 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Relevance Ranking Using Enhanced Document-Query Interactions
Sep 11, 2018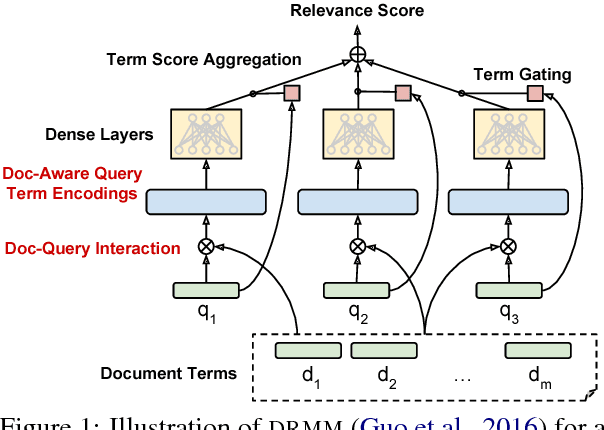
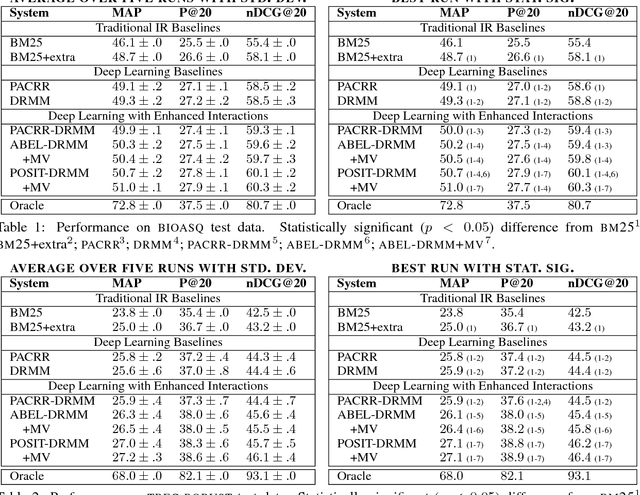
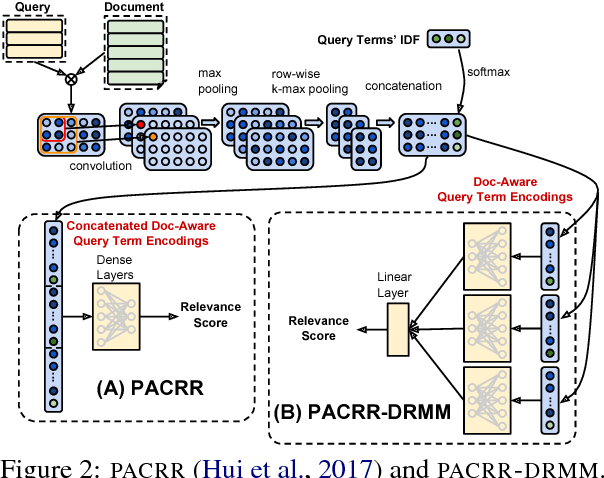
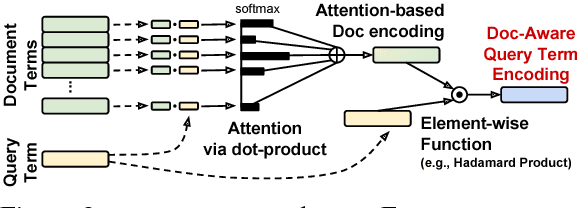
We explore several new models for document relevance ranking, building upon the Deep Relevance Matching Model (DRMM) of Guo et al. (2016). Unlike DRMM, which uses context-insensitive encodings of terms and query-document term interactions, we inject rich context-sensitive encodings throughout our models, inspired by PACRR's (Hui et al., 2017) convolutional n-gram matching features, but extended in several ways including multiple views of query and document inputs. We test our models on datasets from the BIOASQ question answering challenge (Tsatsaronis et al., 2015) and TREC ROBUST 2004 (Voorhees, 2005), showing they outperform BM25-based baselines, DRMM, and PACRR.
Obligation and Prohibition Extraction Using Hierarchical RNNs
May 10, 2018

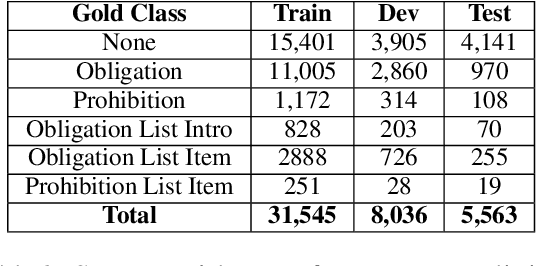
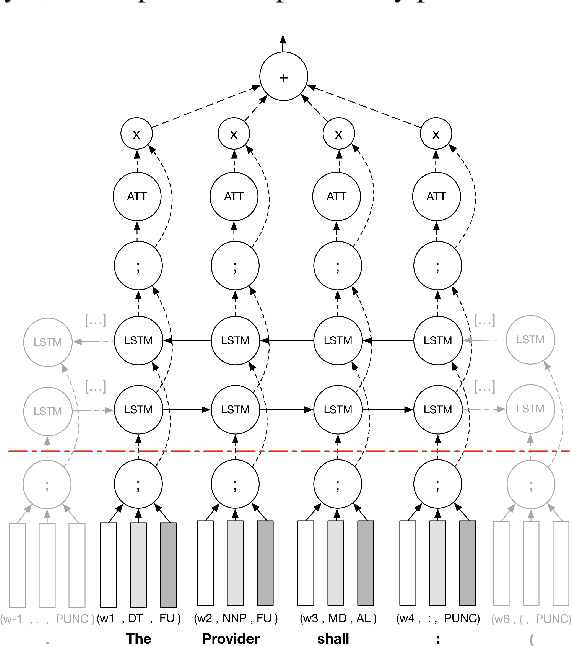
We consider the task of detecting contractual obligations and prohibitions. We show that a self-attention mechanism improves the performance of a BILSTM classifier, the previous state of the art for this task, by allowing it to focus on indicative tokens. We also introduce a hierarchical BILSTM, which converts each sentence to an embedding, and processes the sentence embeddings to classify each sentence. Apart from being faster to train, the hierarchical BILSTM outperforms the flat one, even when the latter considers surrounding sentences, because the hierarchical model has a broader discourse view.
Improved Abusive Comment Moderation with User Embeddings
Aug 11, 2017
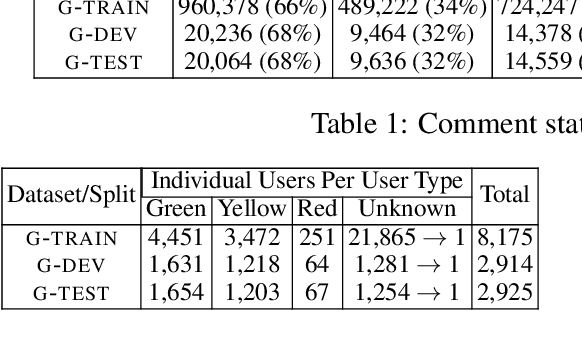
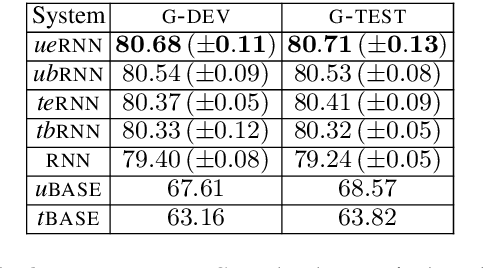
Experimenting with a dataset of approximately 1.6M user comments from a Greek news sports portal, we explore how a state of the art RNN-based moderation method can be improved by adding user embeddings, user type embeddings, user biases, or user type biases. We observe improvements in all cases, with user embeddings leading to the biggest performance gains.
Deep Learning for User Comment Moderation
Jul 17, 2017
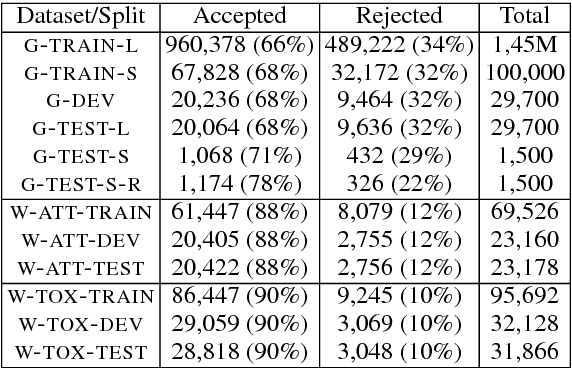
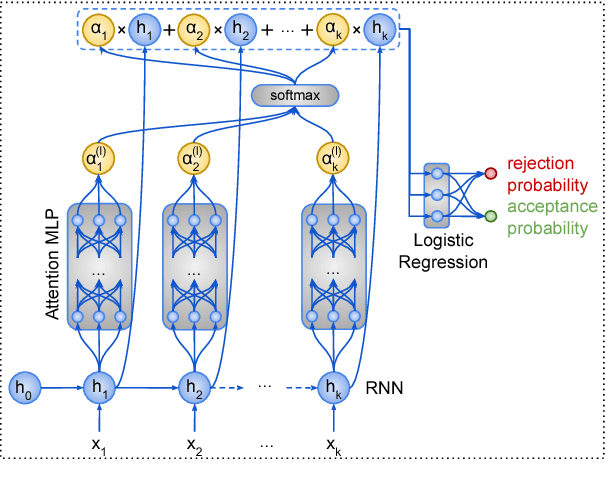
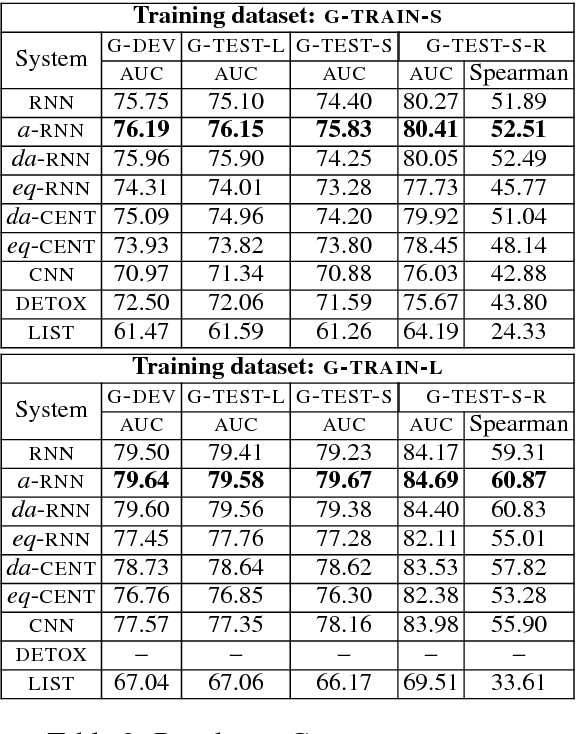
Experimenting with a new dataset of 1.6M user comments from a Greek news portal and existing datasets of English Wikipedia comments, we show that an RNN outperforms the previous state of the art in moderation. A deep, classification-specific attention mechanism improves further the overall performance of the RNN. We also compare against a CNN and a word-list baseline, considering both fully automatic and semi-automatic moderation.
Probabilistic Cascading for Large Scale Hierarchical Classification
May 09, 2015
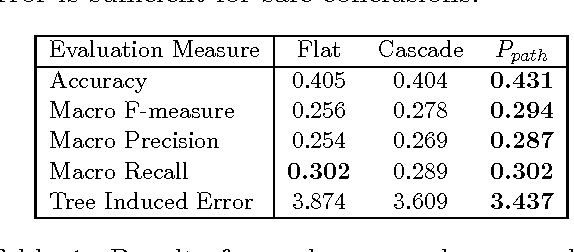
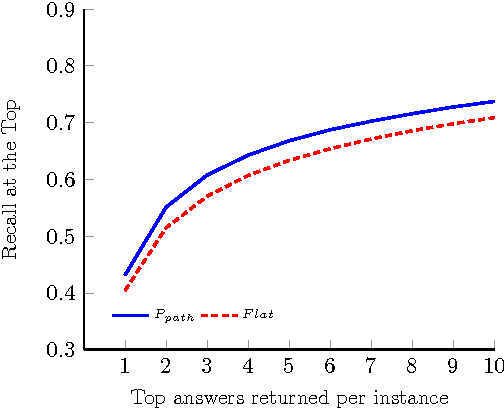
Hierarchies are frequently used for the organization of objects. Given a hierarchy of classes, two main approaches are used, to automatically classify new instances: flat classification and cascade classification. Flat classification ignores the hierarchy, while cascade classification greedily traverses the hierarchy from the root to the predicted leaf. In this paper we propose a new approach, which extends cascade classification to predict the right leaf by estimating the probability of each root-to-leaf path. We provide experimental results which indicate that, using the same classification algorithm, one can achieve better results with our approach, compared to the traditional flat and cascade classifications.
LSHTC: A Benchmark for Large-Scale Text Classification
Mar 30, 2015
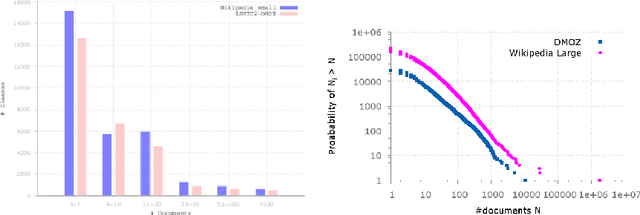
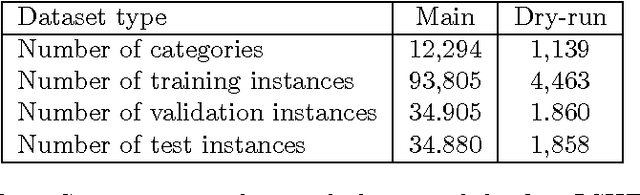
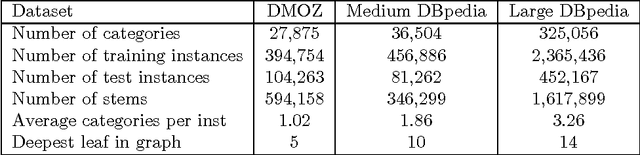
LSHTC is a series of challenges which aims to assess the performance of classification systems in large-scale classification in a a large number of classes (up to hundreds of thousands). This paper describes the dataset that have been released along the LSHTC series. The paper details the construction of the datsets and the design of the tracks as well as the evaluation measures that we implemented and a quick overview of the results. All of these datasets are available online and runs may still be submitted on the online server of the challenges.
Generating Natural Language Descriptions from OWL Ontologies: the NaturalOWL System
Apr 24, 2014
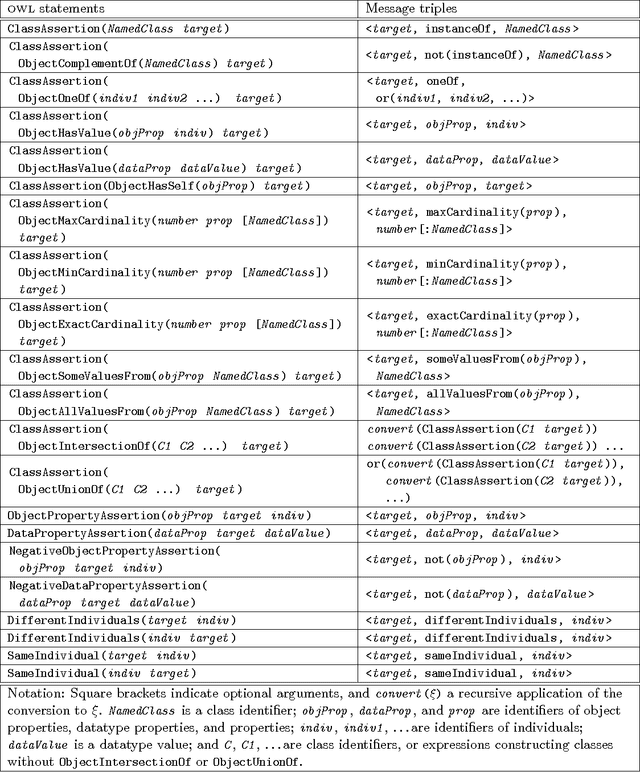
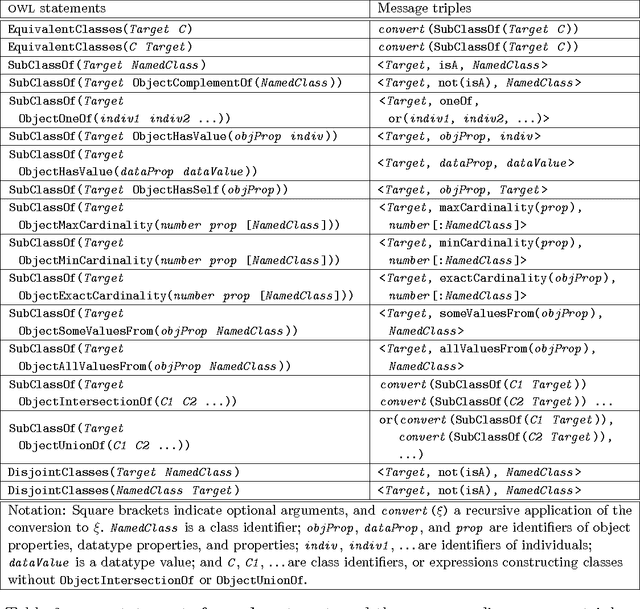
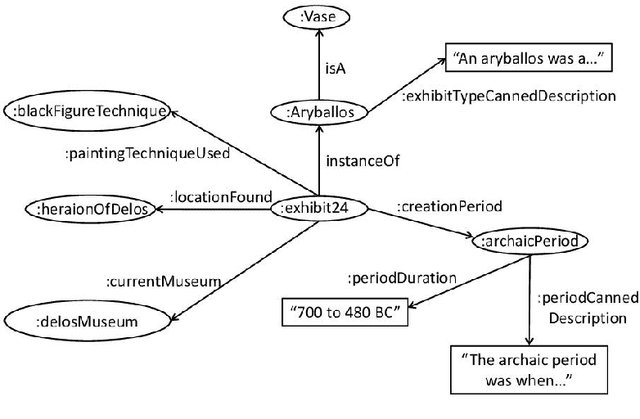
We present NaturalOWL, a natural language generation system that produces texts describing individuals or classes of OWL ontologies. Unlike simpler OWL verbalizers, which typically express a single axiom at a time in controlled, often not entirely fluent natural language primarily for the benefit of domain experts, we aim to generate fluent and coherent multi-sentence texts for end-users. With a system like NaturalOWL, one can publish information in OWL on the Web, along with automatically produced corresponding texts in multiple languages, making the information accessible not only to computer programs and domain experts, but also end-users. We discuss the processing stages of NaturalOWL, the optional domain-dependent linguistic resources that the system can use at each stage, and why they are useful. We also present trials showing that when the domain-dependent llinguistic resources are available, NaturalOWL produces significantly better texts compared to a simpler verbalizer, and that the resources can be created with relatively light effort.
Evaluation Measures for Hierarchical Classification: a unified view and novel approaches
Jul 01, 2013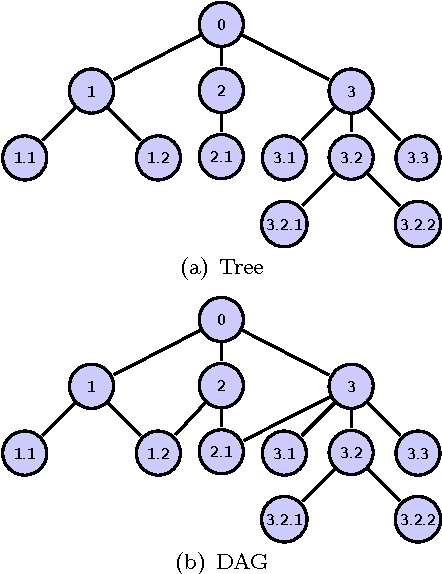

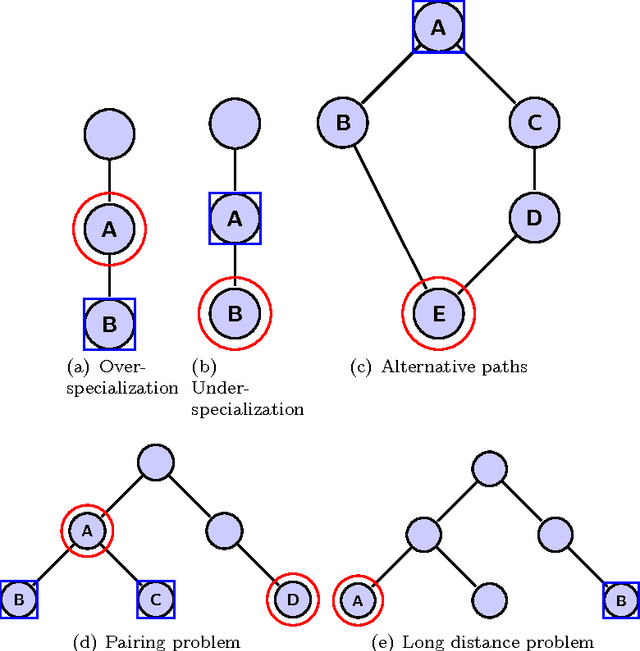
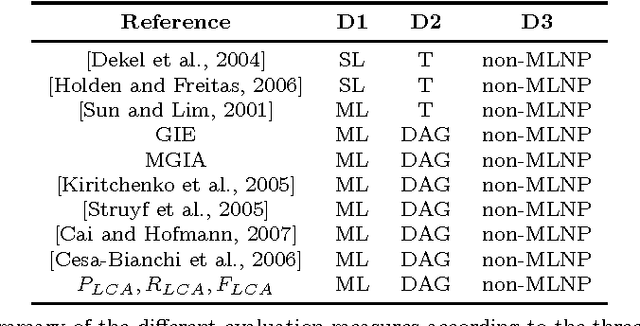
Hierarchical classification addresses the problem of classifying items into a hierarchy of classes. An important issue in hierarchical classification is the evaluation of different classification algorithms, which is complicated by the hierarchical relations among the classes. Several evaluation measures have been proposed for hierarchical classification using the hierarchy in different ways. This paper studies the problem of evaluation in hierarchical classification by analyzing and abstracting the key components of the existing performance measures. It also proposes two alternative generic views of hierarchical evaluation and introduces two corresponding novel measures. The proposed measures, along with the state-of-the art ones, are empirically tested on three large datasets from the domain of text classification. The empirical results illustrate the undesirable behavior of existing approaches and how the proposed methods overcome most of these methods across a range of cases.
A Survey of Paraphrasing and Textual Entailment Methods
May 30, 2010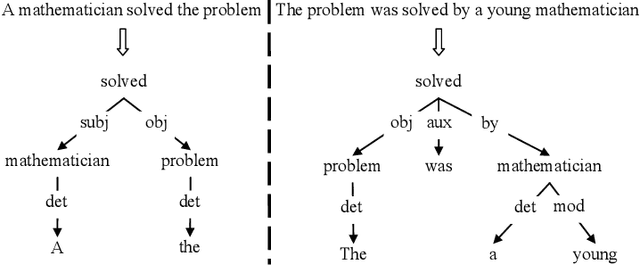
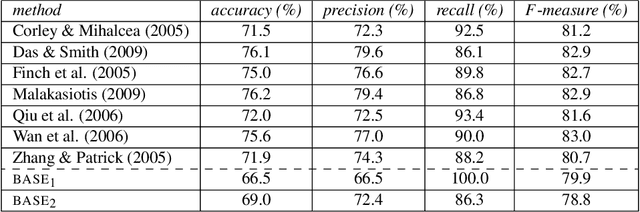
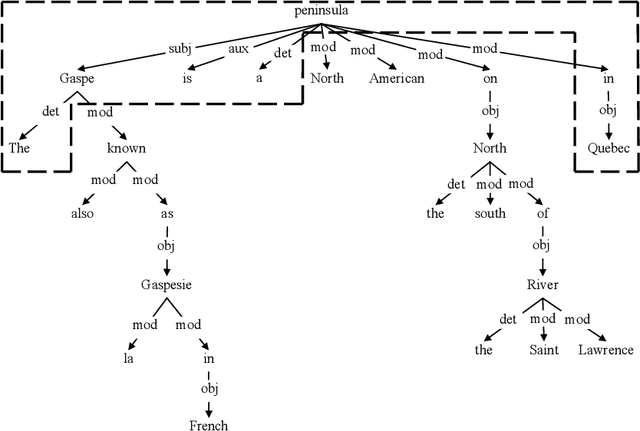
Paraphrasing methods recognize, generate, or extract phrases, sentences, or longer natural language expressions that convey almost the same information. Textual entailment methods, on the other hand, recognize, generate, or extract pairs of natural language expressions, such that a human who reads (and trusts) the first element of a pair would most likely infer that the other element is also true. Paraphrasing can be seen as bidirectional textual entailment and methods from the two areas are often similar. Both kinds of methods are useful, at least in principle, in a wide range of natural language processing applications, including question answering, summarization, text generation, and machine translation. We summarize key ideas from the two areas by considering in turn recognition, generation, and extraction methods, also pointing to prominent articles and resources.
* Technical Report, Natural Language Processing Group, Department of Informatics, Athens University of Economics and Business, Greece, 2010
Learning to Order Facts for Discourse Planning in Natural Language Generation
Jun 13, 2003
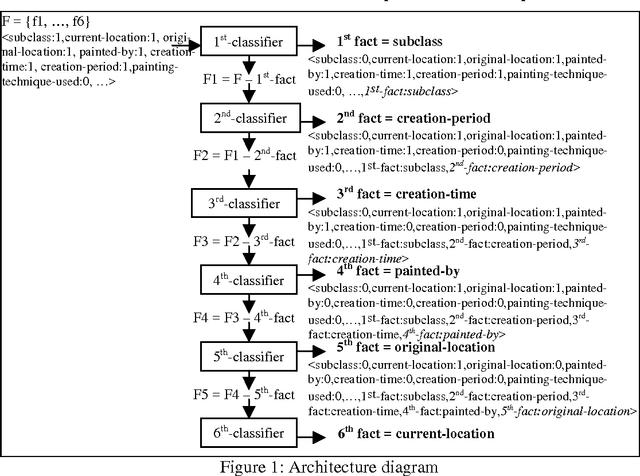
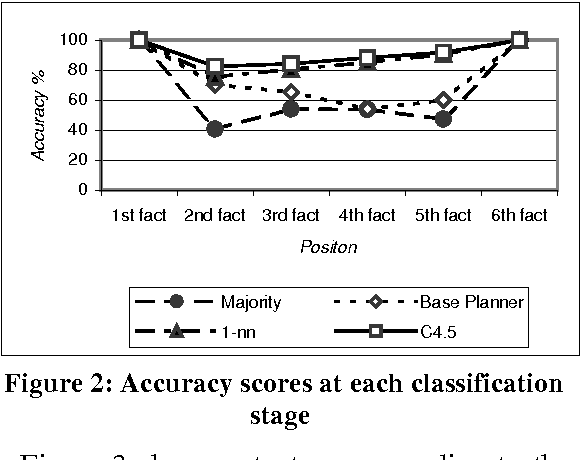
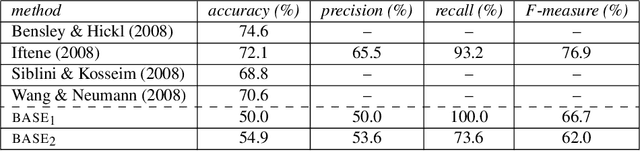
This paper presents a machine learning approach to discourse planning in natural language generation. More specifically, we address the problem of learning the most natural ordering of facts in discourse plans for a specific domain. We discuss our methodology and how it was instantiated using two different machine learning algorithms. A quantitative evaluation performed in the domain of museum exhibit descriptions indicates that our approach performs significantly better than manually constructed ordering rules. Being retrainable, the resulting planners can be ported easily to other similar domains, without requiring language technology expertise.
* 8 pages, 4 figures, 1 table