 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Minimax Error Rate for Crowdsourcing and Its Application to Worker Clustering Model
Jun 09, 2018
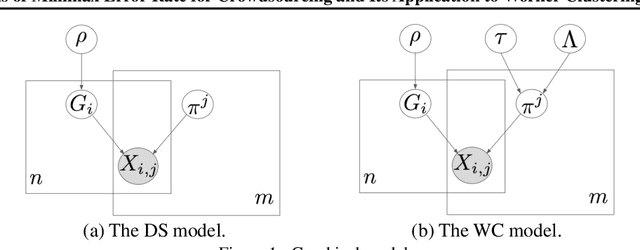
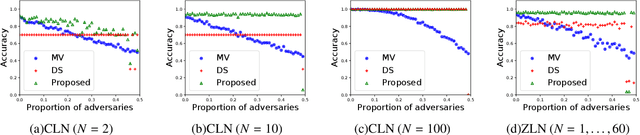
While crowdsourcing has become an important means to label data, there is great interest in estimating the ground truth from unreliable labels produced by crowdworkers. The Dawid and Skene (DS) model is one of the most well-known models in the study of crowdsourcing. Despite its practical popularity, theoretical error analysis for the DS model has been conducted only under restrictive assumptions on class priors, confusion matrices, or the number of labels each worker provides. In this paper, we derive a minimax error rate under more practical setting for a broader class of crowdsourcing models including the DS model as a special case. We further propose the worker clustering model, which is more practical than the DS model under real crowdsourcing settings. The wide applicability of our theoretical analysis allows us to immediately investigate the behavior of this proposed model, which can not be analyzed by existing studies. Experimental results showed that there is a strong similarity between the lower bound of the minimax error rate derived by our theoretical analysis and the empirical error of the estimated value.
Frank-Wolfe Stein Sampling
May 21, 2018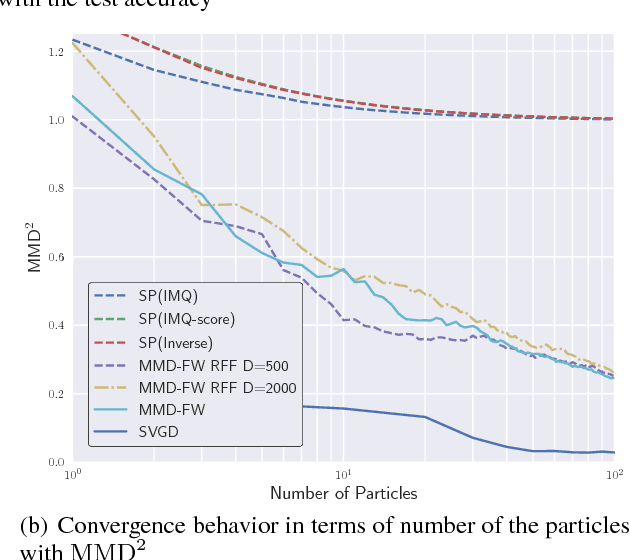

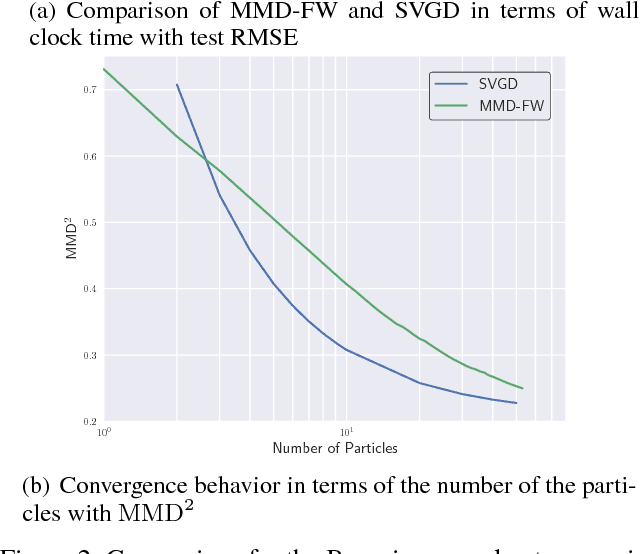
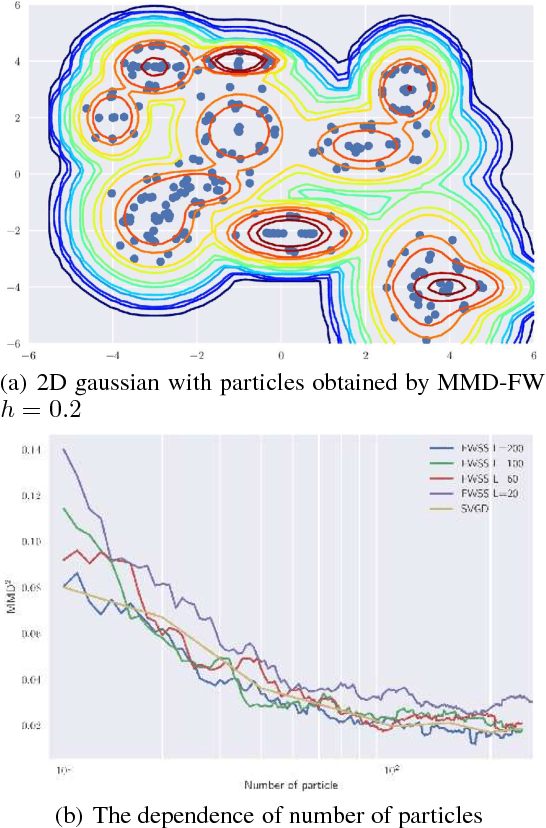
In Bayesian inference, the posterior distributions are difficult to obtain analytically for complex models such as neural networks. Variational inference usually uses a parametric distribution to approximate, from which we can easily draw samples. Recently discrete approximation by particles has attracted attention because of its expressive ability. An example is Stein variational gradient descent (SVGD), which iteratively optimizes particles. Although SVGD has been shown to be computationally efficient empirically, its theoretical properties have not been clarified yet and no finite sample bound of a convergence rate is known. Another example is Stein points (SP), which minimizes kernelized Stein discrepancy directly. The finite sample bound of SP is $\mathcal{O}(\sqrt{\log{N}/N})$ for $N$ particles, which is computationally inefficient empirically, especially in high-dimensional problems. In this paper, we propose a novel method named \emph{Frank-Wolfe Stein sampling}, which minimizes the maximum mean discrepancy in a greedy way. Our method is computationally efficient empirically and theoretically achieves a faster convergence rate, $\mathcal{O}(e^{-N})$. Numerical experiments show the superiority of our method.
Convex Formulation of Multiple Instance Learning from Positive and Unlabeled Bags
May 01, 2018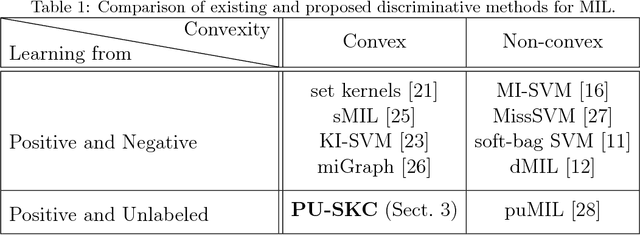
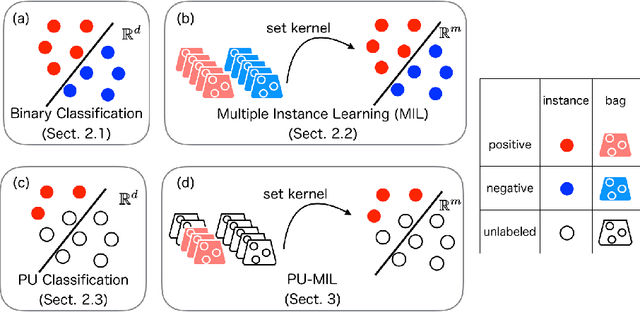
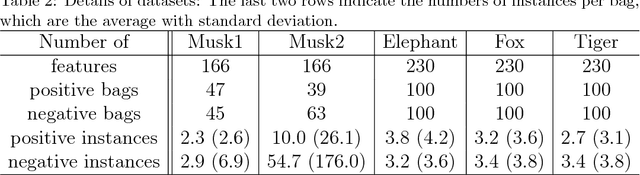
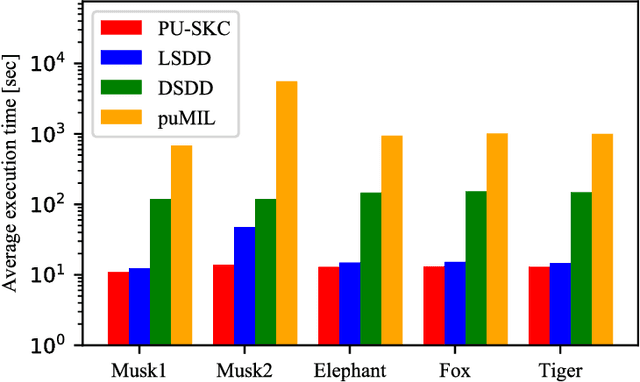
Multiple instance learning (MIL) is a variation of traditional supervised learning problems where data (referred to as bags) are composed of sub-elements (referred to as instances) and only bag labels are available. MIL has a variety of applications such as content-based image retrieval, text categorization and medical diagnosis. Most of the previous work for MIL assume that the training bags are fully labeled. However, it is often difficult to obtain an enough number of labeled bags in practical situations, while many unlabeled bags are available. A learning framework called PU learning (positive and unlabeled learning) can address this problem. In this paper, we propose a convex PU learning method to solve an MIL problem. We experimentally show that the proposed method achieves better performance with significantly lower computational costs than an existing method for PU-MIL.
Bayesian Nonparametric Poisson-Process Allocation for Time-Sequence Modeling
Apr 03, 2018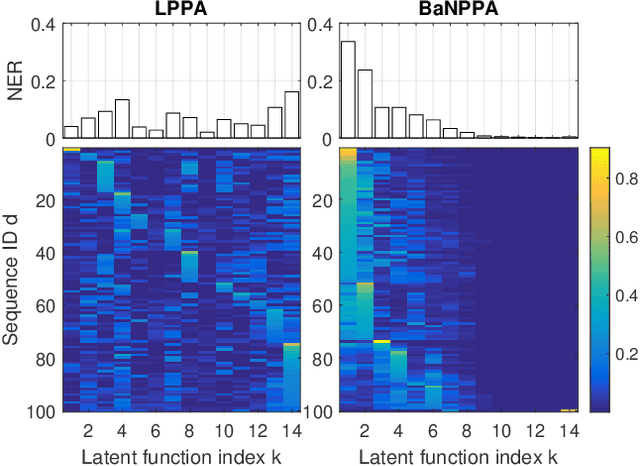
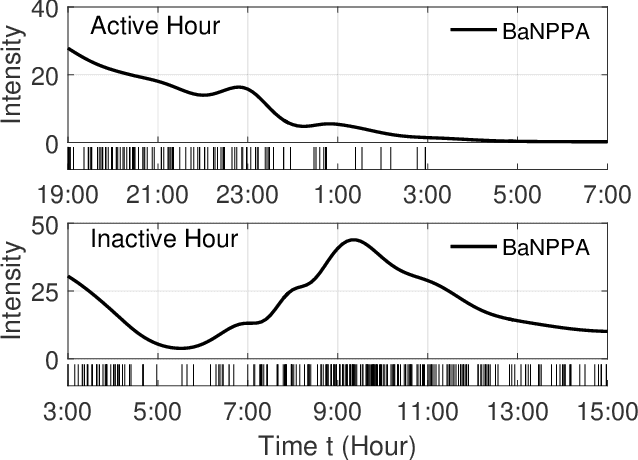
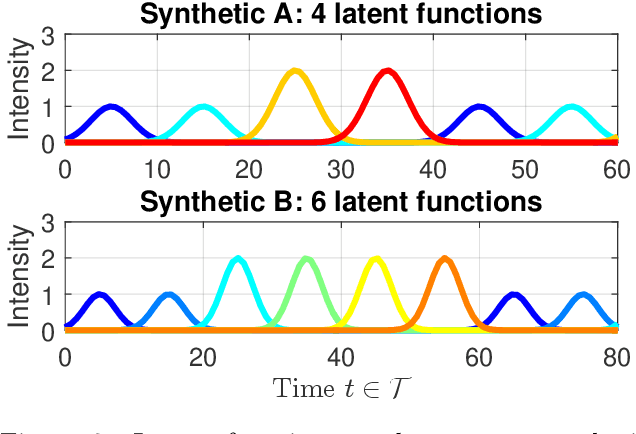
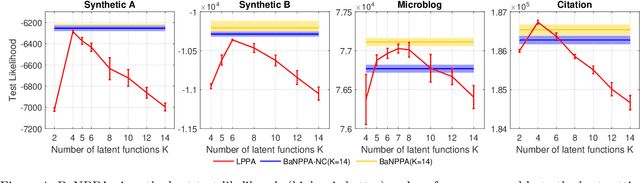
Analyzing the underlying structure of multiple time-sequences provides insights into the understanding of social networks and human activities. In this work, we present the \emph{Bayesian nonparametric Poisson process allocation} (BaNPPA), a latent-function model for time-sequences, which automatically infers the number of latent functions. We model the intensity of each sequence as an infinite mixture of latent functions, each of which is obtained using a function drawn from a Gaussian process. We show that a technical challenge for the inference of such mixture models is the unidentifiability of the weights of the latent functions. We propose to cope with the issue by regulating the volume of each latent function within a variational inference algorithm. Our algorithm is computationally efficient and scales well to large data sets. We demonstrate the usefulness of our proposed model through experiments on both synthetic and real-world data sets.
Variational Inference for Gaussian Process with Panel Count Data
Mar 12, 2018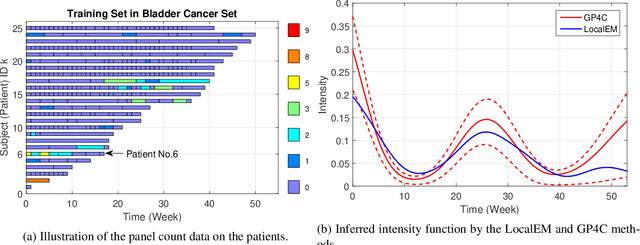
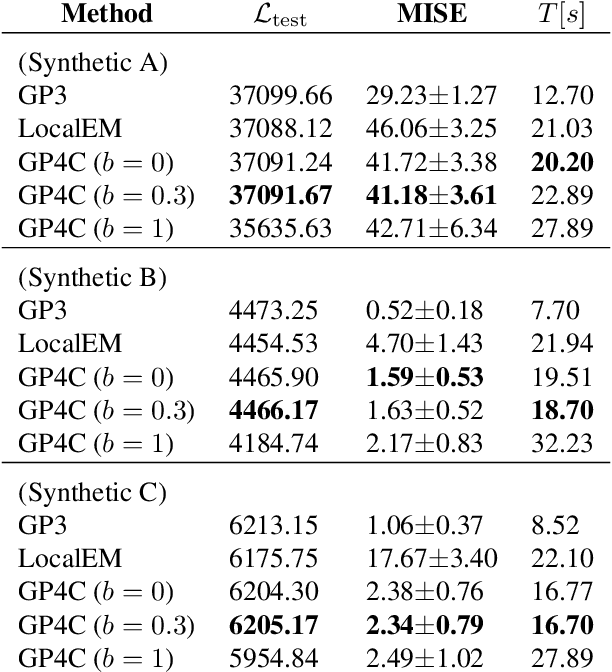
We present the first framework for Gaussian-process-modulated Poisson processes when the temporal data appear in the form of panel counts. Panel count data frequently arise when experimental subjects are observed only at discrete time points and only the numbers of occurrences of the events between subsequent observation times are available. The exact occurrence timestamps of the events are unknown. The method of conducting the efficient variational inference is presented, based on the assumption of a Gaussian-process-modulated intensity function. We derive a tractable lower bound to alleviate the problems of the intractable evidence lower bound inherent in the variational inference framework. Our algorithm outperforms classical methods on both synthetic and three real panel count sets.
Variational Inference based on Robust Divergences
Feb 28, 2018

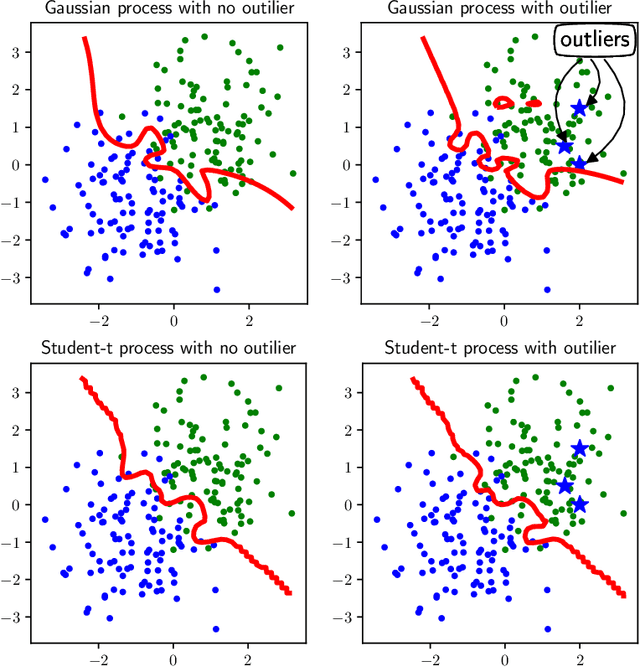
Robustness to outliers is a central issue in real-world machine learning applications. While replacing a model to a heavy-tailed one (e.g., from Gaussian to Student-t) is a standard approach for robustification, it can only be applied to simple models. In this paper, based on Zellner's optimization and variational formulation of Bayesian inference, we propose an outlier-robust pseudo-Bayesian variational method by replacing the Kullback-Leibler divergence used for data fitting to a robust divergence such as the beta- and gamma-divergences. An advantage of our approach is that superior but complex models such as deep networks can also be handled. We theoretically prove that, for deep networks with ReLU activation functions, the \emph{influence function} in our proposed method is bounded, while it is unbounded in the ordinary variational inference. This implies that our proposed method is robust to both of input and output outliers, while the ordinary variational method is not. We experimentally demonstrate that our robust variational method outperforms ordinary variational inference in regression and classification with deep networks.
Gaussian Process Classification with Privileged Information by Soft-to-Hard Labeling Transfer
Feb 12, 2018
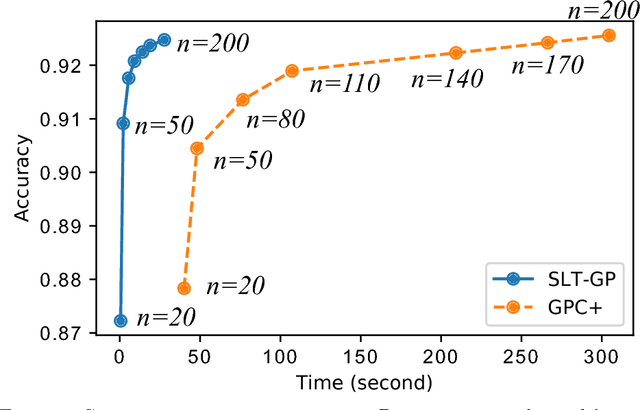
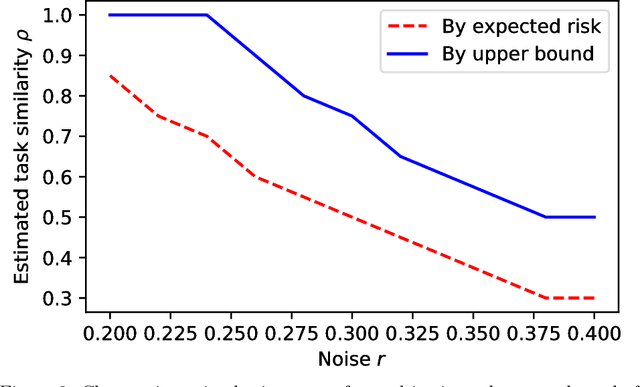
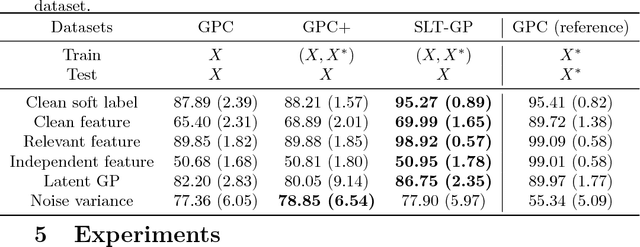
Learning using privileged information is an attractive problem setting that helps many learning scenarios in the real world. A state-of-the-art method of Gaussian process classification (GPC) with privileged information is GPC+, which incorporates privileged information into a noise term of the likelihood. A drawback of GPC+ is that it requires numerical quadrature to calculate the posterior distribution of the latent function, which is extremely time-consuming. To overcome this limitation, we propose a novel classification method with privileged information based on Gaussian processes, called "soft-label-transferred Gaussian process (SLT-GP)." Our basic idea is that we construct another learning task of predicting soft labels (continuous values) obtained from privileged information and we perform transfer learning from this task to the target task of predicting hard labels. We derive a PAC-Bayesian bound of our proposed method, which justifies optimizing hyperparameters by the empirical Bayes method. We also experimentally show the usefulness of our proposed method compared with GPC and GPC+.
A Quantum-Inspired Ensemble Method and Quantum-Inspired Forest Regressors
Nov 22, 2017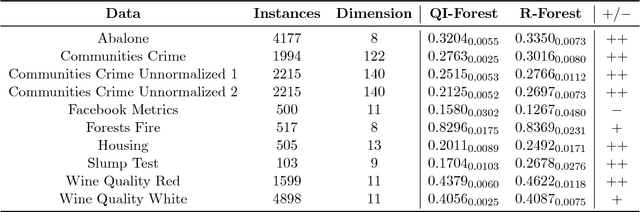
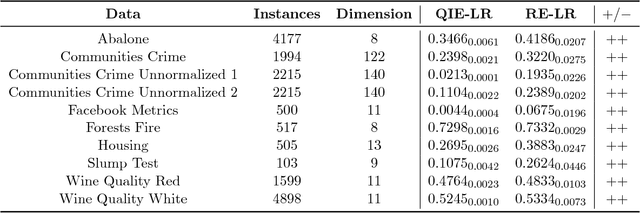
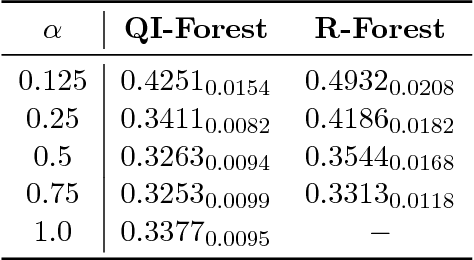
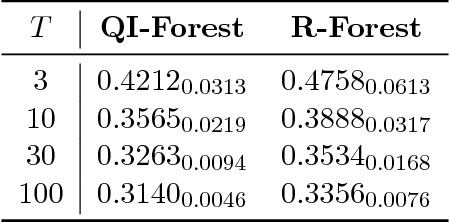
We propose a Quantum-Inspired Subspace(QIS) Ensemble Method for generating feature ensembles based on feature selections. We assign each principal component a Fraction Transition Probability as its probability weight based on Principal Component Analysis and quantum interpretations. In order to generate the feature subset for each base regressor, we select a feature subset from principal components based on Fraction Transition Probabilities. The idea originating from quantum mechanics can encourage ensemble diversity and the accuracy simultaneously. We incorporate Quantum-Inspired Subspace Method into Random Forest and propose Quantum-Inspired Forest. We theoretically prove that the quantum interpretation corresponds to the first order approximation of ensemble regression. We also evaluate the empirical performance of Quantum-Inspired Forest and Random Forest in multiple hyperparameter settings. Quantum-Inspired Forest proves the significant robustness of the default hyperparameters on most data sets. The contribution of this work is two-fold, a novel ensemble regression algorithm inspired by quantum mechanics and the theoretical connection between quantum interpretations and machine learning algorithms.
On the Model Shrinkage Effect of Gamma Process Edge Partition Models
Sep 26, 2017
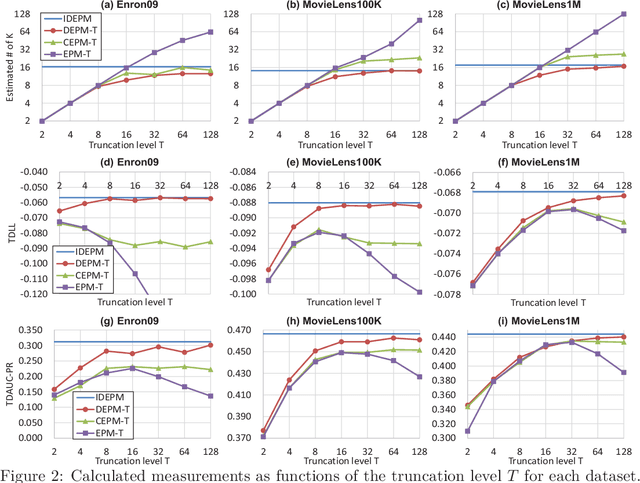
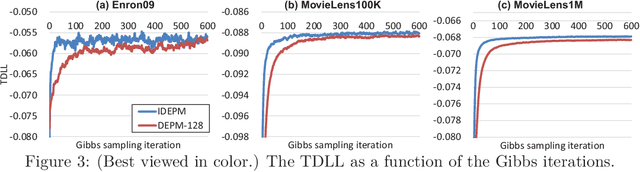
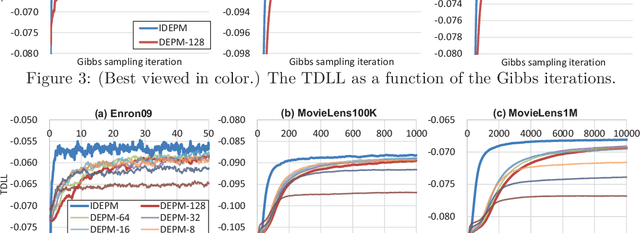
The edge partition model (EPM) is a fundamental Bayesian nonparametric model for extracting an overlapping structure from binary matrix. The EPM adopts a gamma process ($\Gamma$P) prior to automatically shrink the number of active atoms. However, we empirically found that the model shrinkage of the EPM does not typically work appropriately and leads to an overfitted solution. An analysis of the expectation of the EPM's intensity function suggested that the gamma priors for the EPM hyperparameters disturb the model shrinkage effect of the internal $\Gamma$P. In order to ensure that the model shrinkage effect of the EPM works in an appropriate manner, we proposed two novel generative constructions of the EPM: CEPM incorporating constrained gamma priors, and DEPM incorporating Dirichlet priors instead of the gamma priors. Furthermore, all DEPM's model parameters including the infinite atoms of the $\Gamma$P prior could be marginalized out, and thus it was possible to derive a truly infinite DEPM (IDEPM) that can be efficiently inferred using a collapsed Gibbs sampler. We experimentally confirmed that the model shrinkage of the proposed models works well and that the IDEPM indicated state-of-the-art performance in generalization ability, link prediction accuracy, mixing efficiency, and convergence speed.
Expectation Propagation for t-Exponential Family Using Q-Algebra
May 28, 2017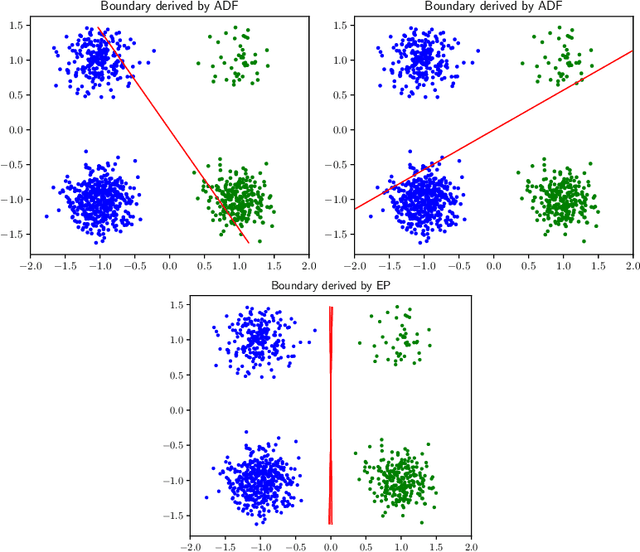
Exponential family distributions are highly useful in machine learning since their calculation can be performed efficiently through natural parameters. The exponential family has recently been extended to the t-exponential family, which contains Student-t distributions as family members and thus allows us to handle noisy data well. However, since the t-exponential family is denied by the deformed exponential, we cannot derive an efficient learning algorithm for the t-exponential family such as expectation propagation (EP). In this paper, we borrow the mathematical tools of q-algebra from statistical physics and show that the pseudo additivity of distributions allows us to perform calculation of t-exponential family distributions through natural parameters. We then develop an expectation propagation (EP) algorithm for the t-exponential family, which provides a deterministic approximation to the posterior or predictive distribution with simple moment matching. We finally apply the proposed EP algorithm to the Bayes point machine and Student-t process classication, and demonstrate their performance numerically.