 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation of Attention Heads for Zero-shot Anomaly Detection
May 28, 2025



Zero-shot anomaly detection (ZSAD) in images is an approach that can detect anomalies without access to normal samples, which can be beneficial in various realistic scenarios where model training is not possible. However, existing ZSAD research has shown limitations by either not considering domain adaptation of general-purpose backbone models to anomaly detection domains or by implementing only partial adaptation to some model components. In this paper, we propose HeadCLIP to overcome these limitations by effectively adapting both text and image encoders to the domain. HeadCLIP generalizes the concepts of normality and abnormality through learnable prompts in the text encoder, and introduces learnable head weights to the image encoder to dynamically adjust the features held by each attention head according to domain characteristics. Additionally, we maximize the effect of domain adaptation by introducing a joint anomaly score that utilizes domain-adapted pixel-level information for image-level anomaly detection. Experimental results using multiple real datasets in both industrial and medical domains show that HeadCLIP outperforms existing ZSAD techniques at both pixel and image levels. In the industrial domain, improvements of up to 4.9%p in pixel-level mean anomaly detection score (mAD) and up to 3.0%p in image-level mAD were achieved, with similar improvements (3.2%p, 3.1%p) in the medical domain.
Avoid Wasted Annotation Costs in Open-set Active Learning with Pre-trained Vision-Language Model
Aug 09, 2024Active learning (AL) aims to enhance model performance by selectively collecting highly informative data, thereby minimizing annotation costs. However, in practical scenarios, unlabeled data may contain out-of-distribution (OOD) samples, leading to wasted annotation costs if data is incorrectly selected. Recent research has explored methods to apply AL to open-set data, but these methods often require or incur unavoidable cost losses to minimize them. To address these challenges, we propose a novel selection strategy, CLIPN for AL (CLIPNAL), which minimizes cost losses without requiring OOD samples. CLIPNAL sequentially evaluates the purity and informativeness of data. First, it utilizes a pre-trained vision-language model to detect and exclude OOD data by leveraging linguistic and visual information of in-distribution (ID) data without additional training. Second, it selects highly informative data from the remaining ID data, and then the selected samples are annotated by human experts. Experimental results on datasets with various open-set conditions demonstrate that CLIPNAL achieves the lowest cost loss and highest performance across all scenarios. Code is available at https://github.com/DSBA-Lab/OpenAL.
REVECA -- Rich Encoder-decoder framework for Video Event CAptioner
Jun 18, 2022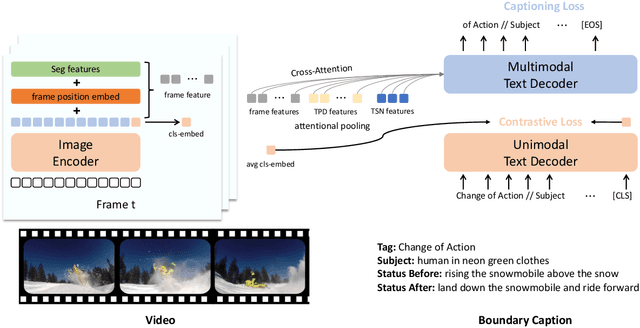
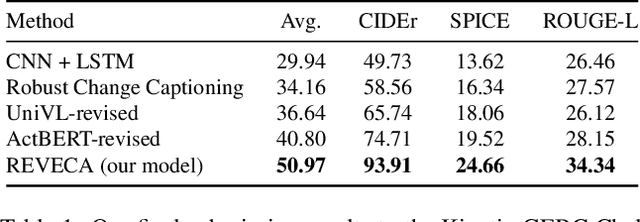
We describe an approach used in the Generic Boundary Event Captioning challenge at the Long-Form Video Understanding Workshop held at CVPR 2022. We designed a Rich Encoder-decoder framework for Video Event CAptioner (REVECA) that utilizes spatial and temporal information from the video to generate a caption for the corresponding the event boundary. REVECA uses frame position embedding to incorporate information before and after the event boundary. Furthermore, it employs features extracted using the temporal segment network and temporal-based pairwise difference method to learn temporal information. A semantic segmentation mask for the attentional pooling process is adopted to learn the subject of an event. Finally, LoRA is applied to fine-tune the image encoder to enhance the learning efficiency. REVECA yielded an average score of 50.97 on the Kinetics-GEBC test data, which is an improvement of 10.17 over the baseline method. Our code is available in https://github.com/TooTouch/REVECA.