 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Graphics Encoder for Real-Time Video Makeup Synthesis from Example
May 12, 2021

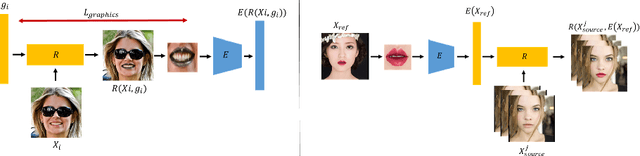
While makeup virtual-try-on is now widespread, parametrizing a computer graphics rendering engine for synthesizing images of a given cosmetics product remains a challenging task. In this paper, we introduce an inverse computer graphics method for automatic makeup synthesis from a reference image, by learning a model that maps an example portrait image with makeup to the space of rendering parameters. This method can be used by artists to automatically create realistic virtual cosmetics image samples, or by consumers, to virtually try-on a makeup extracted from their favorite reference image.
Approximation of dilation-based spatial relations to add structural constraints in neural networks
Feb 22, 2021


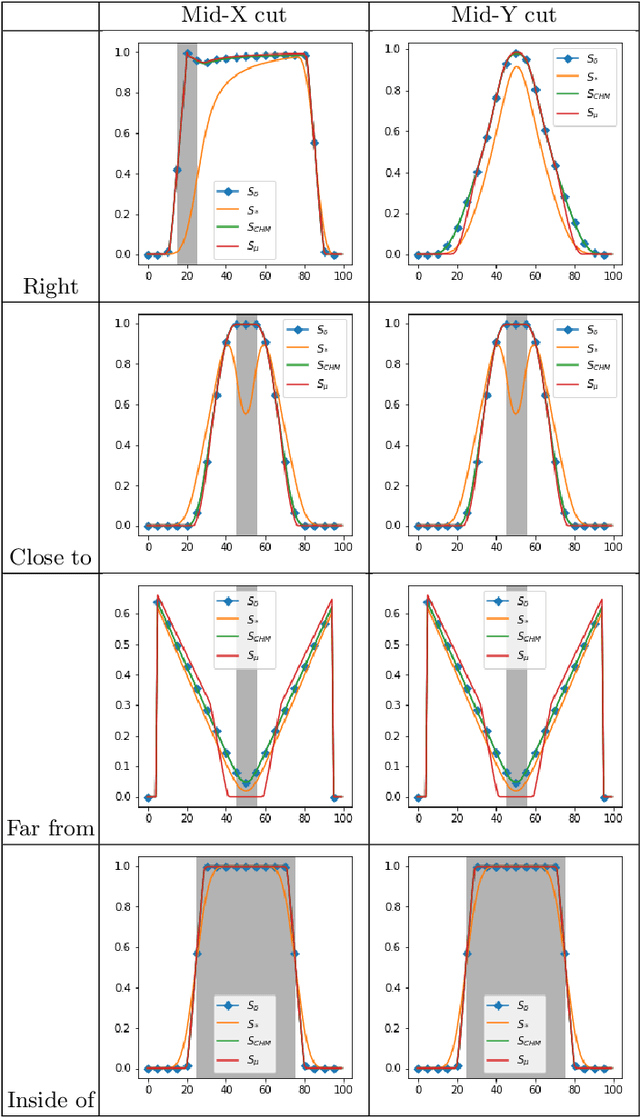
Spatial relations between objects in an image have proved useful for structural object recognition. Structural constraints can act as regularization in neural network training, improving generalization capability with small datasets. Several relations can be modeled as a morphological dilation of a reference object with a structuring element representing the semantics of the relation, from which the degree of satisfaction of the relation between another object and the reference object can be derived. However, dilation is not differentiable, requiring an approximation to be used in the context of gradient-descent training of a network. We propose to approximate dilations using convolutions based on a kernel equal to the structuring element. We show that the proposed approximation, even if slightly less accurate than previous approximations, is definitely faster to compute and therefore more suitable for computationally intensive neural network applications.
Comparing Deep Learning strategies for paired but unregistered multimodal segmentation of the liver in T1 and T2-weighted MRI
Jan 18, 2021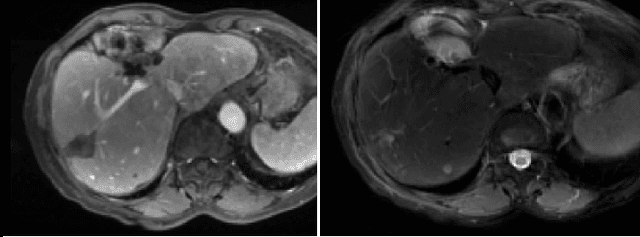

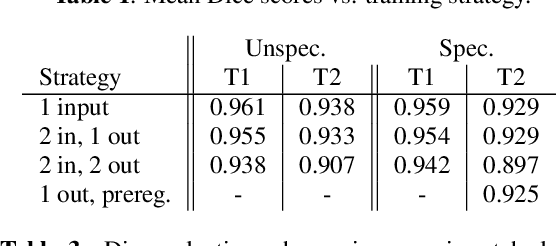
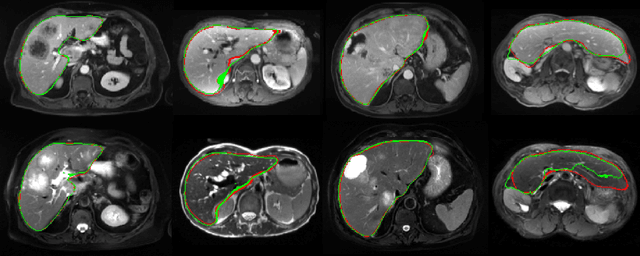
We address the problem of multimodal liver segmentation in paired but unregistered T1 and T2-weighted MR images. We compare several strategies described in the literature, with or without multi-task training, with or without pre-registration. We also compare different loss functions (cross-entropy, Dice loss, and three adversarial losses). All methods achieved comparable performances with the exception of a multi-task setting that performs both segmentations at once, which performed poorly.
Encoding the latent posterior of Bayesian Neural Networks for uncertainty quantification
Dec 04, 2020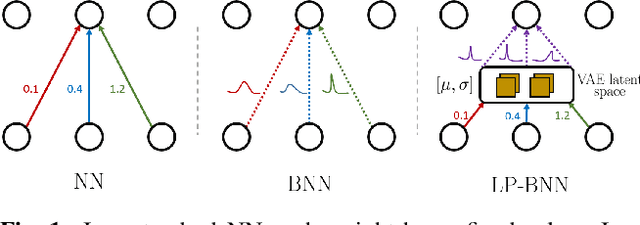
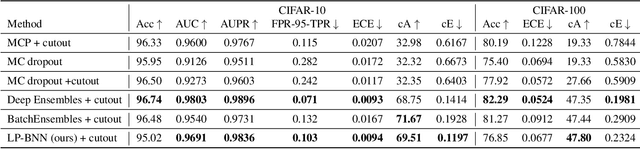
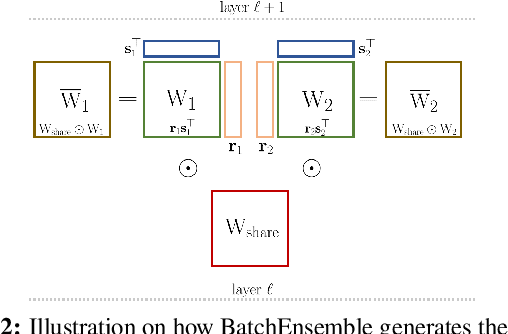
Bayesian neural networks (BNNs) have been long considered an ideal, yet unscalable solution for improving the robustness and the predictive uncertainty of deep neural networks. While they could capture more accurately the posterior distribution of the network parameters, most BNN approaches are either limited to small networks or rely on constraining assumptions such as parameter independence. These drawbacks have enabled prominence of simple, but computationally heavy approaches such as Deep Ensembles, whose training and testing costs increase linearly with the number of networks. In this work we aim for efficient deep BNNs amenable to complex computer vision architectures, e.g. ResNet50 DeepLabV3+, and tasks, e.g. semantic segmentation, with fewer assumptions on the parameters. We achieve this by leveraging variational autoencoders (VAEs) to learn the interaction and the latent distribution of the parameters at each network layer. Our approach, Latent-Posterior BNN (LP-BNN), is compatible with the recent BatchEnsemble method, leading to highly efficient ({in terms of computation and} memory during both training and testing) ensembles. LP-BNN s attain competitive results across multiple metrics in several challenging benchmarks for image classification, semantic segmentation and out-of-distribution detection.
Improving Interpretability for Computer-aided Diagnosis tools on Whole Slide Imaging with Multiple Instance Learning and Gradient-based Explanations
Sep 29, 2020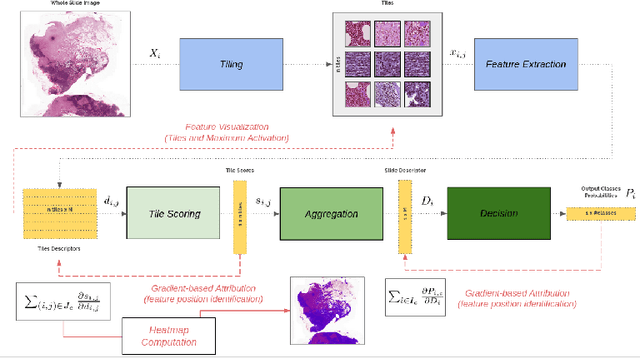

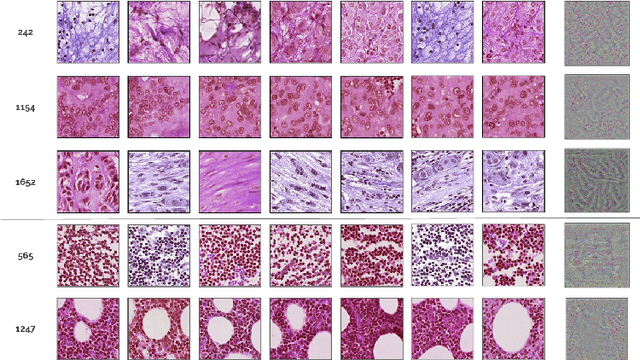
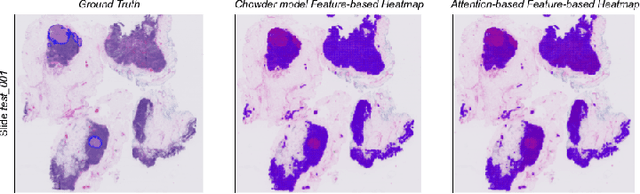
Deep learning methods are widely used for medical applications to assist medical doctors in their daily routines. While performances reach expert's level, interpretability (highlight how and what a trained model learned and why it makes a specific decision) is the next important challenge that deep learning methods need to answer to be fully integrated in the medical field. In this paper, we address the question of interpretability in the context of whole slide images (WSI) classification. We formalize the design of WSI classification architectures and propose a piece-wise interpretability approach, relying on gradient-based methods, feature visualization and multiple instance learning context. We aim at explaining how the decision is made based on tile level scoring, how these tile scores are decided and which features are used and relevant for the task. After training two WSI classification architectures on Camelyon-16 WSI dataset, highlighting discriminative features learned, and validating our approach with pathologists, we propose a novel manner of computing interpretability slide-level heat-maps, based on the extracted features, that improves tile-level classification performances by more than 29% for AUC.
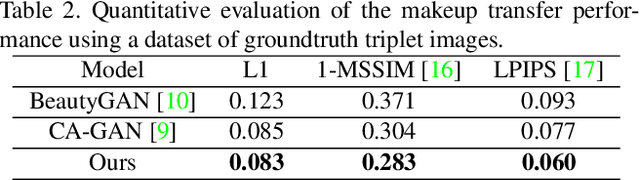
CA-GAN: Weakly Supervised Color Aware GAN for Controllable Makeup Transfer
Aug 24, 2020



While existing makeup style transfer models perform an image synthesis whose results cannot be explicitly controlled, the ability to modify makeup color continuously is a desirable property for virtual try-on applications. We propose a new formulation for the makeup style transfer task, with the objective to learn a color controllable makeup style synthesis. We introduce CA-GAN, a generative model that learns to modify the color of specific objects (e.g. lips or eyes) in the image to an arbitrary target color while preserving background. Since color labels are rare and costly to acquire, our method leverages weakly supervised learning for conditional GANs. This enables to learn a controllable synthesis of complex objects, and only requires a weak proxy of the image attribute that we desire to modify. Finally, we present for the first time a quantitative analysis of makeup style transfer and color control performance.
One Versus all for deep Neural Network Incertitude quantification
Jun 01, 2020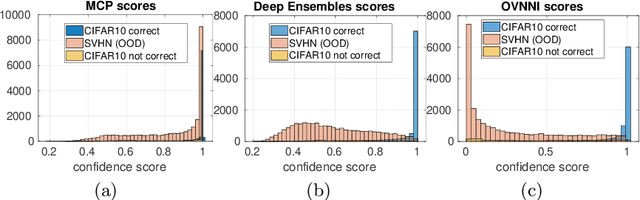
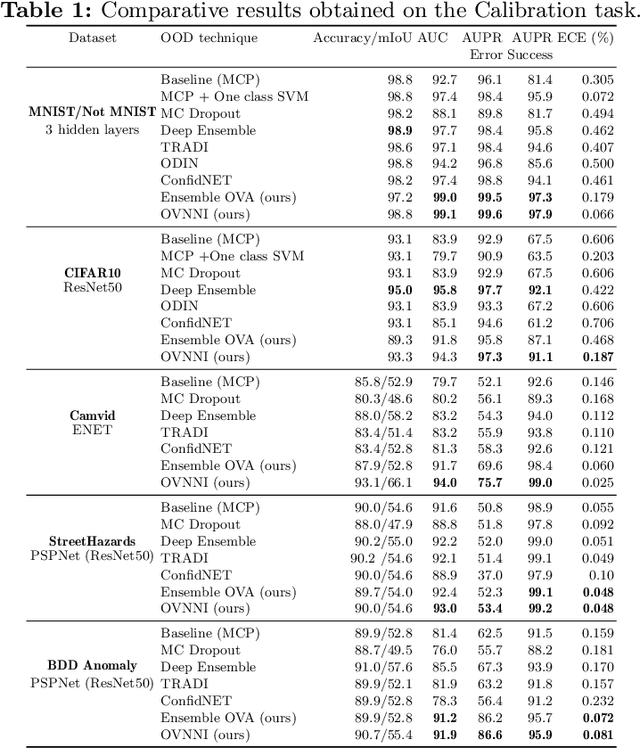
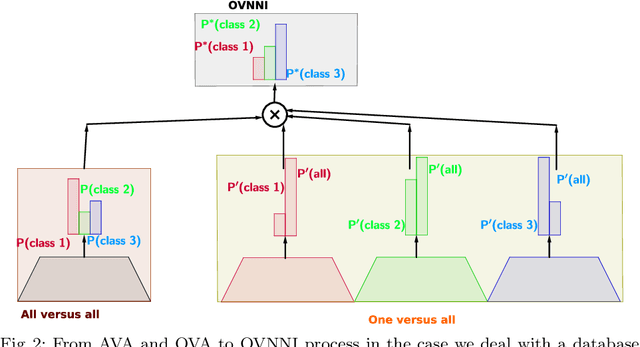
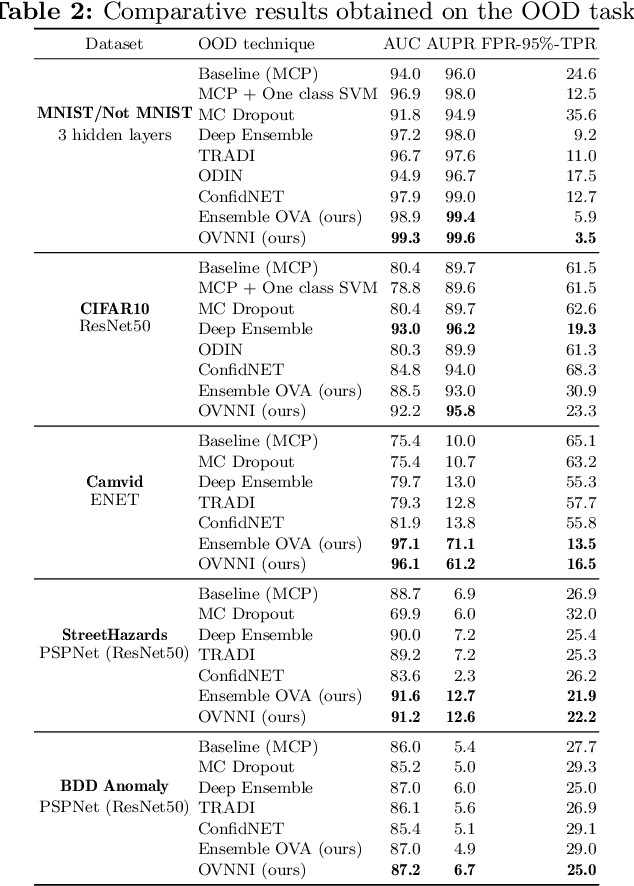
Deep neural networks (DNNs) are powerful learning models yet their results are not always reliable. This is due to the fact that modern DNNs are usually uncalibrated and we cannot characterize their epistemic uncertainty. In this work, we propose a new technique to quantify the epistemic uncertainty of data easily. This method consists in mixing the predictions of an ensemble of DNNs trained to classify One class vs All the other classes (OVA) with predictions from a standard DNN trained to perform All vs All (AVA) classification. On the one hand, the adjustment provided by the AVA DNN to the score of the base classifiers allows for a more fine-grained inter-class separation. On the other hand, the two types of classifiers enforce mutually their detection of out-of-distribution (OOD) samples, circumventing entirely the requirement of using such samples during training. Our method achieves state of the art performance in quantifying OOD data across multiple datasets and architectures while requiring little hyper-parameter tuning.
Investigating Image Applications Based on Spatial-Frequency Transform and Deep Learning Techniques
Mar 20, 2020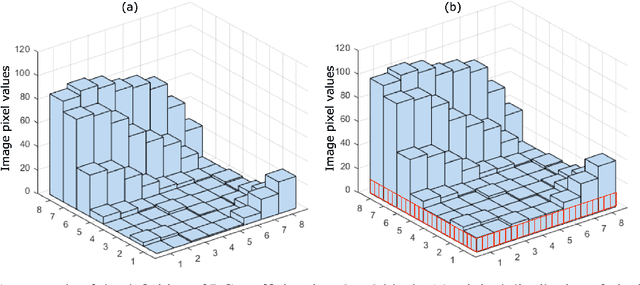

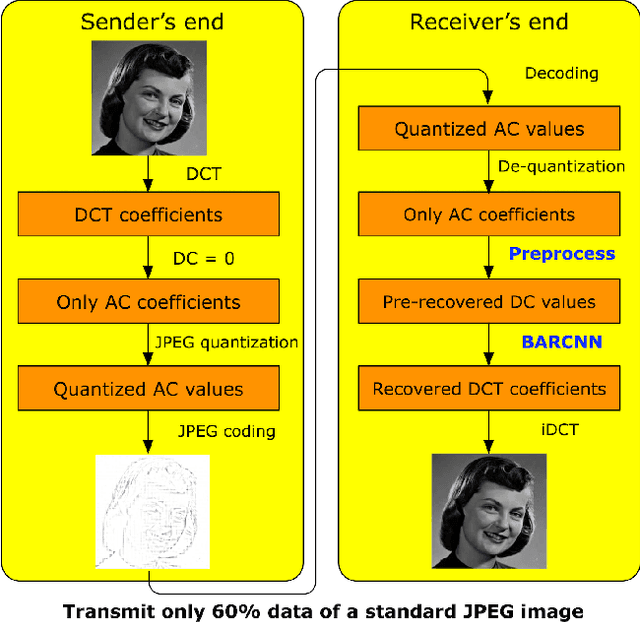

This is the report for the PRIM project in Telecom Paris. This report is about applications based on spatial-frequency transform and deep learning techniques. In this report, there are two main works. The first work is about the enhanced JPEG compression method based on deep learning. we propose a novel method to highly enhance the JPEG compression by transmitting fewer image data at the sender's end. At the receiver's end, we propose a DC recovery algorithm together with the deep residual learning framework to recover images with high quality. The second work is about adversarial examples defenses based on signal processing. We propose the wavelet extension method to extend image data features, which makes it more difficult to generate adversarial examples. We further adopt wavelet denoising to reduce the influence of the adversarial perturbations. With intensive experiments, we demonstrate that both works are effective in their application scenarios.
TRADI: Tracking deep neural network weight distributions
Dec 26, 2019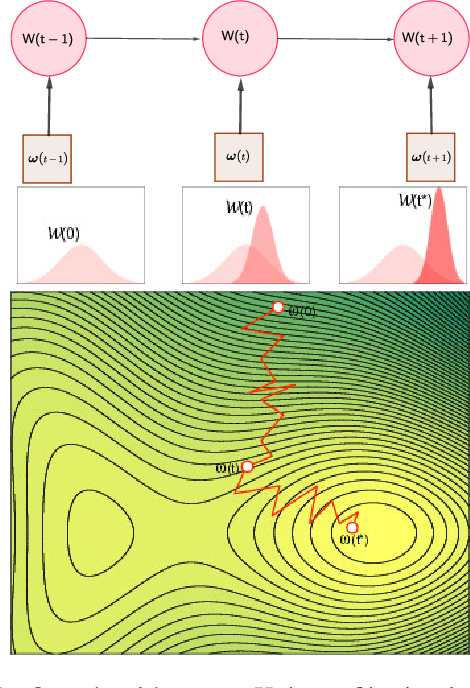
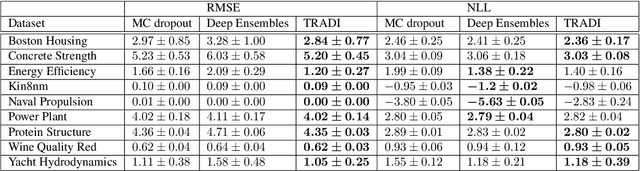
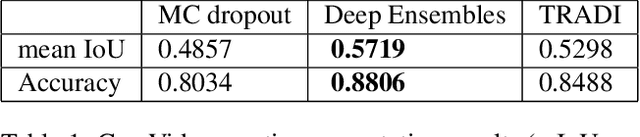
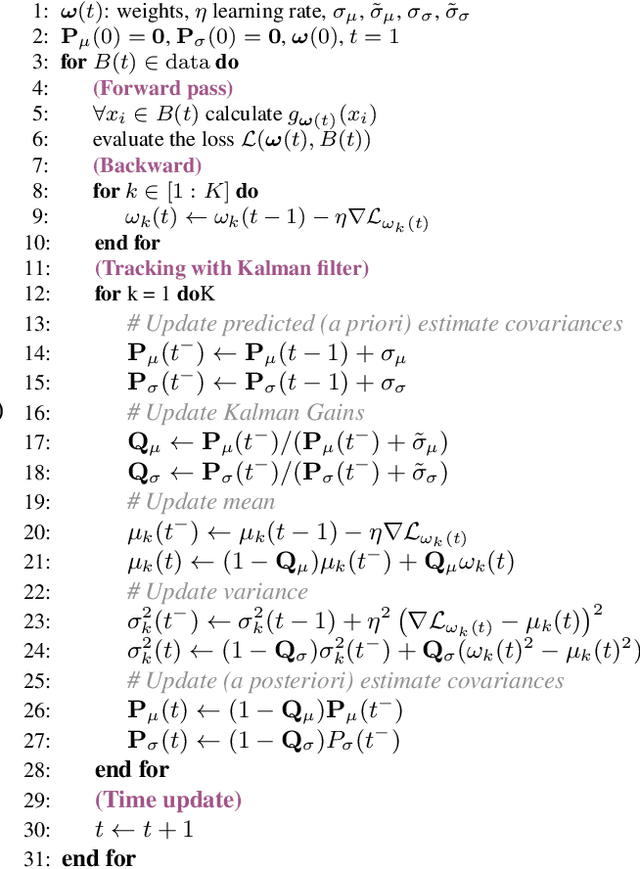
During training, the weights of a Deep Neural Network (DNN) are optimized from a random initialization towards a nearly optimum value minimizing a loss function. Only this final state of the weights is typically kept for testing, while the wealth of information on the geometry of the weight space, accumulated over the descent towards the minimum is discarded. In this work we propose to make use of this knowledge and leverage it for computing the distributions of the weights of the DNN. This can be further used for estimating the epistemic uncertainty of the DNN by sampling an ensemble of networks from these distributions. To this end we introduce a method for tracking the trajectory of the weights during optimization, that does not require any changes in the architecture nor on the training procedure. We evaluate our method on standard classification and regression benchmarks, and on out-of-distribution detection for classification and semantic segmentation. We achieve competitive results, while preserving computational efficiency in comparison to other popular approaches.
Max-plus Operators Applied to Filter Selection and Model Pruning in Neural Networks
Apr 08, 2019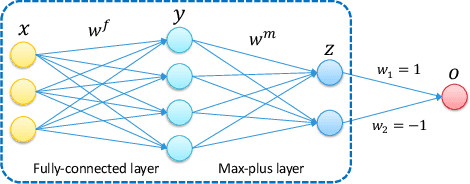
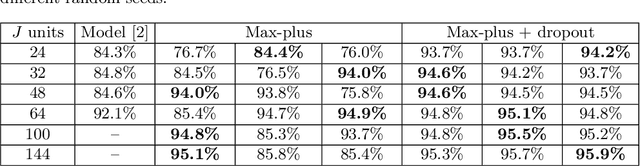
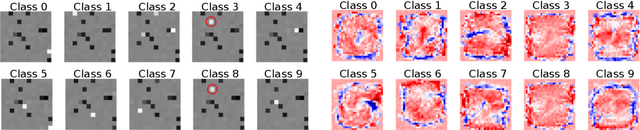
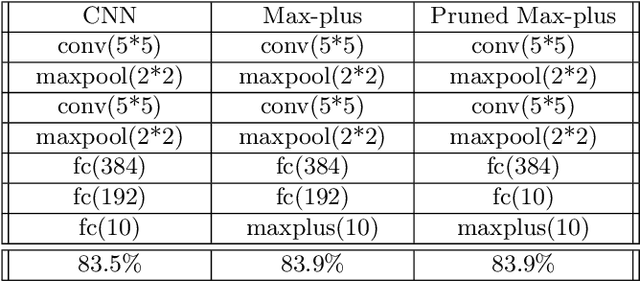
Following recent advances in morphological neural networks, we propose to study in more depth how Max-plus operators can be exploited to define morphological units and how they behave when incorporated in layers of conventional neural networks. Besides showing that they can be easily implemented with modern machine learning frameworks , we confirm and extend the observation that a Max-plus layer can be used to select important filters and reduce redundancy in its previous layer, without incurring performance loss. Experimental results demonstrate that the filter selection strategy enabled by a Max-plus is highly efficient and robust, through which we successfully performed model pruning on different neural network architectures. We also point out that there is a close connection between Maxout networks and our pruned Max-plus networks by comparing their respective characteristics. The code for reproducing our experiments is available online.