 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParagraph-level Rationale Extraction through Regularization: A case study on European Court of Human Rights Cases
Mar 24, 2021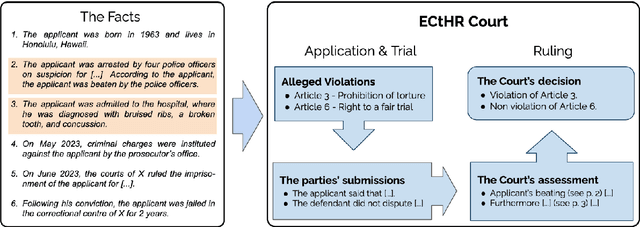
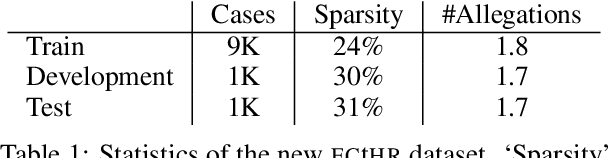
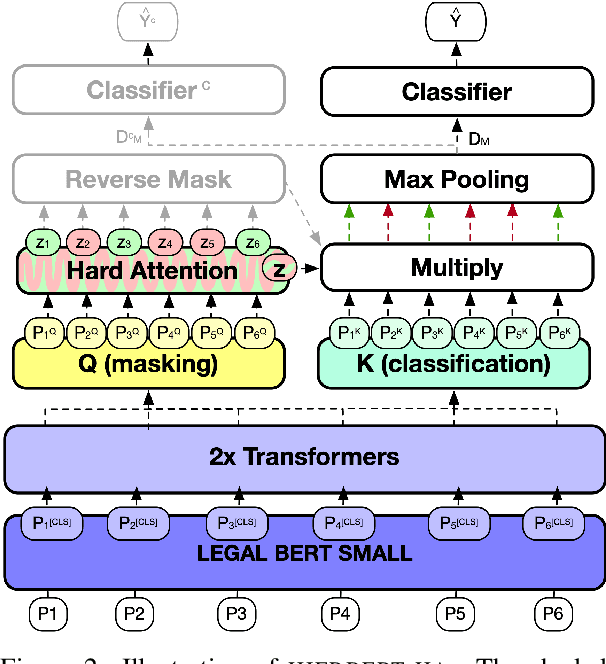
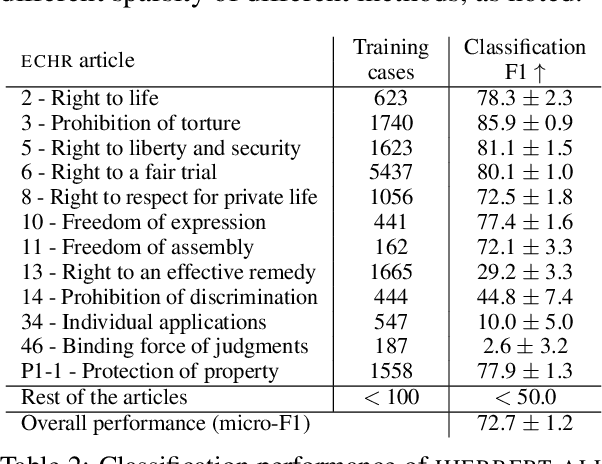
Interpretability or explainability is an emerging research field in NLP. From a user-centric point of view, the goal is to build models that provide proper justification for their decisions, similar to those of humans, by requiring the models to satisfy additional constraints. To this end, we introduce a new application on legal text where, contrary to mainstream literature targeting word-level rationales, we conceive rationales as selected paragraphs in multi-paragraph structured court cases. We also release a new dataset comprising European Court of Human Rights cases, including annotations for paragraph-level rationales. We use this dataset to study the effect of already proposed rationale constraints, i.e., sparsity, continuity, and comprehensiveness, formulated as regularizers. Our findings indicate that some of these constraints are not beneficial in paragraph-level rationale extraction, while others need re-formulation to better handle the multi-label nature of the task we consider. We also introduce a new constraint, singularity, which further improves the quality of rationales, even compared with noisy rationale supervision. Experimental results indicate that the newly introduced task is very challenging and there is a large scope for further research.
Diagnostic Captioning: A Survey
Jan 18, 2021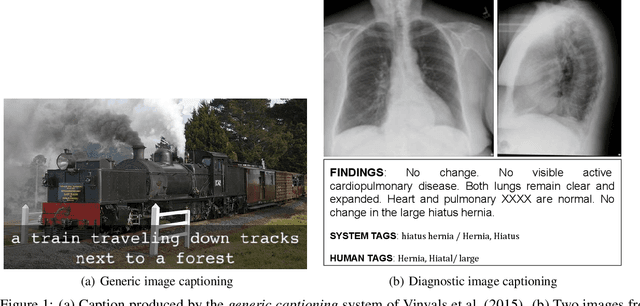

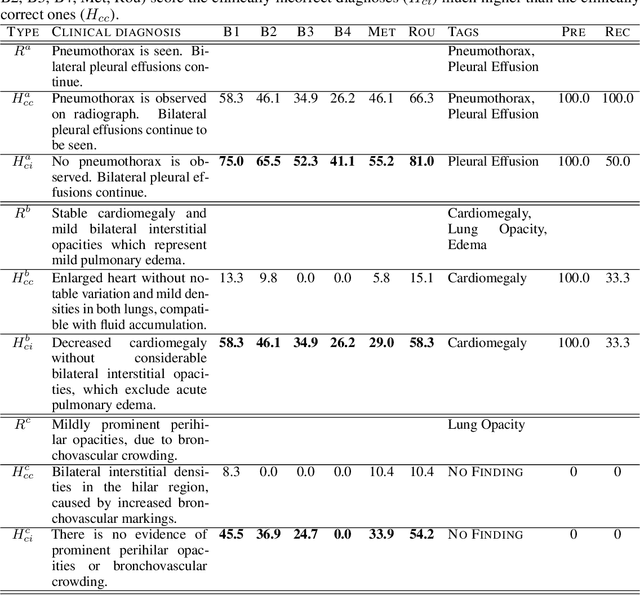
Diagnostic Captioning (DC) concerns the automatic generation of a diagnostic text from a set of medical images of a patient collected during an examination. DC can assist inexperienced physicians, reducing clinical errors. It can also help experienced physicians produce diagnostic reports faster. Following the advances of deep learning, especially in generic image captioning, DC has recently attracted more attention, leading to several systems and datasets. This article is an extensive overview of DC. It presents relevant datasets, evaluation measures, and up to date systems. It also highlights shortcomings that hinder DC's progress and proposes future directions.
Neural Contract Element Extraction Revisited
Jan 12, 2021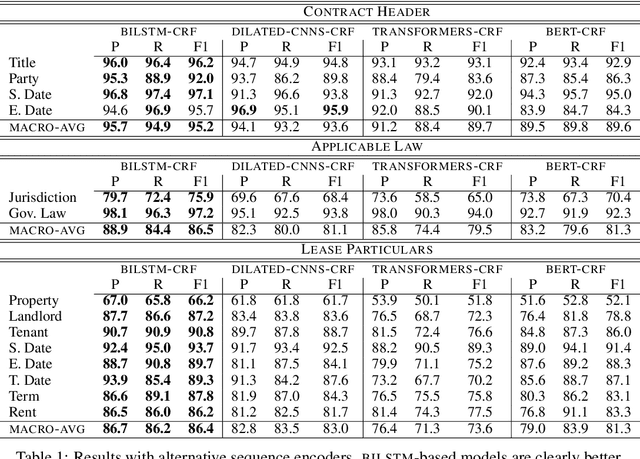

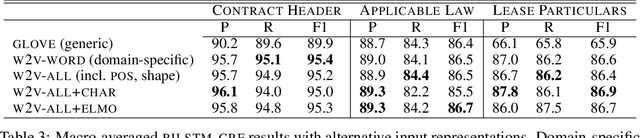
We investigate contract element extraction. We show that LSTM-based encoders perform better than dilated CNNs, Transformers, and BERT in this task. We also find that domain-specific WORD2VEC embeddings outperform generic pre-trained GLOVE embeddings. Morpho-syntactic features in the form of POS tag and token shape embeddings, as well as context-aware ELMO embeddings, do not improve performance. Several of these observations contradict choices or findings of previous work on contract element extraction and generic sequence labeling tasks, indicating that contract element extraction requires careful task-specific choices.
* 4 pages
LEGAL-BERT: The Muppets straight out of Law School
Oct 06, 2020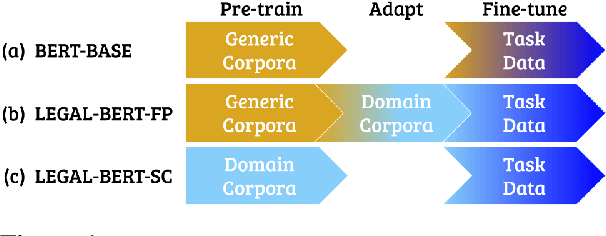

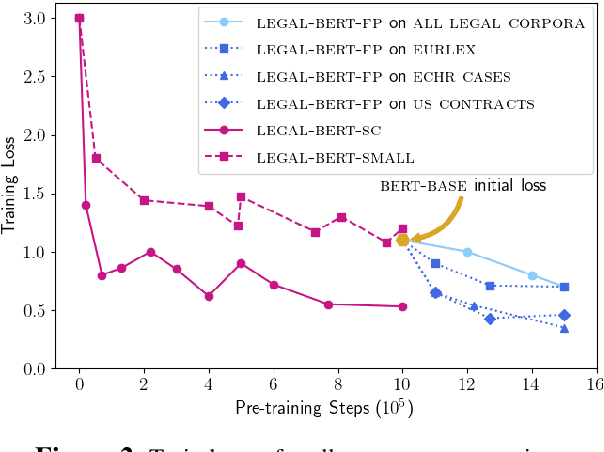
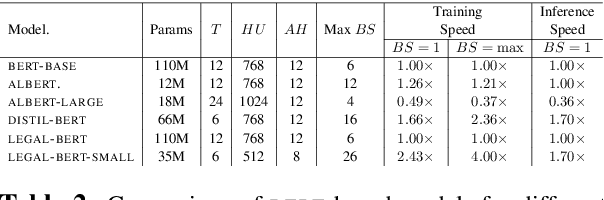
BERT has achieved impressive performance in several NLP tasks. However, there has been limited investigation on its adaptation guidelines in specialised domains. Here we focus on the legal domain, where we explore several approaches for applying BERT models to downstream legal tasks, evaluating on multiple datasets. Our findings indicate that the previous guidelines for pre-training and fine-tuning, often blindly followed, do not always generalize well in the legal domain. Thus we propose a systematic investigation of the available strategies when applying BERT in specialised domains. These are: (a) use the original BERT out of the box, (b) adapt BERT by additional pre-training on domain-specific corpora, and (c) pre-train BERT from scratch on domain-specific corpora. We also propose a broader hyper-parameter search space when fine-tuning for downstream tasks and we release LEGAL-BERT, a family of BERT models intended to assist legal NLP research, computational law, and legal technology applications.
Domain Adversarial Fine-Tuning as an Effective Regularizer
Oct 05, 2020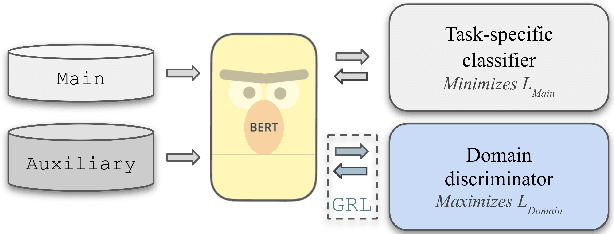
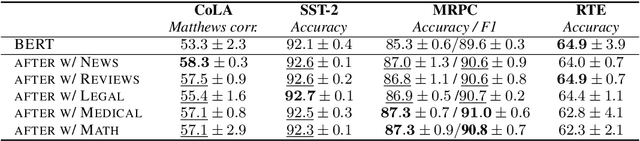

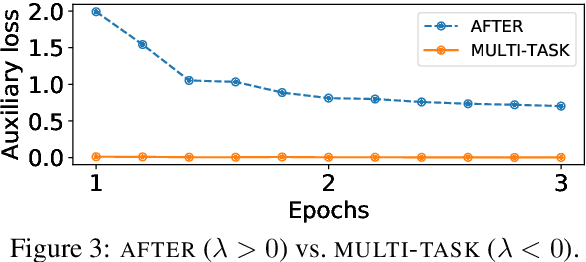
In Natural Language Processing (NLP), pretrained language models (LMs) that are transferred to downstream tasks have been recently shown to achieve state-of-the-art results. However, standard fine-tuning can degrade the general-domain representations captured during pretraining. To address this issue, we introduce a new regularization technique, AFTER; domain Adversarial Fine-Tuning as an Effective Regularizer. Specifically, we complement the task-specific loss used during fine-tuning with an adversarial objective. This additional loss term is related to an adversarial classifier, that aims to discriminate between in-domain and out-of-domain text representations. In-domain refers to the labeled dataset of the task at hand while out-of-domain refers to unlabeled data from a different domain. Intuitively, the adversarial classifier acts as a regularizer which prevents the model from overfitting to the task-specific domain. Empirical results on various natural language understanding tasks show that AFTER leads to improved performance compared to standard fine-tuning.
An Empirical Study on Large-Scale Multi-Label Text Classification Including Few and Zero-Shot Labels
Oct 04, 2020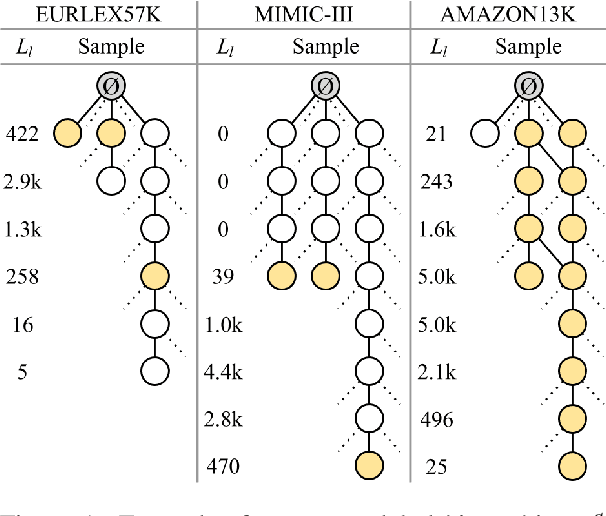
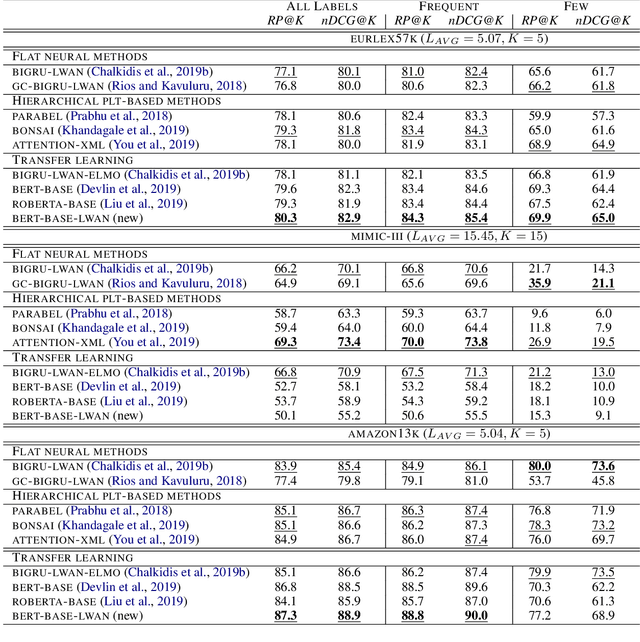
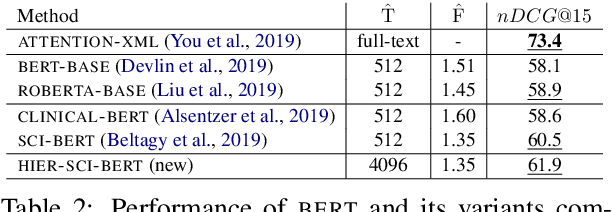
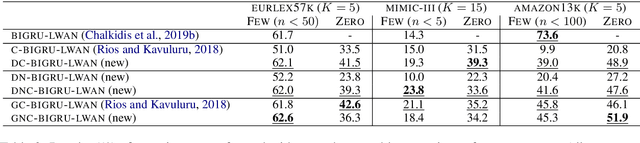
Large-scale Multi-label Text Classification (LMTC) has a wide range of Natural Language Processing (NLP) applications and presents interesting challenges. First, not all labels are well represented in the training set, due to the very large label set and the skewed label distributions of LMTC datasets. Also, label hierarchies and differences in human labelling guidelines may affect graph-aware annotation proximity. Finally, the label hierarchies are periodically updated, requiring LMTC models capable of zero-shot generalization. Current state-of-the-art LMTC models employ Label-Wise Attention Networks (LWANs), which (1) typically treat LMTC as flat multi-label classification; (2) may use the label hierarchy to improve zero-shot learning, although this practice is vastly understudied; and (3) have not been combined with pre-trained Transformers (e.g. BERT), which have led to state-of-the-art results in several NLP benchmarks. Here, for the first time, we empirically evaluate a battery of LMTC methods from vanilla LWANs to hierarchical classification approaches and transfer learning, on frequent, few, and zero-shot learning on three datasets from different domains. We show that hierarchical methods based on Probabilistic Label Trees (PLTs) outperform LWANs. Furthermore, we show that Transformer-based approaches outperform the state-of-the-art in two of the datasets, and we propose a new state-of-the-art method which combines BERT with LWANs. Finally, we propose new models that leverage the label hierarchy to improve few and zero-shot learning, considering on each dataset a graph-aware annotation proximity measure that we introduce.
GREEK-BERT: The Greeks visiting Sesame Street
Sep 03, 2020Transformer-based language models, such as BERT and its variants, have achieved state-of-the-art performance in several downstream natural language processing (NLP) tasks on generic benchmark datasets (e.g., GLUE, SQUAD, RACE). However, these models have mostly been applied to the resource-rich English language. In this paper, we present GREEK-BERT, a monolingual BERT-based language model for modern Greek. We evaluate its performance in three NLP tasks, i.e., part-of-speech tagging, named entity recognition, and natural language inference, obtaining state-of-the-art performance. Interestingly, in two of the benchmarks GREEK-BERT outperforms two multilingual Transformer-based models (M-BERT, XLM-R), as well as shallower neural baselines operating on pre-trained word embeddings, by a large margin (5%-10%). Most importantly, we make both GREEK-BERT and our training code publicly available, along with code illustrating how GREEK-BERT can be fine-tuned for downstream NLP tasks. We expect these resources to boost NLP research and applications for modern Greek.
Toxicity Detection: Does Context Really Matter?
Jun 01, 2020
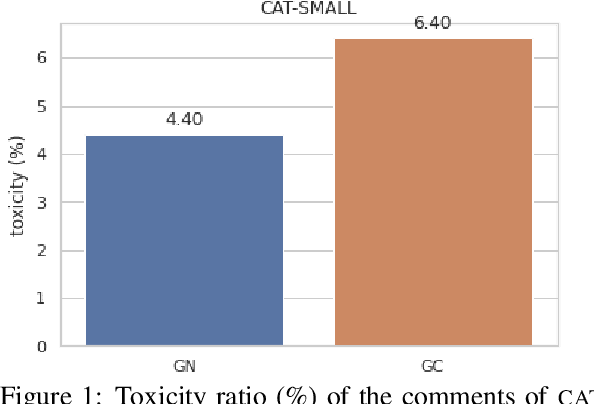

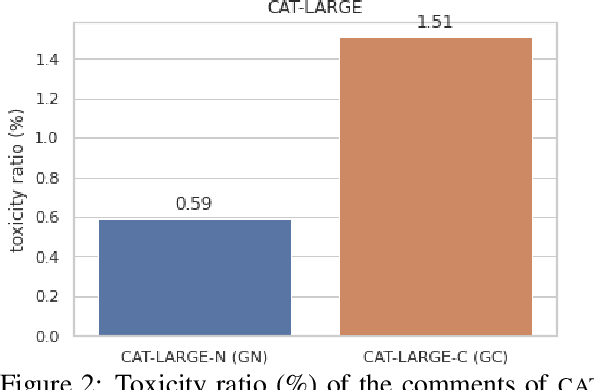
Moderation is crucial to promoting healthy on-line discussions. Although several `toxicity' detection datasets and models have been published, most of them ignore the context of the posts, implicitly assuming that comments maybe judged independently. We investigate this assumption by focusing on two questions: (a) does context affect the human judgement, and (b) does conditioning on context improve performance of toxicity detection systems? We experiment with Wikipedia conversations, limiting the notion of context to the previous post in the thread and the discussion title. We find that context can both amplify or mitigate the perceived toxicity of posts. Moreover, a small but significant subset of manually labeled posts (5% in one of our experiments) end up having the opposite toxicity labels if the annotators are not provided with context. Surprisingly, we also find no evidence that context actually improves the performance of toxicity classifiers, having tried a range of classifiers and mechanisms to make them context aware. This points to the need for larger datasets of comments annotated in context. We make our code and data publicly available.
BIOMRC: A Dataset for Biomedical Machine Reading Comprehension
May 13, 2020
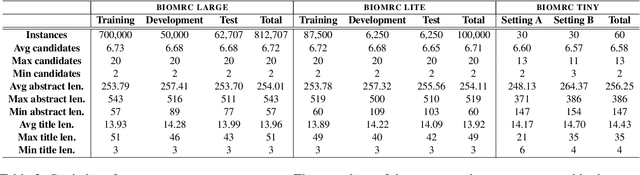
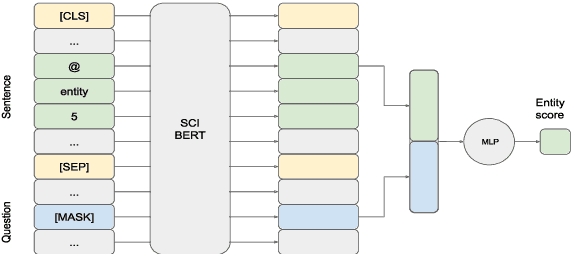
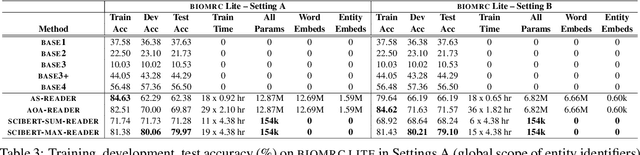
We introduce BIOMRC, a large-scale cloze-style biomedical MRC dataset. Care was taken to reduce noise, compared to the previous BIOREAD dataset of Pappas et al. (2018). Experiments show that simple heuristics do not perform well on the new dataset, and that two neural MRC models that had been tested on BIOREAD perform much better on BIOMRC, indicating that the new dataset is indeed less noisy or at least that its task is more feasible. Non-expert human performance is also higher on the new dataset compared to BIOREAD, and biomedical experts perform even better. We also introduce a new BERT-based MRC model, the best version of which substantially outperforms all other methods tested, reaching or surpassing the accuracy of biomedical experts in some experiments. We make the new dataset available in three different sizes, also releasing our code, and providing a leaderboard.
SumQE: a BERT-based Summary Quality Estimation Model
Sep 02, 2019
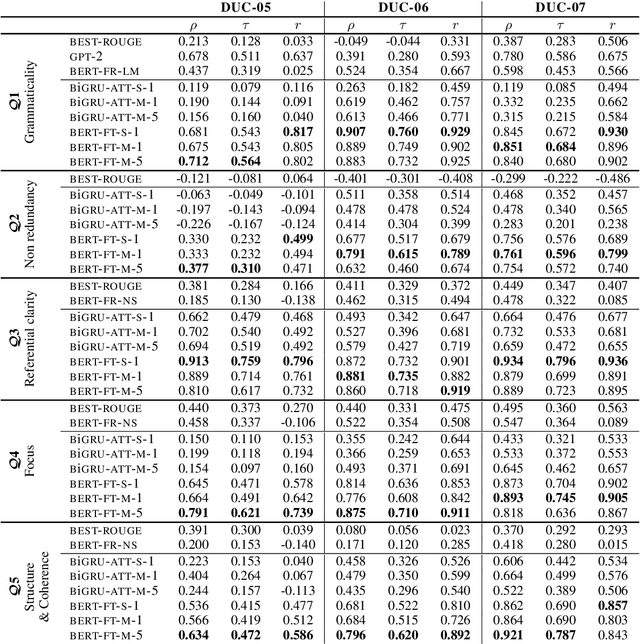
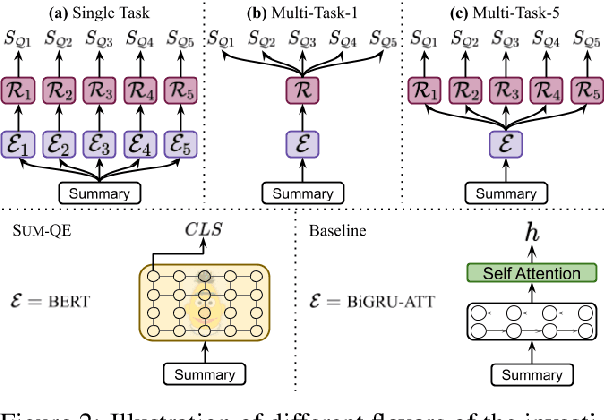
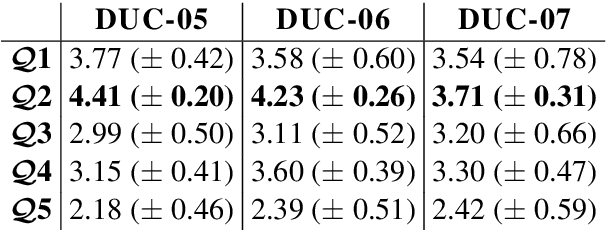
We propose SumQE, a novel Quality Estimation model for summarization based on BERT. The model addresses linguistic quality aspects that are only indirectly captured by content-based approaches to summary evaluation, without involving comparison with human references. SumQE achieves very high correlations with human ratings, outperforming simpler models addressing these linguistic aspects. Predictions of the SumQE model can be used for system development, and to inform users of the quality of automatically produced summaries and other types of generated text.