 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Order Facts for Discourse Planning in Natural Language Generation
Jun 13, 2003
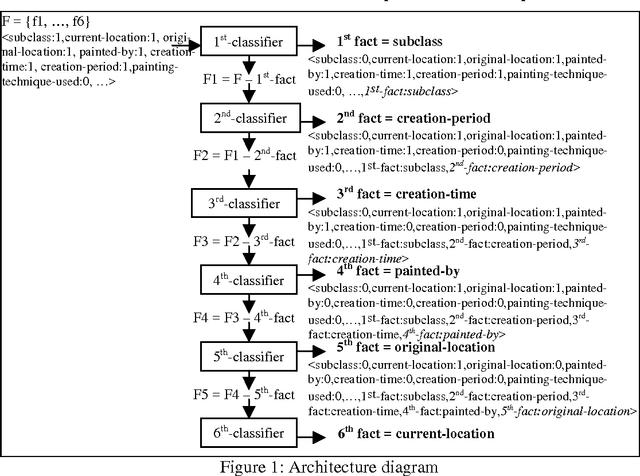
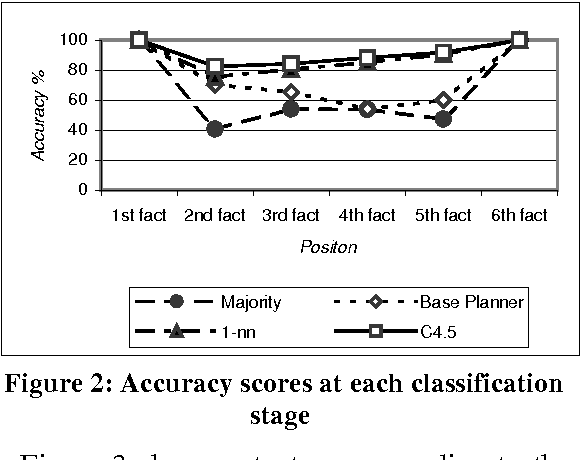
This paper presents a machine learning approach to discourse planning in natural language generation. More specifically, we address the problem of learning the most natural ordering of facts in discourse plans for a specific domain. We discuss our methodology and how it was instantiated using two different machine learning algorithms. A quantitative evaluation performed in the domain of museum exhibit descriptions indicates that our approach performs significantly better than manually constructed ordering rules. Being retrainable, the resulting planners can be ported easily to other similar domains, without requiring language technology expertise.
* 8 pages, 4 figures, 1 table
Generating Multilingual Personalized Descriptions of Museum Exhibits - The M-PIRO Project
Oct 29, 2001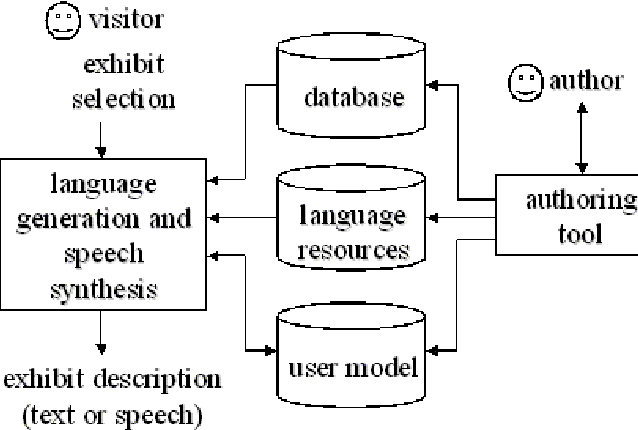
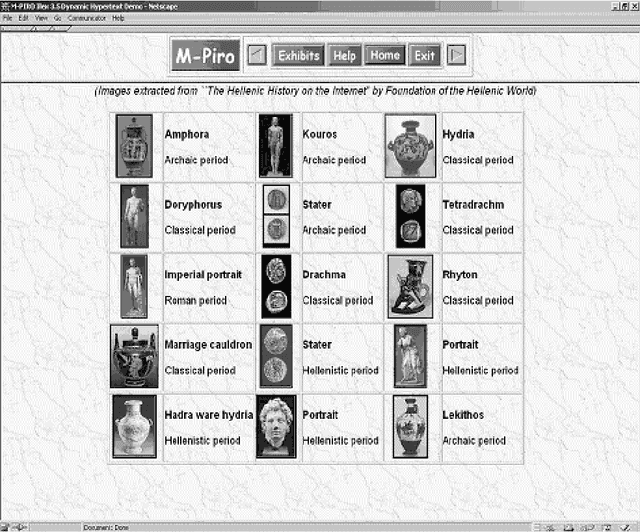
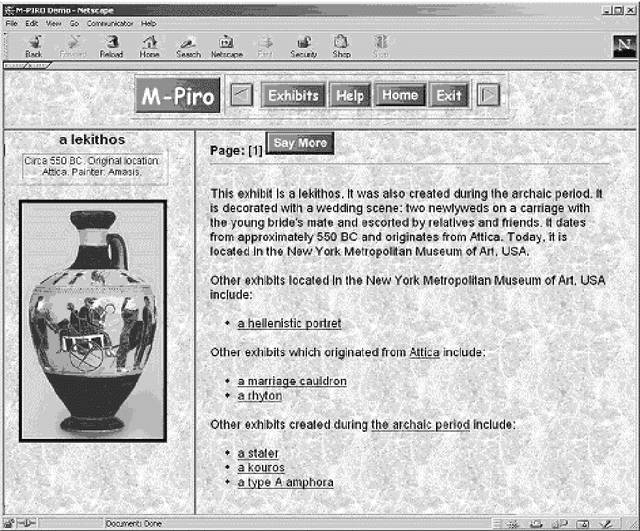
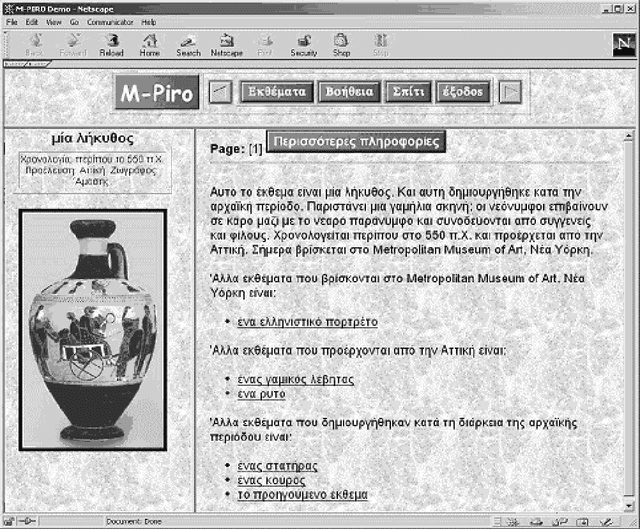
This paper provides an overall presentation of the M-PIRO project. M-PIRO is developing technology that will allow museums to generate automatically textual or spoken descriptions of exhibits for collections available over the Web or in virtual reality environments. The descriptions are generated in several languages from information in a language-independent database and small fragments of text, and they can be tailored according to the backgrounds of the users, their ages, and their previous interaction with the system. An authoring tool allows museum curators to update the system's database and to control the language and content of the resulting descriptions. Although the project is still in progress, a Web-based demonstrator that supports English, Greek and Italian is already available, and it is used throughout the paper to highlight the capabilities of the emerging technology.