 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-Down Bayesian Posterior Sampling for Sum-Product Networks
Jun 18, 2024Sum-product networks (SPNs) are probabilistic models characterized by exact and fast evaluation of fundamental probabilistic operations. Its superior computational tractability has led to applications in many fields, such as machine learning with time constraints or accuracy requirements and real-time systems. The structural constraints of SPNs supporting fast inference, however, lead to increased learning-time complexity and can be an obstacle to building highly expressive SPNs. This study aimed to develop a Bayesian learning approach that can be efficiently implemented on large-scale SPNs. We derived a new full conditional probability of Gibbs sampling by marginalizing multiple random variables to expeditiously obtain the posterior distribution. The complexity analysis revealed that our sampling algorithm works efficiently even for the largest possible SPN. Furthermore, we proposed a hyperparameter tuning method that balances the diversity of the prior distribution and optimization efficiency in large-scale SPNs. Our method has improved learning-time complexity and demonstrated computational speed tens to more than one hundred times faster and superior predictive performance in numerical experiments on more than 20 datasets.
Understanding Linear Probing then Fine-tuning Language Models from NTK Perspective
May 27, 2024



The two-stage fine-tuning (FT) method, linear probing then fine-tuning (LP-FT), consistently outperforms linear probing (LP) and FT alone in terms of accuracy for both in-distribution (ID) and out-of-distribution (OOD) data. This success is largely attributed to the preservation of pre-trained features, achieved through a near-optimal linear head obtained during LP. However, despite the widespread use of large language models, the exploration of complex architectures such as Transformers remains limited. In this paper, we analyze the training dynamics of LP-FT for classification models on the basis of the neural tangent kernel (NTK) theory. Our analysis decomposes the NTK matrix into two components, highlighting the importance of the linear head norm alongside the prediction accuracy at the start of the FT stage. We also observe a significant increase in the linear head norm during LP, stemming from training with the cross-entropy (CE) loss, which effectively minimizes feature changes. Furthermore, we find that this increased norm can adversely affect model calibration, a challenge that can be addressed by temperature scaling. Additionally, we extend our analysis with the NTK to the low-rank adaptation (LoRA) method and validate its effectiveness. Our experiments with a Transformer-based model on natural language processing tasks across multiple benchmarks confirm our theoretical analysis and demonstrate the effectiveness of LP-FT in fine-tuning language models. Code is available at https://github.com/tom4649/lp-ft_ntk.
End-to-End Training Induces Information Bottleneck through Layer-Role Differentiation: A Comparative Analysis with Layer-wise Training
Feb 14, 2024End-to-end (E2E) training, optimizing the entire model through error backpropagation, fundamentally supports the advancements of deep learning. Despite its high performance, E2E training faces the problems of memory consumption, parallel computing, and discrepancy with the functionalities of the actual brain. Various alternative methods have been proposed to overcome these difficulties; however, no one can yet match the performance of E2E training, thereby falling short in practicality. Furthermore, there is no deep understanding regarding differences in the trained model properties beyond the performance gap. In this paper, we reconsider why E2E training demonstrates a superior performance through a comparison with layer-wise training, a non-E2E method that locally sets errors. On the basis of the observation that E2E training has an advantage in propagating input information, we analyze the information plane dynamics of intermediate representations based on the Hilbert-Schmidt independence criterion (HSIC). The results of our normalized HSIC value analysis reveal the E2E training ability to exhibit different information dynamics across layers, in addition to efficient information propagation. Furthermore, we show that this layer-role differentiation leads to the final representation following the information bottleneck principle. It suggests the need to consider the cooperative interactions between layers, not just the final layer when analyzing the information bottleneck of deep learning.
Understanding Parameter Saliency via Extreme Value Theory
Oct 27, 2023Deep neural networks are being increasingly implemented throughout society in recent years. It is useful to identify which parameters trigger misclassification in diagnosing undesirable model behaviors. The concept of parameter saliency is proposed and used to diagnose convolutional neural networks (CNNs) by ranking convolution filters that may have caused misclassification on the basis of parameter saliency. It is also shown that fine-tuning the top ranking salient filters has efficiently corrected misidentification on ImageNet. However, there is still a knowledge gap in terms of understanding why parameter saliency ranking can find the filters inducing misidentification. In this work, we attempt to bridge the gap by analyzing parameter saliency ranking from a statistical viewpoint, namely, extreme value theory. We first show that the existing work implicitly assumes that the gradient norm computed for each filter follows a normal distribution. Then, we clarify the relationship between parameter saliency and the score based on the peaks-over-threshold (POT) method, which is often used to model extreme values. Finally, we reformulate parameter saliency in terms of the POT method, where this reformulation is regarded as statistical anomaly detection and does not require the implicit assumptions of the existing parameter-saliency formulation. Our experimental results demonstrate that our reformulation can detect malicious filters as well. Furthermore, we show that the existing parameter saliency method exhibits a bias against the depth of layers in deep neural networks. In particular, this bias has the potential to inhibit the discovery of filters that cause misidentification in situations where domain shift occurs. In contrast, parameter saliency based on POT shows less of this bias.
Initialization Bias of Fourier Neural Operator: Revisiting the Edge of Chaos
Oct 10, 2023This paper investigates the initialization bias of the Fourier neural operator (FNO). A mean-field theory for FNO is established, analyzing the behavior of the random FNO from an ``edge of chaos'' perspective. We uncover that the forward and backward propagation behaviors exhibit characteristics unique to FNO, induced by mode truncation, while also showcasing similarities to those of densely connected networks. Building upon this observation, we also propose a FNO version of the He initialization scheme to mitigate the negative initialization bias leading to training instability. Experimental results demonstrate the effectiveness of our initialization scheme, enabling stable training of a 32-layer FNO without the need for additional techniques or significant performance degradation.
Are Transformers with One Layer Self-Attention Using Low-Rank Weight Matrices Universal Approximators?
Jul 26, 2023Existing analyses of the expressive capacity of Transformer models have required excessively deep layers for data memorization, leading to a discrepancy with the Transformers actually used in practice. This is primarily due to the interpretation of the softmax function as an approximation of the hardmax function. By clarifying the connection between the softmax function and the Boltzmann operator, we prove that a single layer of self-attention with low-rank weight matrices possesses the capability to perfectly capture the context of an entire input sequence. As a consequence, we show that single-layer Transformer has a memorization capacity for finite samples, and that Transformers consisting of one self-attention layer with two feed-forward neural networks are universal approximators for continuous functions on a compact domain.
Exploring Weight Balancing on Long-Tailed Recognition Problem
May 29, 2023



Recognition problems in long-tailed data, where the sample size per class is heavily skewed, have recently gained importance because the distribution of the sample size per class in a dataset is generally exponential unless the sample size is intentionally adjusted. Various approaches have been devised to address these problems. Recently, weight balancing, which combines well-known classical regularization techniques with two-stage training, has been proposed. Despite its simplicity, it is known for its high performance against existing methods devised in various ways. However, there is a lack of understanding as to why this approach is effective for long-tailed data. In this study, we analyze the method focusing on neural collapse and cone effect at each training stage and find that it can be decomposed into the increase in Fisher's discriminant ratio of the feature extractor caused by weight decay and cross entropy loss and implicit logit adjustment caused by weight decay and class-balanced loss. Our analysis shows that the training method can be further simplified by reducing the number of training stages to one while increasing accuracy.
Excess risk analysis for epistemic uncertainty with application to variational inference
Jun 02, 2022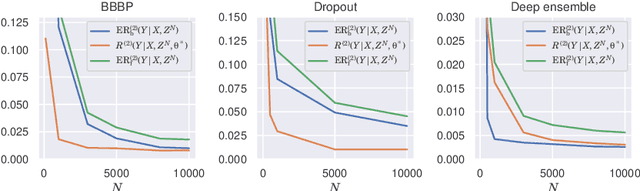
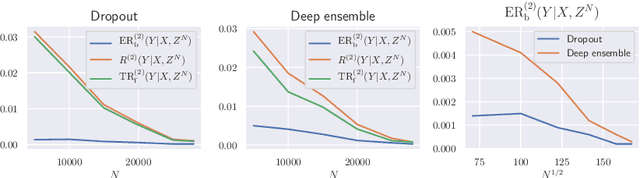
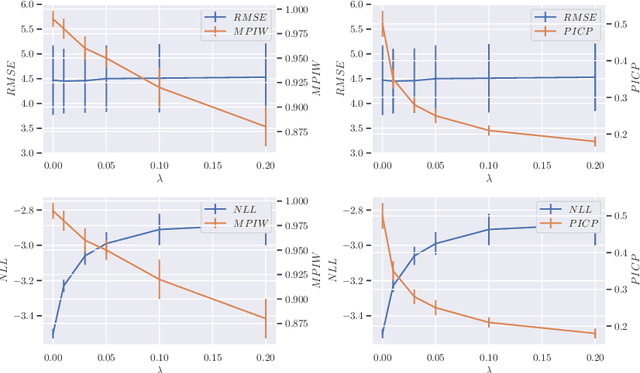
We analyze the epistemic uncertainty (EU) of supervised learning in Bayesian inference by focusing on the excess risk. Existing analysis is limited to the Bayesian setting, which assumes a correct model and exact Bayesian posterior distribution. Thus we cannot apply the existing theory to modern Bayesian algorithms, such as variational inference. To address this, we present a novel EU analysis in the frequentist setting, where data is generated from an unknown distribution. We show a relation between the generalization ability and the widely used EU measurements, such as the variance and entropy of the predictive distribution. Then we show their convergence behaviors theoretically. Finally, we propose new variational inference that directly controls the prediction and EU evaluation performances based on the PAC-Bayesian theory. Numerical experiments show that our algorithm significantly improves the EU evaluation over the existing methods.
Analyzing Lottery Ticket Hypothesis from PAC-Bayesian Theory Perspective
May 15, 2022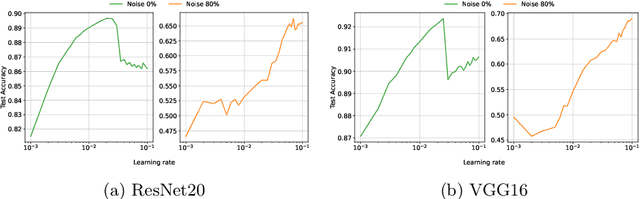
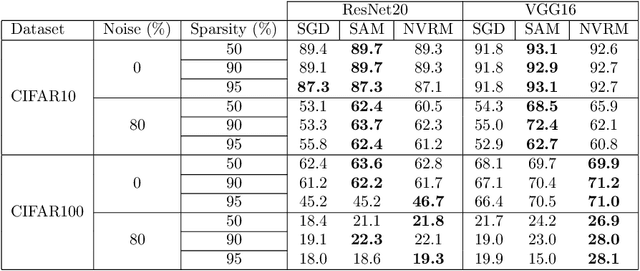
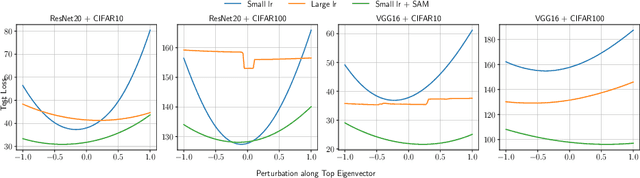

The lottery ticket hypothesis (LTH) has attracted attention because it can explain why over-parameterized models often show high generalization ability. It is known that when we use iterative magnitude pruning (IMP), which is an algorithm to find sparse networks with high generalization ability that can be trained from the initial weights independently, called winning tickets, the initial large learning rate does not work well in deep neural networks such as ResNet. However, since the initial large learning rate generally helps the optimizer to converge to flatter minima, we hypothesize that the winning tickets have relatively sharp minima, which is considered a disadvantage in terms of generalization ability. In this paper, we confirm this hypothesis and show that the PAC-Bayesian theory can provide an explicit understanding of the relationship between LTH and generalization behavior. On the basis of our experimental findings that flatness is useful for improving accuracy and robustness to label noise and that the distance from the initial weights is deeply involved in winning tickets, we offer the PAC-Bayes bound using a spike-and-slab distribution to analyze winning tickets. Finally, we revisit existing algorithms for finding winning tickets from a PAC-Bayesian perspective and provide new insights into these methods.
Goldilocks-curriculum Domain Randomization and Fractal Perlin Noise with Application to Sim2Real Pneumonia Lesion Detection
Apr 29, 2022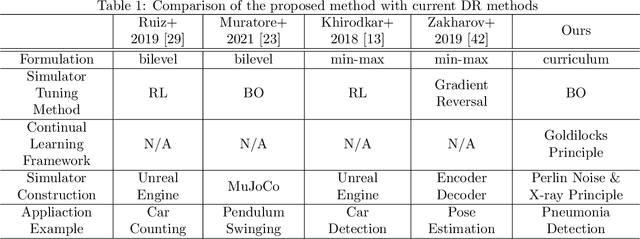
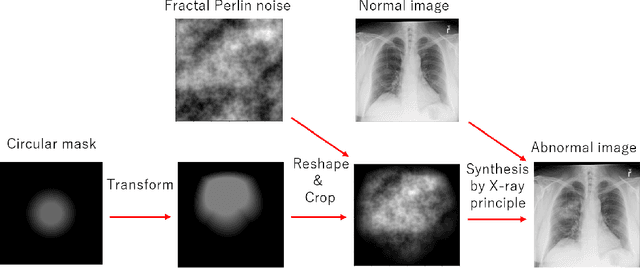
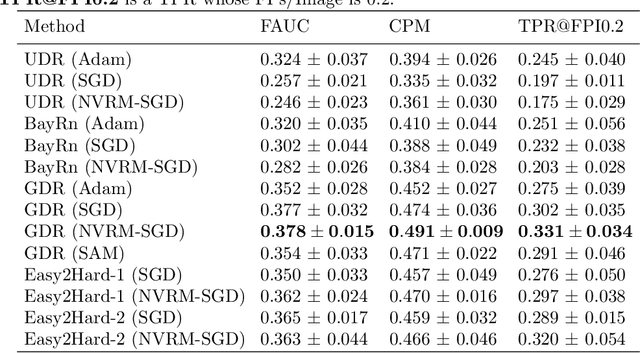
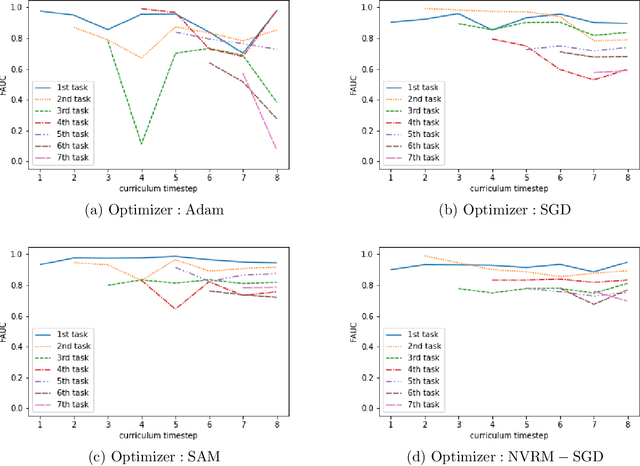
A computer-aided detection (CAD) system based on machine learning is expected to assist radiologists in making a diagnosis. It is desirable to build CAD systems for the various types of diseases accumulating daily in a hospital. An obstacle in developing a CAD system for a disease is that the number of medical images is typically too small to improve the performance of the machine learning model. In this paper, we aim to explore ways to address this problem through a sim2real transfer approach in medical image fields. To build a platform to evaluate the performance of sim2real transfer methods in the field of medical imaging, we construct a benchmark dataset that consists of $101$ chest X-images with difficult-to-identify pneumonia lesions judged by an experienced radiologist and a simulator based on fractal Perlin noise and the X-ray principle for generating pseudo pneumonia lesions. We then develop a novel domain randomization method, called Goldilocks-curriculum domain randomization (GDR) and evaluate our method in this platform.