 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMNEW: Multi-domain Neighborhood Embedding and Weighting for Sparse Point Clouds Segmentation
Apr 05, 2020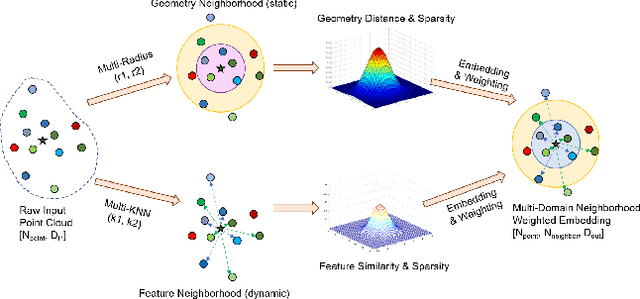
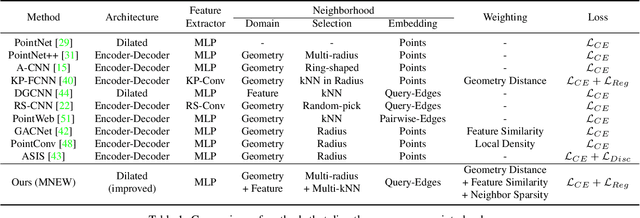


Point clouds have been widely adopted in 3D semantic scene understanding. However, point clouds for typical tasks such as 3D shape segmentation or indoor scenario parsing are much denser than outdoor LiDAR sweeps for the application of autonomous driving perception. Due to the spatial property disparity, many successful methods designed for dense point clouds behave depreciated effectiveness on the sparse data. In this paper, we focus on the semantic segmentation task of sparse outdoor point clouds. We propose a new method called MNEW, including multi-domain neighborhood embedding, and attention weighting based on their geometry distance, feature similarity, and neighborhood sparsity. The network architecture inherits PointNet which directly process point clouds to capture pointwise details and global semantics, and is improved by involving multi-scale local neighborhoods in static geometry domain and dynamic feature space. The distance/similarity attention and sparsity-adapted weighting mechanism of MNEW enable its capability for a wide range of data sparsity distribution. With experiments conducted on virtual and real KITTI semantic datasets, MNEW achieves the top performance for sparse point clouds, which is important to the application of LiDAR-based automated driving perception.
GFD-SSD: Gated Fusion Double SSD for Multispectral Pedestrian Detection
Mar 21, 2019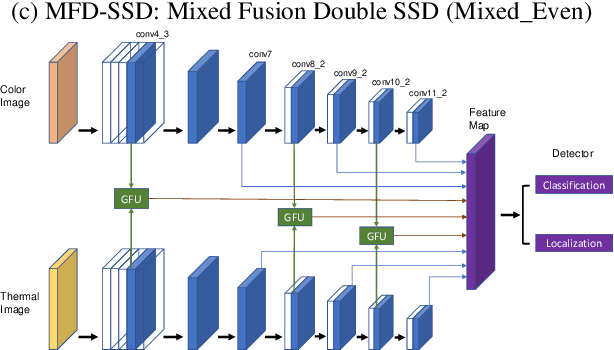
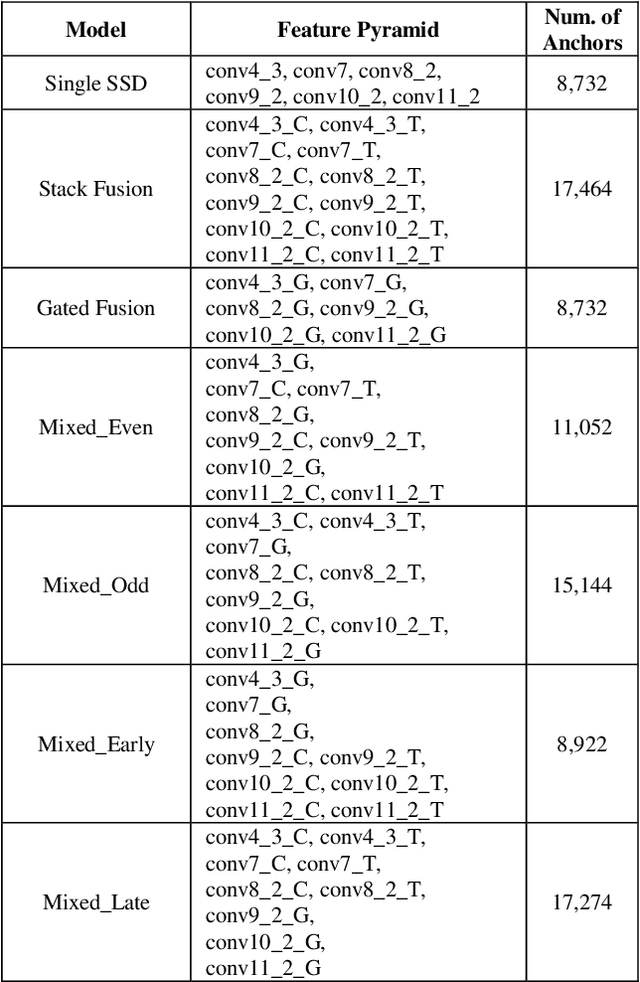
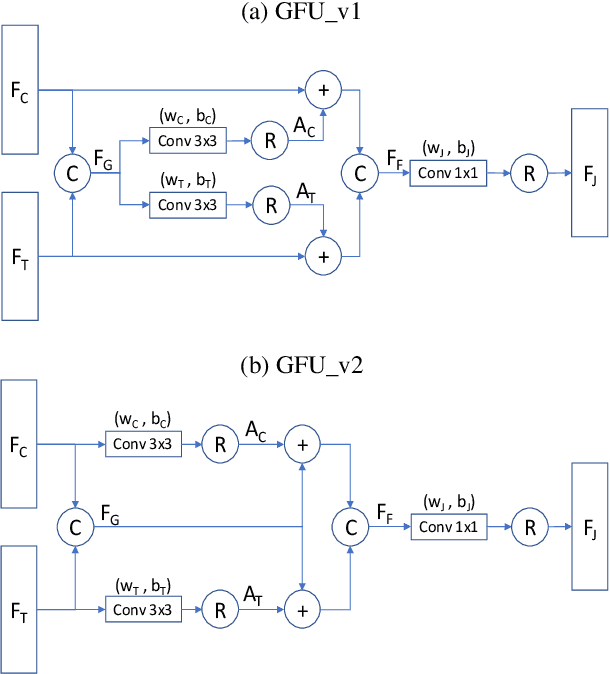

Pedestrian detection is an essential task in autonomous driving research. In addition to typical color images, thermal images benefit the detection in dark environments. Hence, it is worthwhile to explore an integrated approach to take advantage of both color and thermal images simultaneously. In this paper, we propose a novel approach to fuse color and thermal sensors using deep neural networks (DNN). Current state-of-the-art DNN object detectors vary from two-stage to one-stage mechanisms. Two-stage detectors, like Faster-RCNN, achieve higher accuracy, while one-stage detectors such as Single Shot Detector (SSD) demonstrate faster performance. To balance the trade-off, especially in the consideration of autonomous driving applications, we investigate a fusion strategy to combine two SSDs on color and thermal inputs. Traditional fusion methods stack selected features from each channel and adjust their weights. In this paper, we propose two variations of novel Gated Fusion Units (GFU), that learn the combination of feature maps generated by the two SSD middle layers. Leveraging GFUs for the entire feature pyramid structure, we propose several mixed versions of both stack fusion and gated fusion. Experiments are conducted on the KAIST multispectral pedestrian detection dataset. Our Gated Fusion Double SSD (GFD-SSD) outperforms the stacked fusion and achieves the lowest miss rate in the benchmark, at an inference speed that is two times faster than Faster-RCNN based fusion networks.
Exploring OpenStreetMap Availability for Driving Environment Understanding
Mar 11, 2019



With the great achievement of artificial intelligence, vehicle technologies have advanced significantly from human centric driving towards fully automated driving. An intelligent vehicle should be able to understand the driver's perception of the environment as well as controlling behavior of the vehicle. Since high digital map information has been available to provide rich environmental context about static roads, buildings and traffic infrastructures, it would be worthwhile to explore map data capability for driving task understanding. Alternative to commercial used maps, the OpenStreetMap (OSM) data is a free open dataset, which makes it unique for the exploration research. This study is focused on two tasks that leverage OSM for driving environment understanding. First, driving scenario attributes are retrieved from OSM elements, which are combined with vehicle dynamic signals for the driving event recognition. Utilizing steering angle changes and based on a Bi-directional Recurrent Neural Network (Bi-RNN), a driving sequence is segmented and classified as lane-keeping, lane-change-left, lane-change-right, turn-left, and turn-right events. Second, for autonomous driving perception, OSM data can be used to render virtual street views, represented as prior knowledge to fuse with vision/laser systems for road semantic segmentation. Five different types of road masks are generated from OSM, images, and Lidar points, and fused to characterize the drivable space at the driver's perspective. An alternative data-driven approach is based on a Fully Convolutional Network (FCN), OSM availability for deep learning methods are discussed to reveal potential usage on compensating street view images and automatic road semantic annotation.