 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssociative Compression Networks for Representation Learning
Apr 26, 2018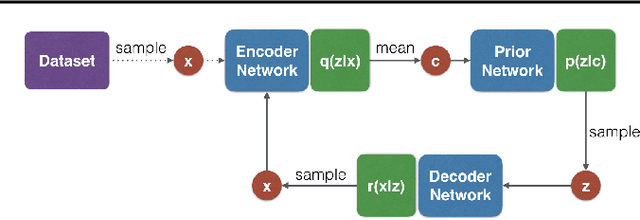
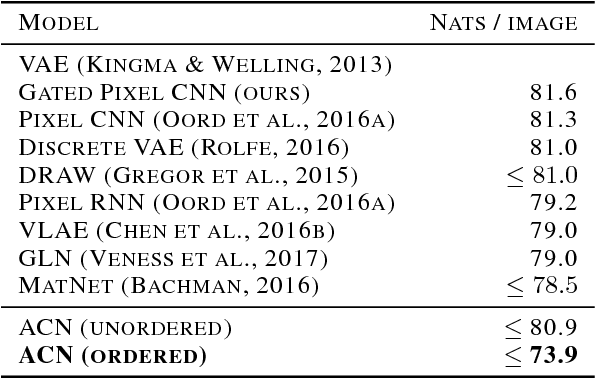

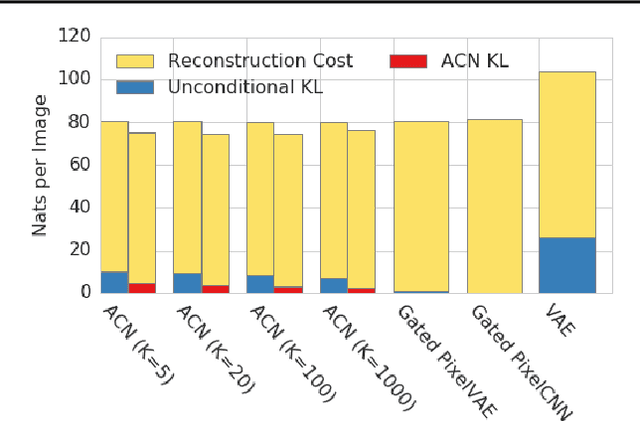
This paper introduces Associative Compression Networks (ACNs), a new framework for variational autoencoding with neural networks. The system differs from existing variational autoencoders (VAEs) in that the prior distribution used to model each code is conditioned on a similar code from the dataset. In compression terms this equates to sequentially transmitting the dataset using an ordering determined by proximity in latent space. Since the prior need only account for local, rather than global variations in the latent space, the coding cost is greatly reduced, leading to rich, informative codes. Crucially, the codes remain informative when powerful, autoregressive decoders are used, which we argue is fundamentally difficult with normal VAEs. Experimental results on MNIST, CIFAR-10, ImageNet and CelebA show that ACNs discover high-level latent features such as object class, writing style, pose and facial expression, which can be used to cluster and classify the data, as well as to generate diverse and convincing samples. We conclude that ACNs are a promising new direction for representation learning: one that steps away from IID modelling, and towards learning a structured description of the dataset as a whole.
Noisy Networks for Exploration
Feb 15, 2018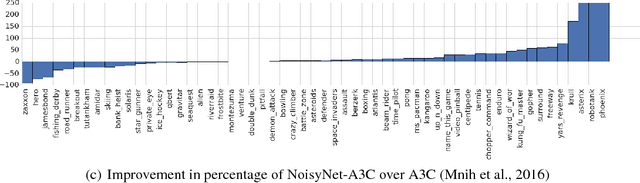
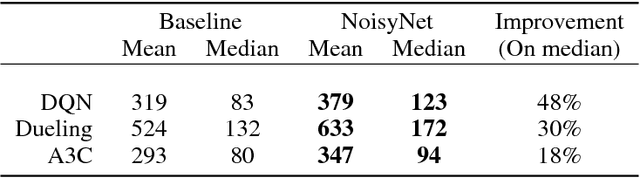
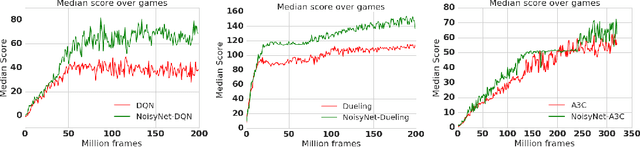
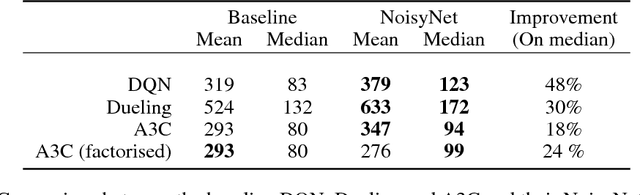
We introduce NoisyNet, a deep reinforcement learning agent with parametric noise added to its weights, and show that the induced stochasticity of the agent's policy can be used to aid efficient exploration. The parameters of the noise are learned with gradient descent along with the remaining network weights. NoisyNet is straightforward to implement and adds little computational overhead. We find that replacing the conventional exploration heuristics for A3C, DQN and dueling agents (entropy reward and $\epsilon$-greedy respectively) with NoisyNet yields substantially higher scores for a wide range of Atari games, in some cases advancing the agent from sub to super-human performance.
Automated Curriculum Learning for Neural Networks
Apr 10, 2017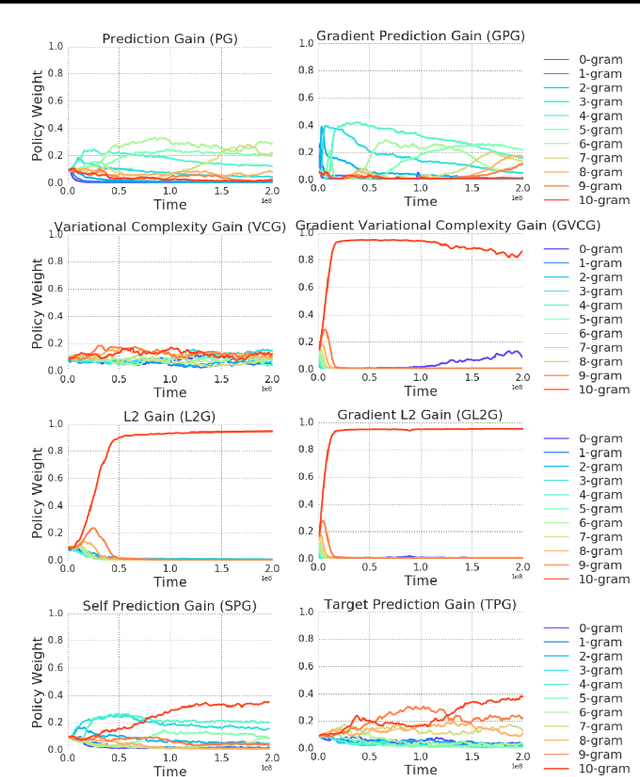
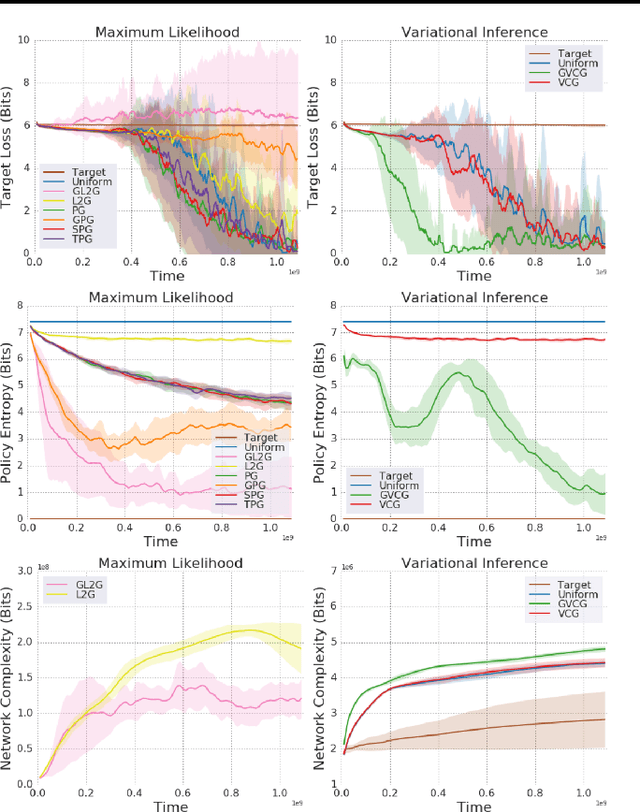
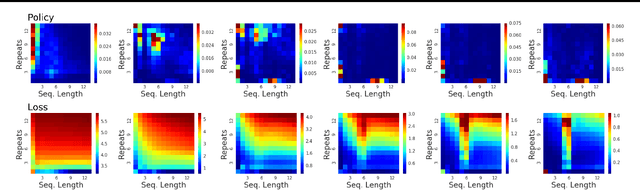
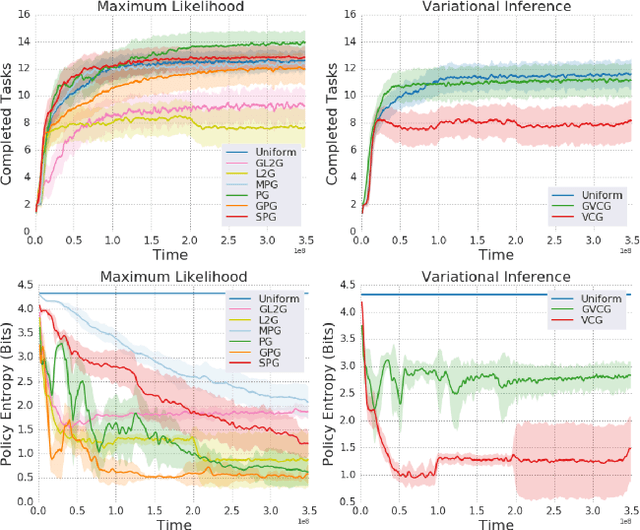
We introduce a method for automatically selecting the path, or syllabus, that a neural network follows through a curriculum so as to maximise learning efficiency. A measure of the amount that the network learns from each data sample is provided as a reward signal to a nonstationary multi-armed bandit algorithm, which then determines a stochastic syllabus. We consider a range of signals derived from two distinct indicators of learning progress: rate of increase in prediction accuracy, and rate of increase in network complexity. Experimental results for LSTM networks on three curricula demonstrate that our approach can significantly accelerate learning, in some cases halving the time required to attain a satisfactory performance level.