 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Restless to Contextual: A Thresholding Bandit Approach to Improve Finite-horizon Performance
Feb 07, 2025



Online restless bandits extend classic contextual bandits by incorporating state transitions and budget constraints, representing each agent as a Markov Decision Process (MDP). This framework is crucial for finite-horizon strategic resource allocation, optimizing limited costly interventions for long-term benefits. However, learning the underlying MDP for each agent poses a major challenge in finite-horizon settings. To facilitate learning, we reformulate the problem as a scalable budgeted thresholding contextual bandit problem, carefully integrating the state transitions into the reward design and focusing on identifying agents with action benefits exceeding a threshold. We establish the optimality of an oracle greedy solution in a simple two-state setting, and propose an algorithm that achieves minimax optimal constant regret in the online multi-state setting with heterogeneous agents and knowledge of outcomes under no intervention. We numerically show that our algorithm outperforms existing online restless bandit methods, offering significant improvements in finite-horizon performance.
The Digital Transformation in Health: How AI Can Improve the Performance of Health Systems
Sep 24, 2024Mobile health has the potential to revolutionize health care delivery and patient engagement. In this work, we discuss how integrating Artificial Intelligence into digital health applications-focused on supply chain, patient management, and capacity building, among other use cases-can improve the health system and public health performance. We present an Artificial Intelligence and Reinforcement Learning platform that allows the delivery of adaptive interventions whose impact can be optimized through experimentation and real-time monitoring. The system can integrate multiple data sources and digital health applications. The flexibility of this platform to connect to various mobile health applications and digital devices and send personalized recommendations based on past data and predictions can significantly improve the impact of digital tools on health system outcomes. The potential for resource-poor settings, where the impact of this approach on health outcomes could be more decisive, is discussed specifically. This framework is, however, similarly applicable to improving efficiency in health systems where scarcity is not an issue.
Adaptive User Journeys in Pharma E-Commerce with Reinforcement Learning: Insights from SwipeRx
Aug 15, 2024



This paper introduces a reinforcement learning (RL) platform that enhances end-to-end user journeys in healthcare digital tools through personalization. We explore a case study with SwipeRx, the most popular all-in-one app for pharmacists in Southeast Asia, demonstrating how the platform can be used to personalize and adapt user experiences. Our RL framework is tested through a series of experiments with product recommendations tailored to each pharmacy based on real-time information on their purchasing history and in-app engagement, showing a significant increase in basket size. By integrating adaptive interventions into existing mobile health solutions and enriching user journeys, our platform offers a scalable solution to improve pharmaceutical supply chain management, health worker capacity building, and clinical decision and patient care, ultimately contributing to better healthcare outcomes.
Optimizing HIV Patient Engagement with Reinforcement Learning in Resource-Limited Settings
Aug 14, 2024

By providing evidence-based clinical decision support, digital tools and electronic health records can revolutionize patient management, especially in resource-poor settings where fewer health workers are available and often need more training. When these tools are integrated with AI, they can offer personalized support and adaptive interventions, effectively connecting community health workers (CHWs) and healthcare facilities. The CHARM (Community Health Access & Resource Management) app is an AI-native mobile app for CHWs. Developed through a joint partnership of Causal Foundry (CF) and mothers2mothers (m2m), CHARM empowers CHWs, mainly local women, by streamlining case management, enhancing learning, and improving communication. This paper details CHARM's development, integration, and upcoming reinforcement learning-based adaptive interventions, all aimed at enhancing health worker engagement, efficiency, and patient outcomes, thereby enhancing CHWs' capabilities and community health.
Adaptive Behavioral AI: Reinforcement Learning to Enhance Pharmacy Services
Aug 14, 2024


Pharmacies are critical in healthcare systems, particularly in low- and middle-income countries. Procuring pharmacists with the right behavioral interventions or nudges can enhance their skills, public health awareness, and pharmacy inventory management, ensuring access to essential medicines that ultimately benefit their patients. We introduce a reinforcement learning operational system to deliver personalized behavioral interventions through mobile health applications. We illustrate its potential by discussing a series of initial experiments run with SwipeRx, an all-in-one app for pharmacists, including B2B e-commerce, in Indonesia. The proposed method has broader applications extending beyond pharmacy operations to optimize healthcare delivery.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022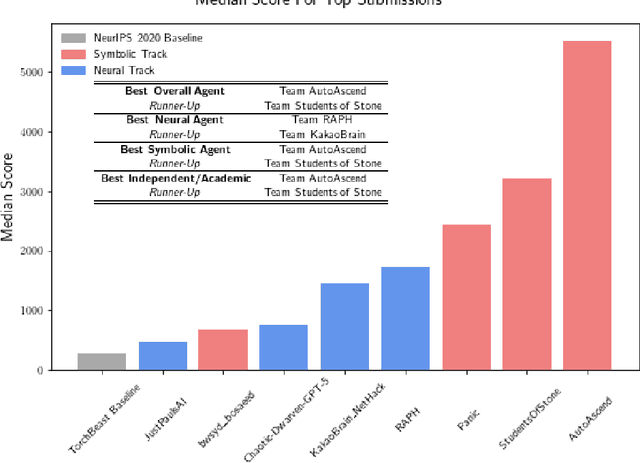

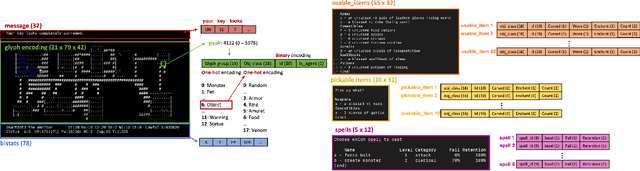
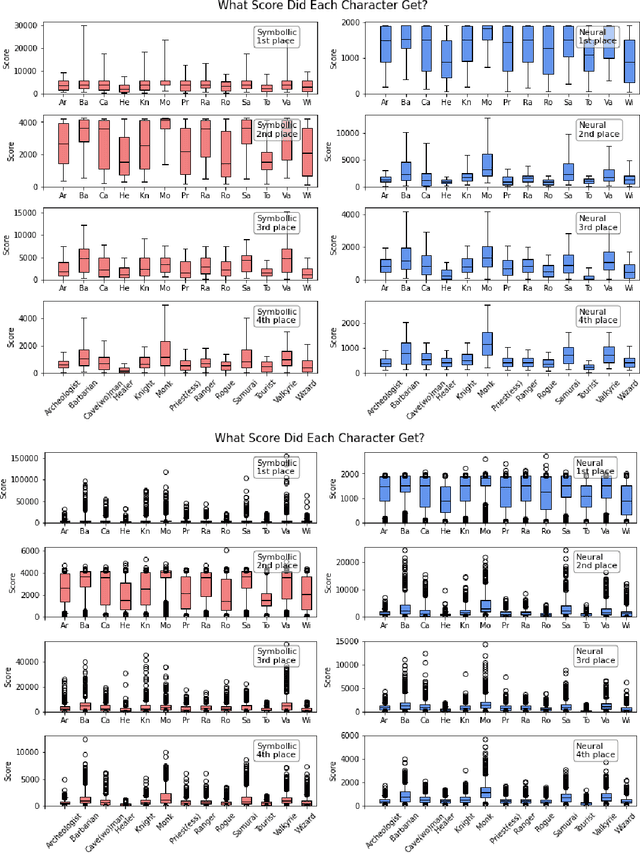
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.
Project Achoo: A Practical Model and Application for COVID-19 Detection from Recordings of Breath, Voice, and Cough
Jul 12, 2021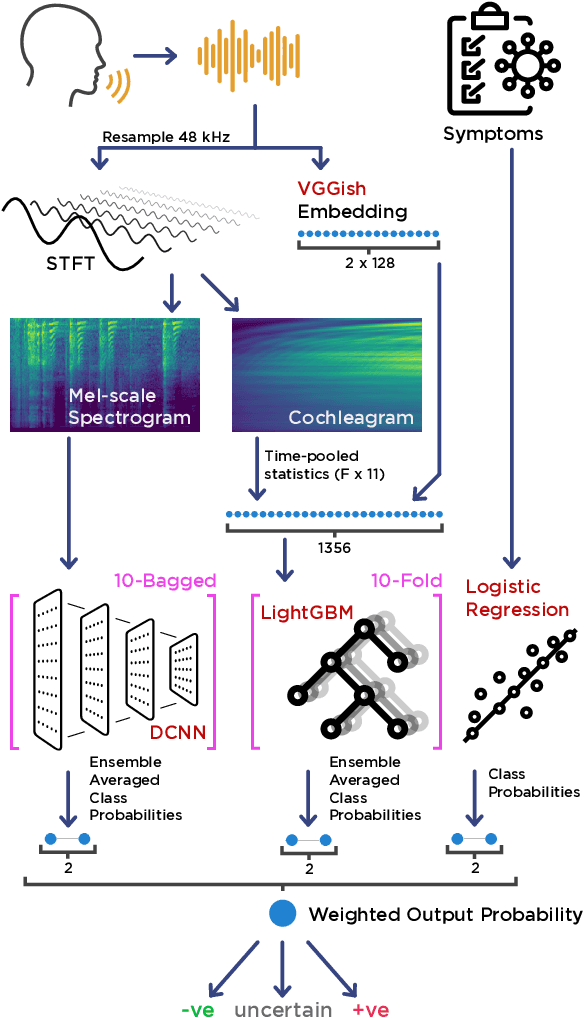
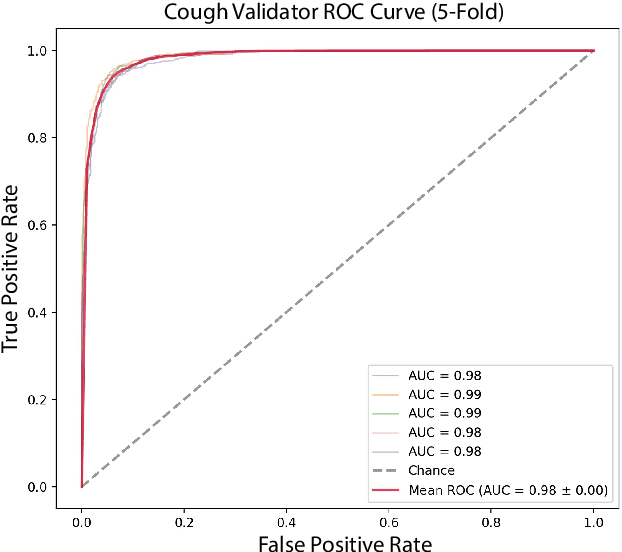
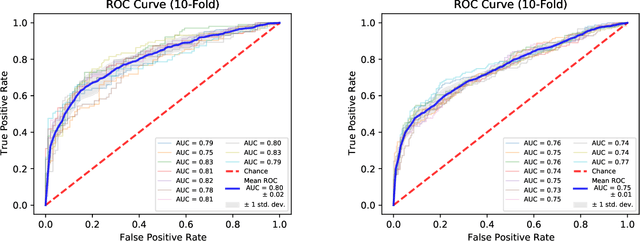
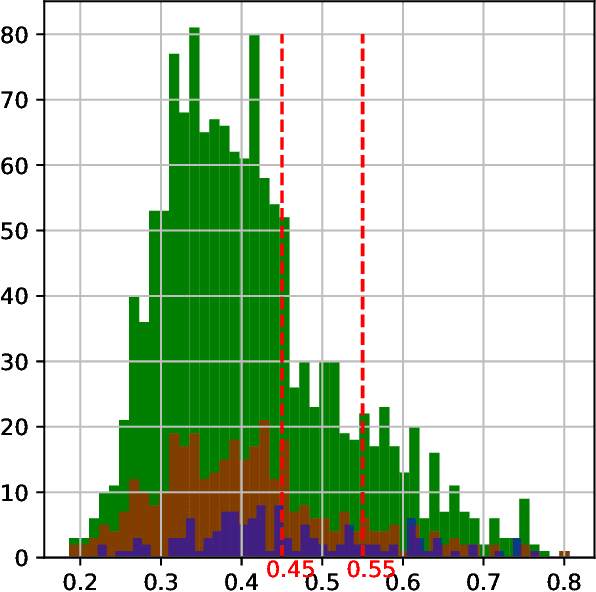
The COVID-19 pandemic created a significant interest and demand for infection detection and monitoring solutions. In this paper we propose a machine learning method to quickly triage COVID-19 using recordings made on consumer devices. The approach combines signal processing methods with fine-tuned deep learning networks and provides methods for signal denoising, cough detection and classification. We have also developed and deployed a mobile application that uses symptoms checker together with voice, breath and cough signals to detect COVID-19 infection. The application showed robust performance on both open sourced datasets and on the noisy data collected during beta testing by the end users.
Topology-based Clusterwise Regression for User Segmentation and Demand Forecasting
Sep 08, 2020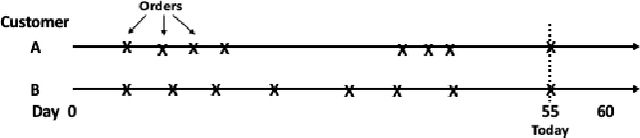
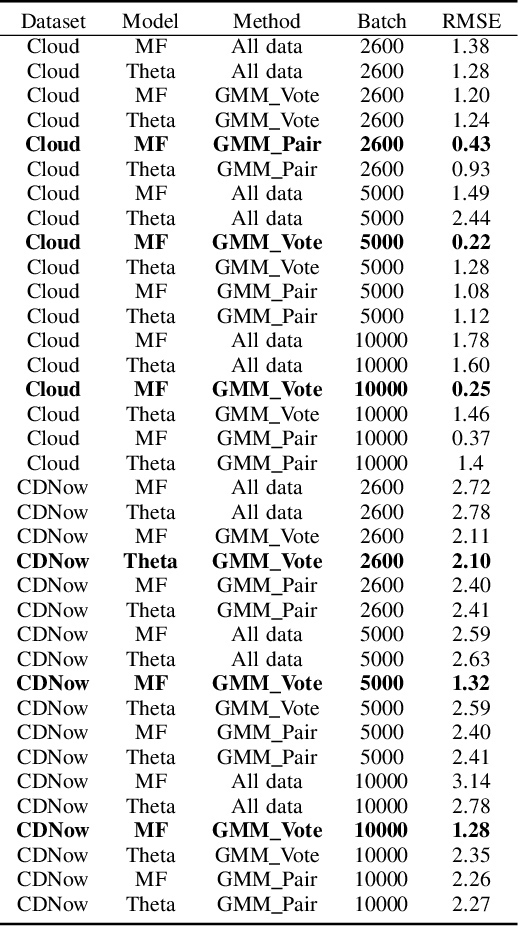

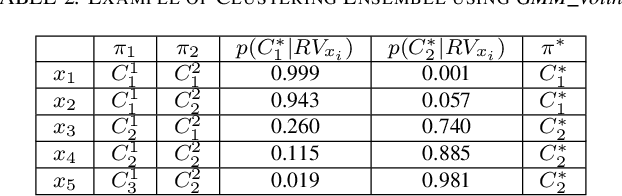
Topological Data Analysis (TDA) is a recent approach to analyze data sets from the perspective of their topological structure. Its use for time series data has been limited. In this work, a system developed for a leading provider of cloud computing combining both user segmentation and demand forecasting is presented. It consists of a TDA-based clustering method for time series inspired by a popular managerial framework for customer segmentation and extended to the case of clusterwise regression using matrix factorization methods to forecast demand. Increasing customer loyalty and producing accurate forecasts remain active topics of discussion both for researchers and managers. Using a public and a novel proprietary data set of commercial data, this research shows that the proposed system enables analysts to both cluster their user base and plan demand at a granular level with significantly higher accuracy than a state of the art baseline. This work thus seeks to introduce TDA-based clustering of time series and clusterwise regression with matrix factorization methods as viable tools for the practitioner.
Bayesian Sparsification Methods for Deep Complex-valued Networks
Mar 25, 2020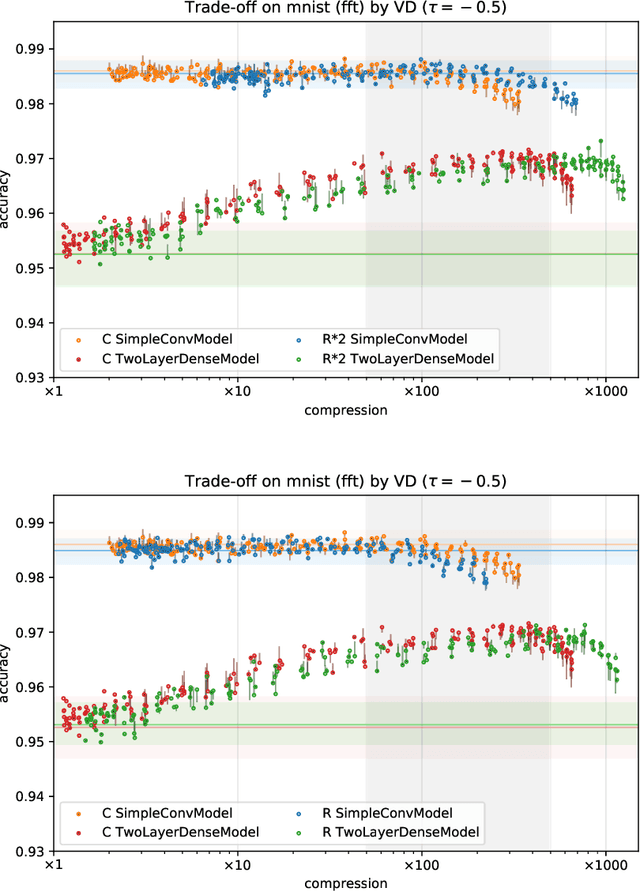
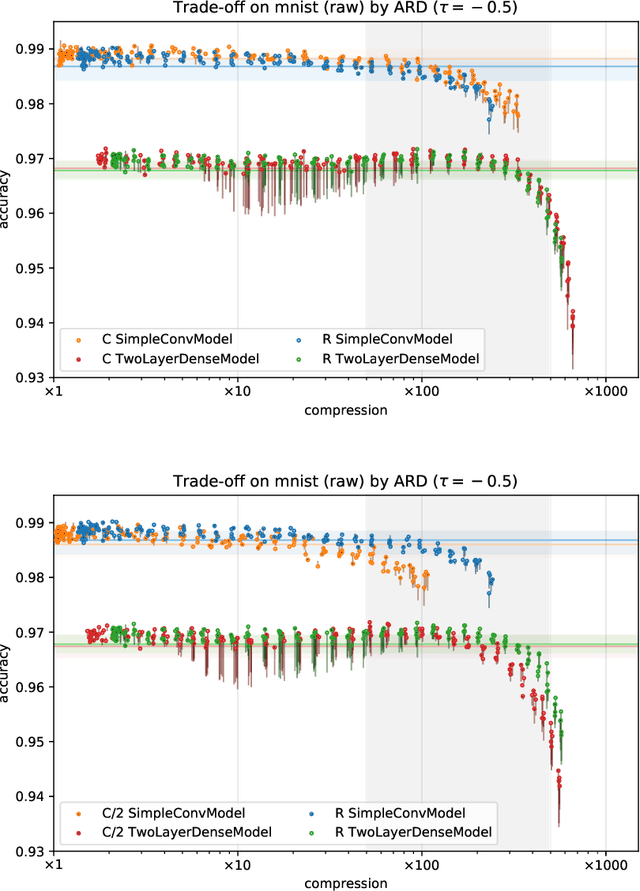
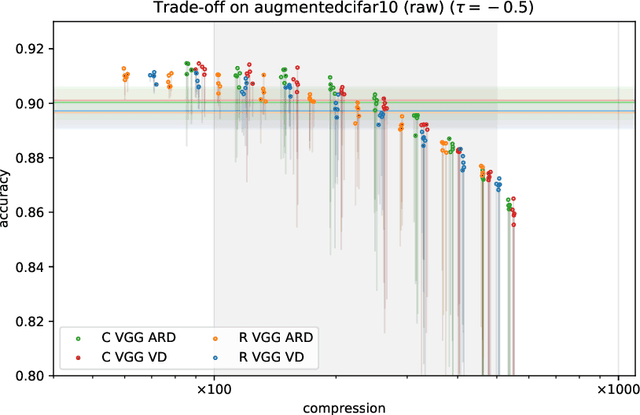
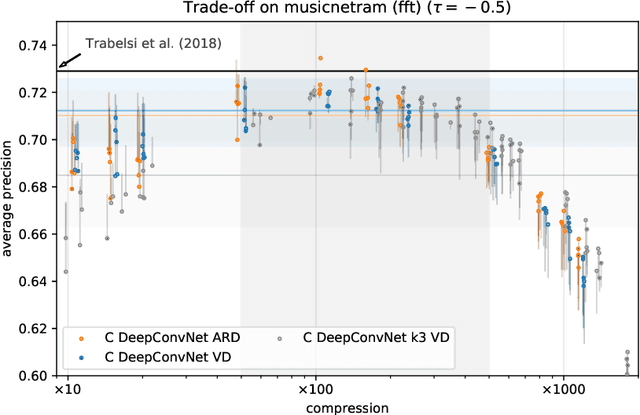
With continual miniaturization ever more applications of deep learning can be found in embedded systems, where it is common to encounter data with natural complex domain representation. To this end we extend Sparse Variational Dropout to complex-valued neural networks and verify the proposed Bayesian technique by conducting a large numerical study of the performance-compression trade-off of C-valued networks on two tasks: image recognition on MNIST-like and CIFAR10 datasets and music transcription on MusicNet. We replicate the state-of-the-art result by Trabelsi et al. [2018] on MusicNet with a complex-valued network compressed by 50-100x at a small performance penalty.
Demand forecasting techniques for build-to-order lean manufacturing supply chains
May 20, 2019
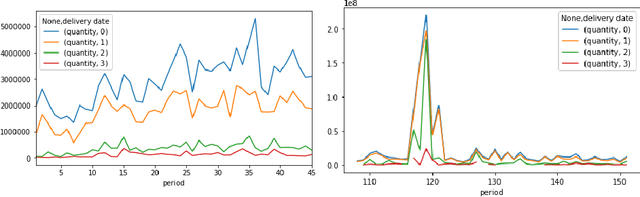
Build-to-order (BTO) supply chains have become common-place in industries such as electronics, automotive and fashion. They enable building products based on individual requirements with a short lead time and minimum inventory and production costs. Due to their nature, they differ significantly from traditional supply chains. However, there have not been studies dedicated to demand forecasting methods for this type of setting. This work makes two contributions. First, it presents a new and unique data set from a manufacturer in the BTO sector. Second, it proposes a novel data transformation technique for demand forecasting of BTO products. Results from thirteen forecasting methods show that the approach compares well to the state-of-the-art while being easy to implement and to explain to decision-makers.
* 10 pages, 2 figures