 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Other News: A Bi-style Text-to-speech Model for Synthesizing Newscaster Voice with Limited Data
Apr 04, 2019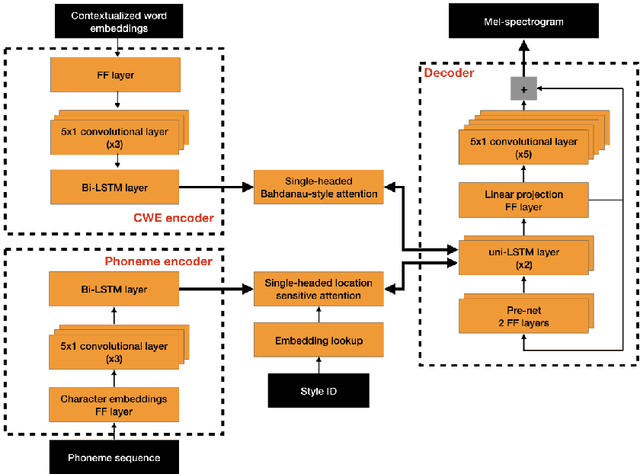
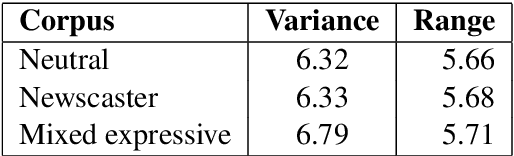

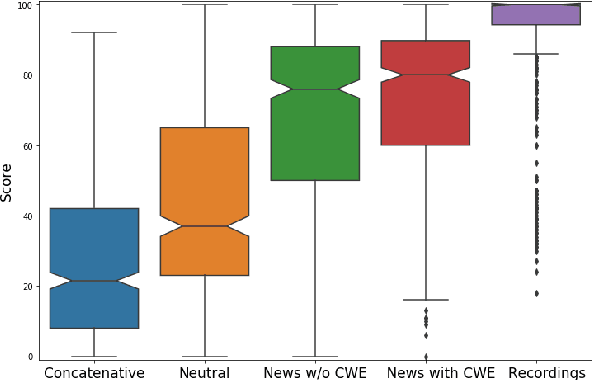
Neural text-to-speech synthesis (NTTS) models have shown significant progress in generating high-quality speech, however they require a large quantity of training data. This makes creating models for multiple styles expensive and time-consuming. In this paper different styles of speech are analysed based on prosodic variations, from this a model is proposed to synthesise speech in the style of a newscaster, with just a few hours of supplementary data. We pose the problem of synthesising in a target style using limited data as that of creating a bi-style model that can synthesise both neutral-style and newscaster-style speech via a one-hot vector which factorises the two styles. We also propose conditioning the model on contextual word embeddings, and extensively evaluate it against neutral NTTS, and neutral concatenative-based synthesis. This model closes the gap in perceived style-appropriateness between natural recordings for newscaster-style of speech, and neutral speech synthesis by approximately two-thirds.
Effect of data reduction on sequence-to-sequence neural TTS
Nov 23, 2018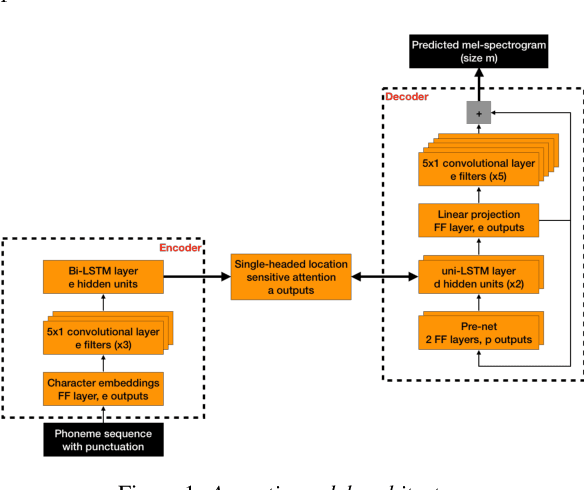
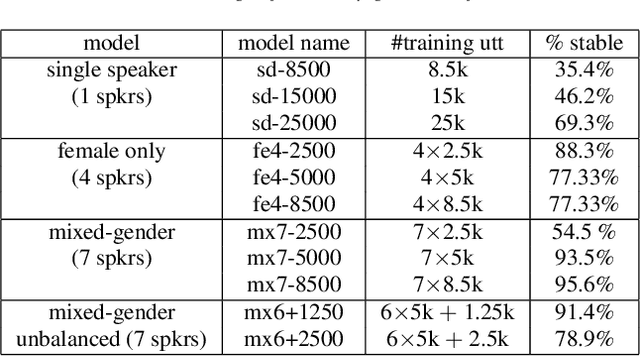
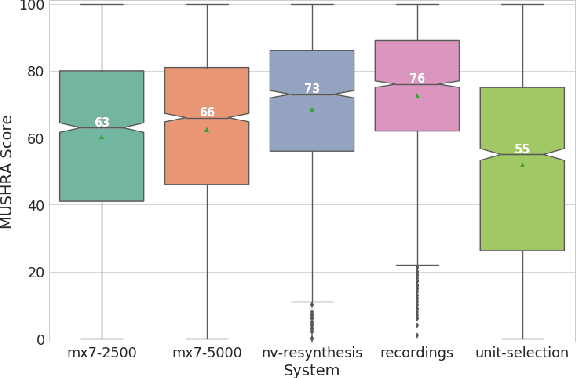
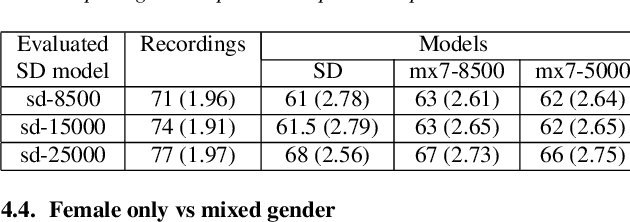
Recent speech synthesis systems based on sampling from autoregressive neural networks models can generate speech almost undistinguishable from human recordings. However, these models require large amounts of data. This paper shows that the lack of data from one speaker can be compensated with data from other speakers. The naturalness of Tacotron2-like models trained on a blend of 5k utterances from 7 speakers is better than that of speaker dependent models trained on 15k utterances, but in terms of stability multi-speaker models are always more stable. We also demonstrate that models mixing only 1250 utterances from a target speaker with 5k utterances from another 6 speakers can produce significantly better quality than state-of-the-art DNN-guided unit selection systems trained on more than 10 times the data from the target speaker.
Deep Encoder-Decoder Models for Unsupervised Learning of Controllable Speech Synthesis
Sep 09, 2018
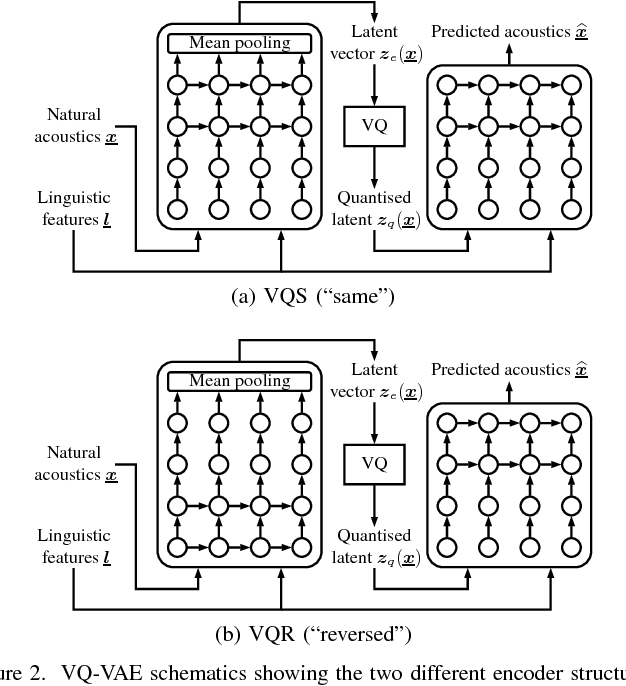
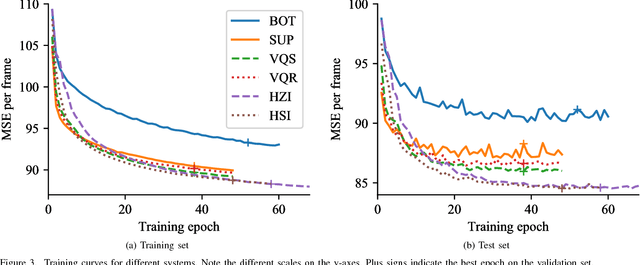
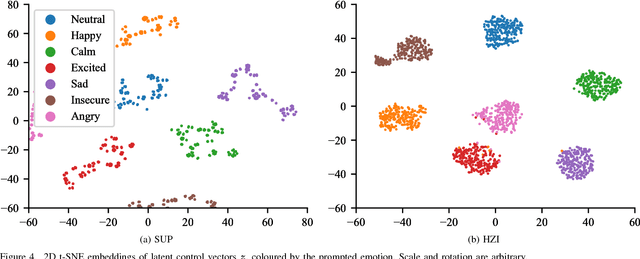
Generating versatile and appropriate synthetic speech requires control over the output expression separate from the spoken text. Important non-textual speech variation is seldom annotated, in which case output control must be learned in an unsupervised fashion. In this paper, we perform an in-depth study of methods for unsupervised learning of control in statistical speech synthesis. For example, we show that popular unsupervised training heuristics can be interpreted as variational inference in certain autoencoder models. We additionally connect these models to VQ-VAEs, another, recently-proposed class of deep variational autoencoders, which we show can be derived from a very similar mathematical argument. The implications of these new probabilistic interpretations are discussed. We illustrate the utility of the various approaches with an application to acoustic modelling for emotional speech synthesis, where the unsupervised methods for learning expression control (without access to emotional labels) are found to give results that in many aspects match or surpass the previous best supervised approach.
A Spoofing Benchmark for the 2018 Voice Conversion Challenge: Leveraging from Spoofing Countermeasures for Speech Artifact Assessment
Sep 04, 2018
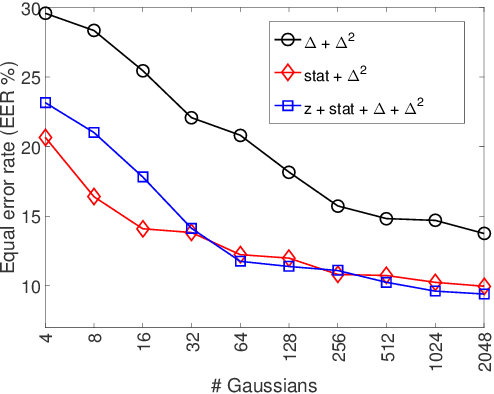
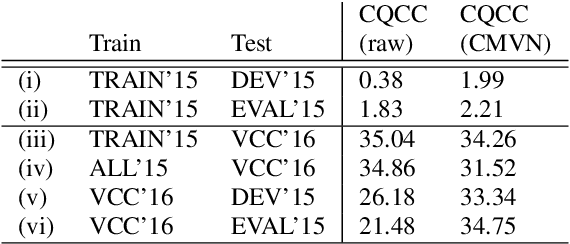
Voice conversion (VC) aims at conversion of speaker characteristic without altering content. Due to training data limitations and modeling imperfections, it is difficult to achieve believable speaker mimicry without introducing processing artifacts; performance assessment of VC, therefore, usually involves both speaker similarity and quality evaluation by a human panel. As a time-consuming, expensive, and non-reproducible process, it hinders rapid prototyping of new VC technology. We address artifact assessment using an alternative, objective approach leveraging from prior work on spoofing countermeasures (CMs) for automatic speaker verification. Therein, CMs are used for rejecting `fake' inputs such as replayed, synthetic or converted speech but their potential for automatic speech artifact assessment remains unknown. This study serves to fill that gap. As a supplement to subjective results for the 2018 Voice Conversion Challenge (VCC'18) data, we configure a standard constant-Q cepstral coefficient CM to quantify the extent of processing artifacts. Equal error rate (EER) of the CM, a confusability index of VC samples with real human speech, serves as our artifact measure. Two clusters of VCC'18 entries are identified: low-quality ones with detectable artifacts (low EERs), and higher quality ones with less artifacts. None of the VCC'18 systems, however, is perfect: all EERs are < 30 % (the `ideal' value would be 50 %). Our preliminary findings suggest potential of CMs outside of their original application, as a supplemental optimization and benchmarking tool to enhance VC technology.
The Voice Conversion Challenge 2018: Promoting Development of Parallel and Nonparallel Methods
Apr 12, 2018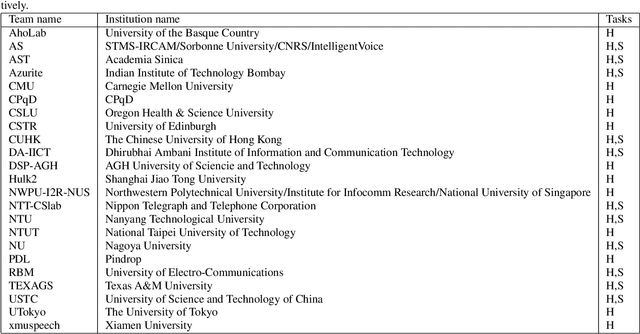
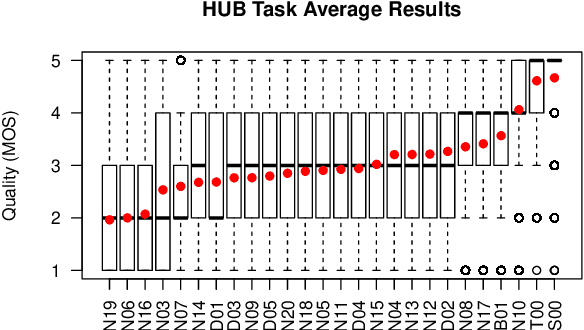
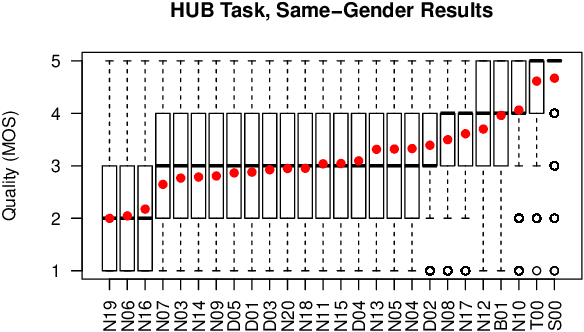
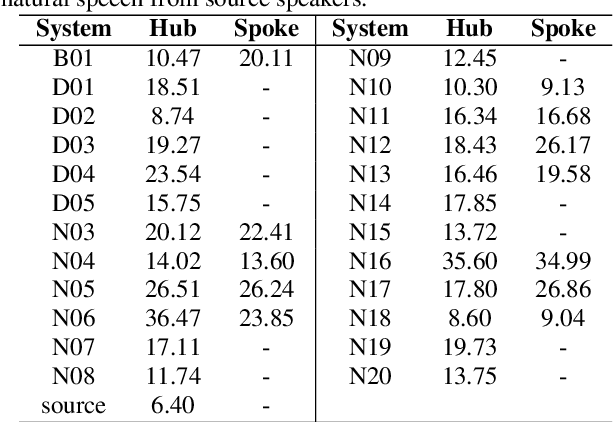
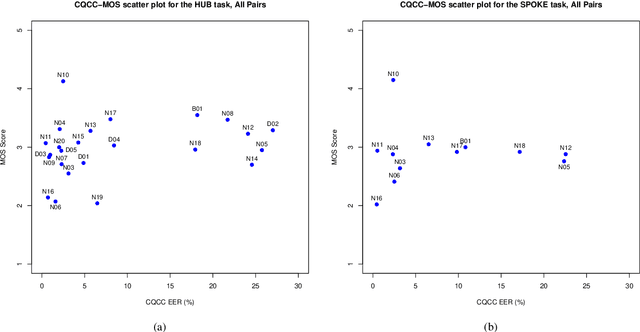
We present the Voice Conversion Challenge 2018, designed as a follow up to the 2016 edition with the aim of providing a common framework for evaluating and comparing different state-of-the-art voice conversion (VC) systems. The objective of the challenge was to perform speaker conversion (i.e. transform the vocal identity) of a source speaker to a target speaker while maintaining linguistic information. As an update to the previous challenge, we considered both parallel and non-parallel data to form the Hub and Spoke tasks, respectively. A total of 23 teams from around the world submitted their systems, 11 of them additionally participated in the optional Spoke task. A large-scale crowdsourced perceptual evaluation was then carried out to rate the submitted converted speech in terms of naturalness and similarity to the target speaker identity. In this paper, we present a brief summary of the state-of-the-art techniques for VC, followed by a detailed explanation of the challenge tasks and the results that were obtained.
A comparison of recent waveform generation and acoustic modeling methods for neural-network-based speech synthesis
Apr 07, 2018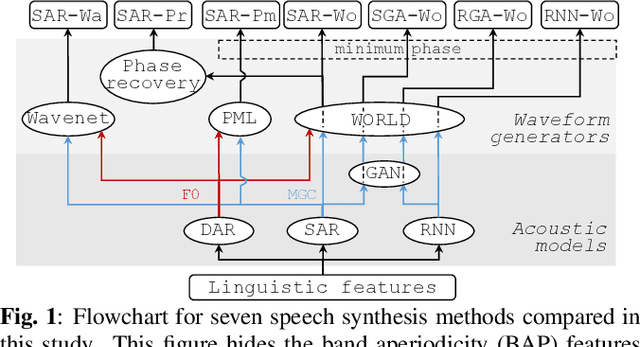
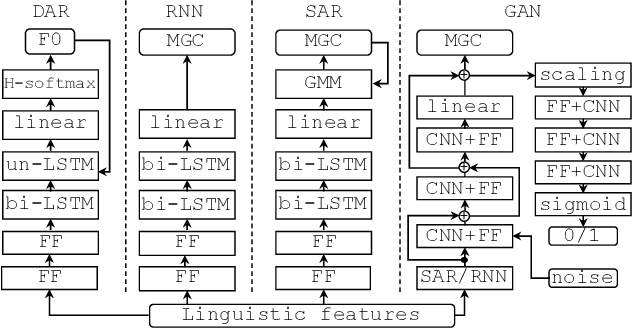
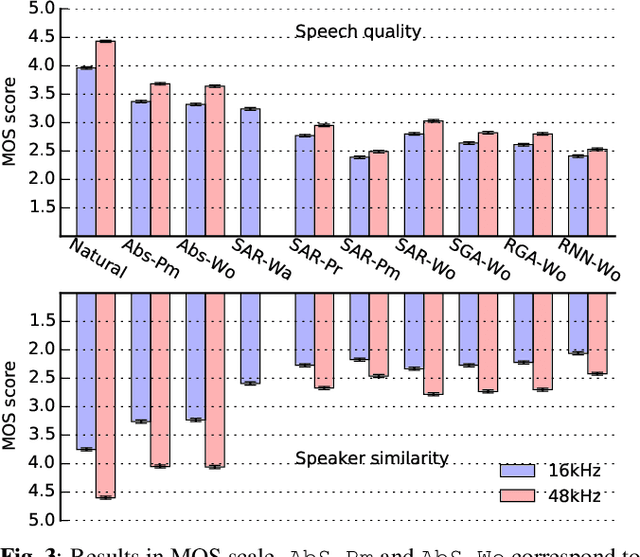
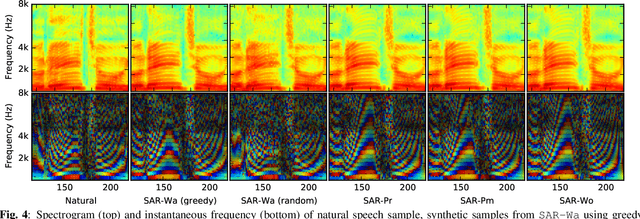
Recent advances in speech synthesis suggest that limitations such as the lossy nature of the amplitude spectrum with minimum phase approximation and the over-smoothing effect in acoustic modeling can be overcome by using advanced machine learning approaches. In this paper, we build a framework in which we can fairly compare new vocoding and acoustic modeling techniques with conventional approaches by means of a large scale crowdsourced evaluation. Results on acoustic models showed that generative adversarial networks and an autoregressive (AR) model performed better than a normal recurrent network and the AR model performed best. Evaluation on vocoders by using the same AR acoustic model demonstrated that a Wavenet vocoder outperformed classical source-filter-based vocoders. Particularly, generated speech waveforms from the combination of AR acoustic model and Wavenet vocoder achieved a similar score of speech quality to vocoded speech.
High-quality nonparallel voice conversion based on cycle-consistent adversarial network
Apr 02, 2018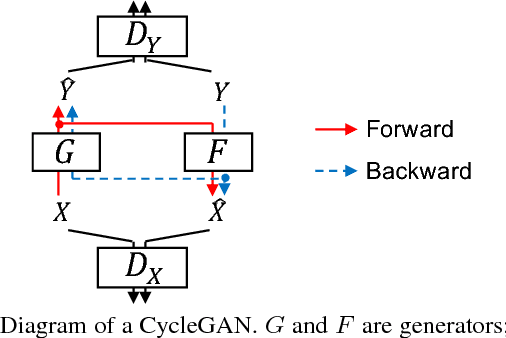
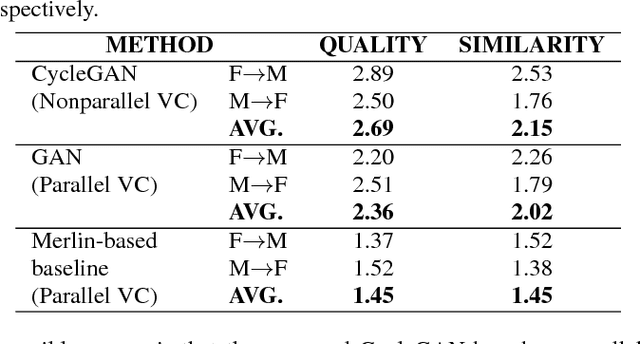
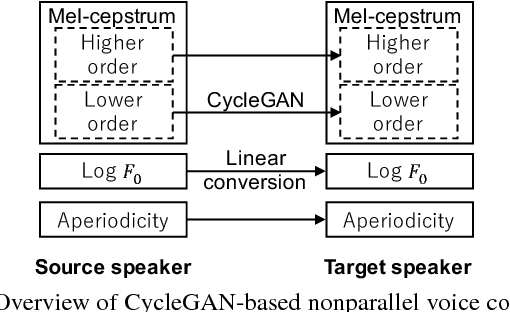
Although voice conversion (VC) algorithms have achieved remarkable success along with the development of machine learning, superior performance is still difficult to achieve when using nonparallel data. In this paper, we propose using a cycle-consistent adversarial network (CycleGAN) for nonparallel data-based VC training. A CycleGAN is a generative adversarial network (GAN) originally developed for unpaired image-to-image translation. A subjective evaluation of inter-gender conversion demonstrated that the proposed method significantly outperformed a method based on the Merlin open source neural network speech synthesis system (a parallel VC system adapted for our setup) and a GAN-based parallel VC system. This is the first research to show that the performance of a nonparallel VC method can exceed that of state-of-the-art parallel VC methods.
Can we steal your vocal identity from the Internet?: Initial investigation of cloning Obama's voice using GAN, WaveNet and low-quality found data
Mar 02, 2018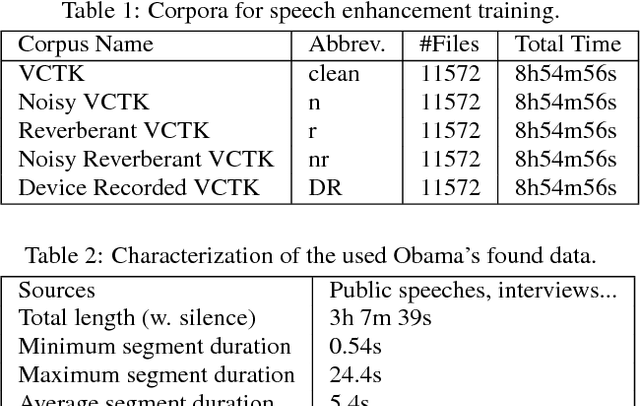
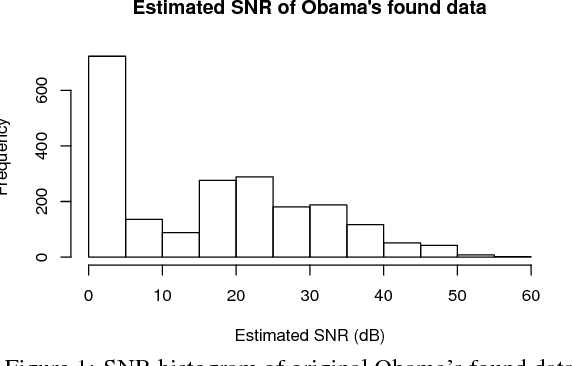
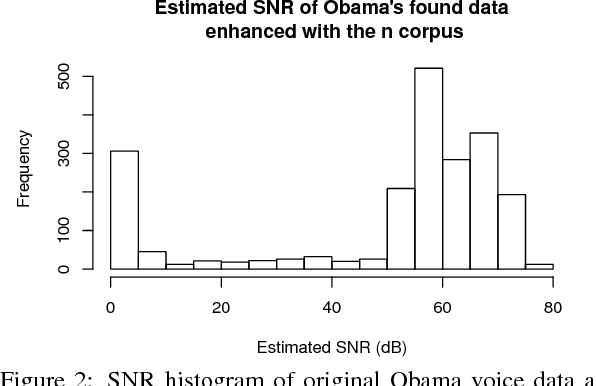
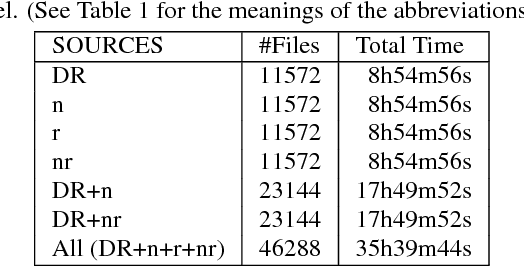
Thanks to the growing availability of spoofing databases and rapid advances in using them, systems for detecting voice spoofing attacks are becoming more and more capable, and error rates close to zero are being reached for the ASVspoof2015 database. However, speech synthesis and voice conversion paradigms that are not considered in the ASVspoof2015 database are appearing. Such examples include direct waveform modelling and generative adversarial networks. We also need to investigate the feasibility of training spoofing systems using only low-quality found data. For that purpose, we developed a generative adversarial network-based speech enhancement system that improves the quality of speech data found in publicly available sources. Using the enhanced data, we trained state-of-the-art text-to-speech and voice conversion models and evaluated them in terms of perceptual speech quality and speaker similarity. The results show that the enhancement models significantly improved the SNR of low-quality degraded data found in publicly available sources and that they significantly improved the perceptual cleanliness of the source speech without significantly degrading the naturalness of the voice. However, the results also show limitations when generating speech with the low-quality found data.