance at the question, respondent, distributional, equity, and clustering levels. Digital personas improve alignment with human response distributions, especially in domains tied to stable attributes and values, but remain limited for individual prediction and fail to recover multivariate respondent structure. Retrieval-augmented architectures provide the clearest gains, but performance depends more on human response structure than on model choice: personas perform best for low-variability questions and common respondent patterns, and worst for subjective, heterogeneous, or rare responses. Our results provide practical guidance on when digital personas could be appropriate for survey research and when human validation remains necessary.
Inheritance Between Feedforward and Convolutional Networks via Model Projection
Feb 05, 2026Techniques for feedforward networks (FFNs) and convolutional networks (CNNs) are frequently reused across families, but the relationship between the underlying model classes is rarely made explicit. We introduce a unified node-level formalization with tensor-valued activations and show that generalized feedforward networks form a strict subset of generalized convolutional networks. Motivated by the mismatch in per-input parameterization between the two families, we propose model projection, a parameter-efficient transfer learning method for CNNs that freezes pretrained per-input-channel filters and learns a single scalar gate for each (output channel, input channel) contribution. Projection keeps all convolutional layers adaptable to downstream tasks while substantially reducing the number of trained parameters in convolutional layers. We prove that projected nodes take the generalized FFN form, enabling projected CNNs to inherit feedforward techniques that do not rely on homogeneous layer inputs. Experiments across multiple ImageNet-pretrained backbones and several downstream image classification datasets show that model projection is a strong transfer learning baseline under simple training recipes.
Unsupervised Text Segmentation via Kernel Change-Point Detection on Sentence Embeddings
Jan 26, 2026Unsupervised text segmentation is crucial because boundary labels are expensive, subjective, and often fail to transfer across domains and granularity choices. We propose Embed-KCPD, a training-free method that represents sentences as embedding vectors and estimates boundaries by minimizing a penalized KCPD objective. Beyond the algorithmic instantiation, we develop, to our knowledge, the first dependence-aware theory for KCPD under $m$-dependent sequences, a finite-memory abstraction of short-range dependence common in language. We prove an oracle inequality for the population penalized risk and a localization guarantee showing that each true change point is recovered within a window that is small relative to segment length. To connect theory to practice, we introduce an LLM-based simulation framework that generates synthetic documents with controlled finite-memory dependence and known boundaries, validating the predicted scaling behavior. Across standard segmentation benchmarks, Embed-KCPD often outperforms strong unsupervised baselines. A case study on Taylor Swift's tweets illustrates that Embed-KCPD combines strong theoretical guarantees, simulated reliability, and practical effectiveness for text segmentation.
Dynamics of "Spontaneous" Topic Changes in Next Token Prediction with Self-Attention
Jan 10, 2025



Human cognition can spontaneously shift conversation topics, often triggered by emotional or contextual signals. In contrast, self-attention-based language models depend on structured statistical cues from input tokens for next-token prediction, lacking this spontaneity. Motivated by this distinction, we investigate the factors that influence the next-token prediction to change the topic of the input sequence. We define concepts of topic continuity, ambiguous sequences, and change of topic, based on defining a topic as a set of token priority graphs (TPGs). Using a simplified single-layer self-attention architecture, we derive analytical characterizations of topic changes. Specifically, we demonstrate that (1) the model maintains the priority order of tokens related to the input topic, (2) a topic change occurs only if lower-priority tokens outnumber all higher-priority tokens of the input topic, and (3) unlike human cognition, longer context lengths and overlapping topics reduce the likelihood of spontaneous redirection. These insights highlight differences between human cognition and self-attention-based models in navigating topic changes and underscore the challenges in designing conversational AI capable of handling "spontaneous" conversations more naturally. To our knowledge, this is the first work to address these questions in such close relation to human conversation and thought.
Quantile universal threshold: model selection at the detection edge for high-dimensional linear regression
Dec 05, 2014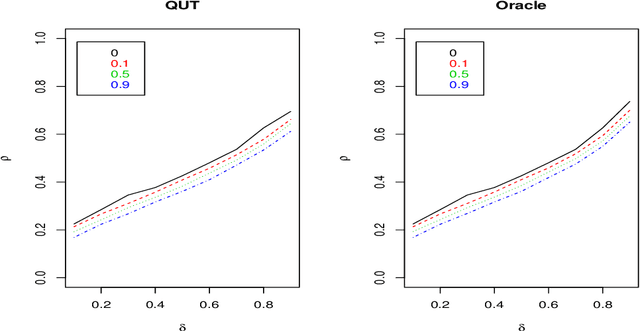
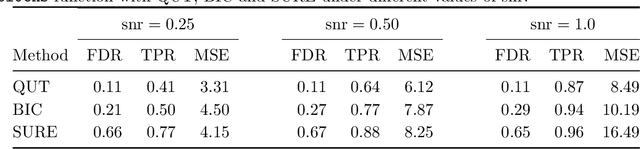
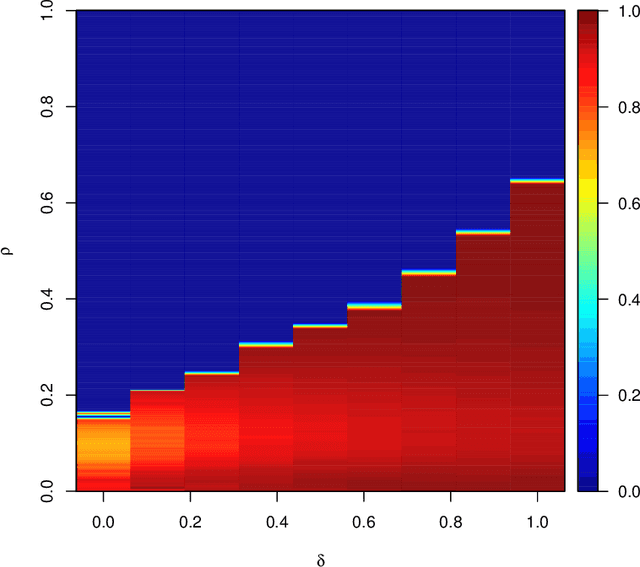
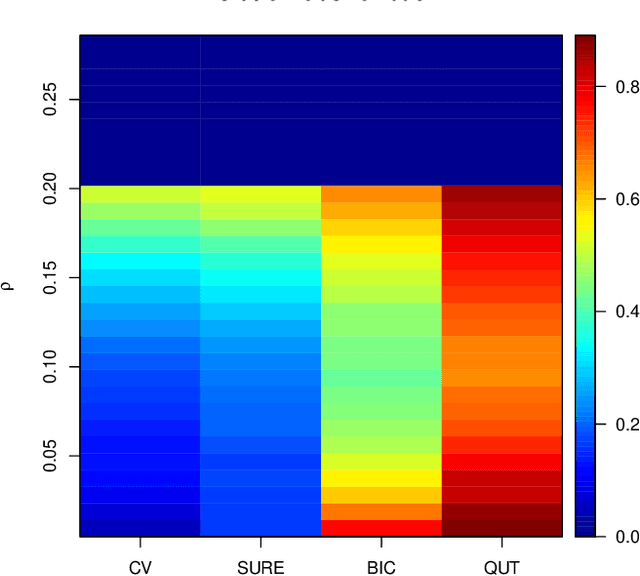
To estimate a sparse linear model from data with Gaussian noise, consilience from lasso and compressed sensing literatures is that thresholding estimators like lasso and the Dantzig selector have the ability in some situations to identify with high probability part of the significant covariates asymptotically, and are numerically tractable thanks to convexity. Yet, the selection of a threshold parameter $\lambda$ remains crucial in practice. To that aim we propose Quantile Universal Thresholding, a selection of $\lambda$ at the detection edge. We show with extensive simulations and real data that an excellent compromise between high true positive rate and low false discovery rate is achieved, leading also to good predictive risk.