 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Multiplicative Weights Update Avoids Saddle Points almost always
Apr 25, 2022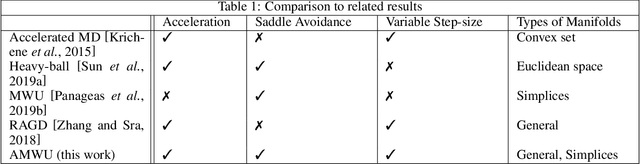
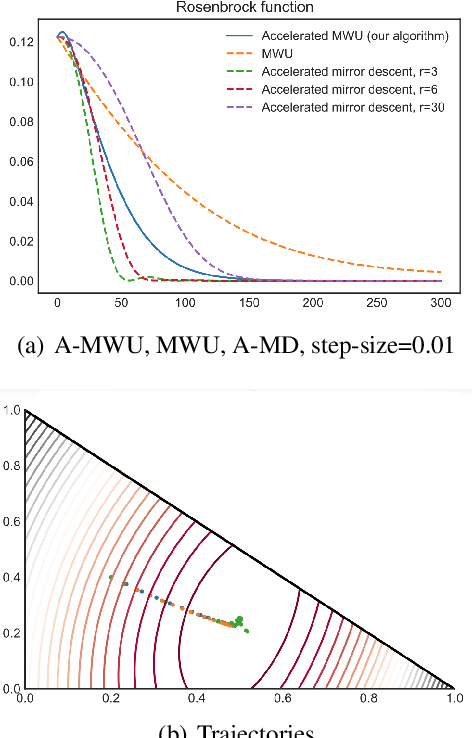
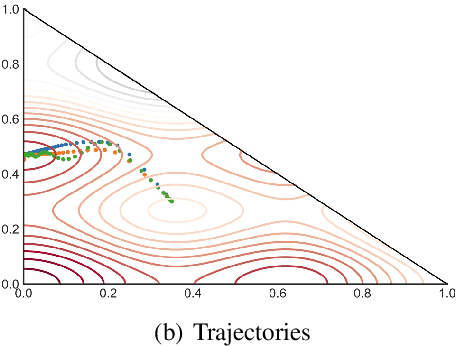
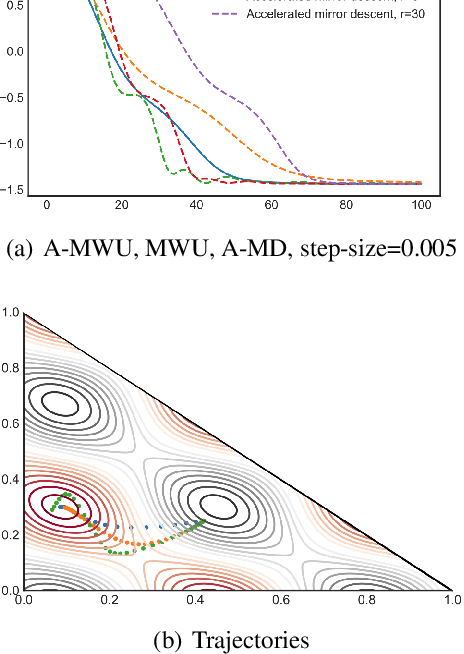
We consider non-convex optimization problems with constraint that is a product of simplices. A commonly used algorithm in solving this type of problem is the Multiplicative Weights Update (MWU), an algorithm that is widely used in game theory, machine learning and multi-agent systems. Despite it has been known that MWU avoids saddle points, there is a question that remains unaddressed:"Is there an accelerated version of MWU that avoids saddle points provably?" In this paper we provide a positive answer to above question. We provide an accelerated MWU based on Riemannian Accelerated Gradient Descent, and prove that the Riemannian Accelerated Gradient Descent, thus the accelerated MWU, almost always avoid saddle points.
Teamwork makes von Neumann work: Min-Max Optimization in Two-Team Zero-Sum Games
Nov 29, 2021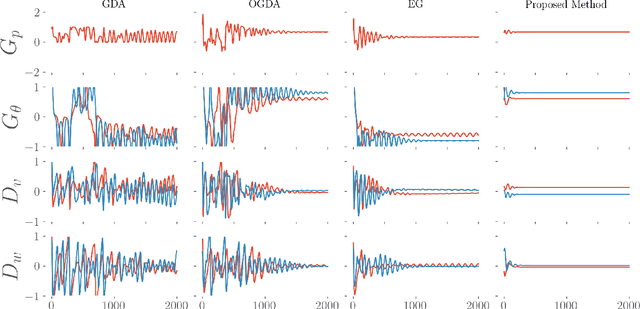
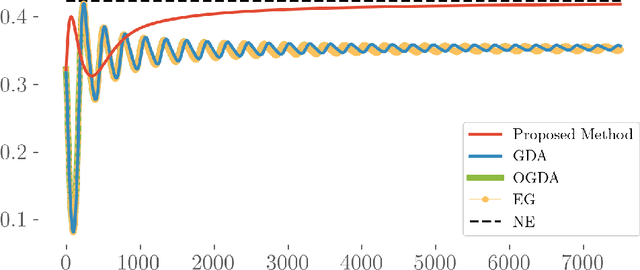


Motivated by recent advances in both theoretical and applied aspects of multiplayer games, spanning from e-sports to multi-agent generative adversarial networks, we focus on min-max optimization in team zero-sum games. In this class of games, players are split into two teams with payoffs equal within the same team and of opposite sign across the opponent team. Unlike the textbook two-player zero-sum games, finding a Nash equilibrium in our class can be shown to be CLS-hard, i.e., it is unlikely to have a polynomial-time algorithm for computing Nash equilibria. Moreover, in this generalized framework, we establish that even asymptotic last iterate or time average convergence to a Nash Equilibrium is not possible using Gradient Descent Ascent (GDA), its optimistic variant, and extra gradient. Specifically, we present a family of team games whose induced utility is \emph{non} multi-linear with \emph{non} attractive \emph{per-se} mixed Nash Equilibria, as strict saddle points of the underlying optimization landscape. Leveraging techniques from control theory, we complement these negative results by designing a modified GDA that converges locally to Nash equilibria. Finally, we discuss connections of our framework with AI architectures with team competition structures like multi-agent generative adversarial networks.
Independent Natural Policy Gradient Always Converges in Markov Potential Games
Oct 20, 2021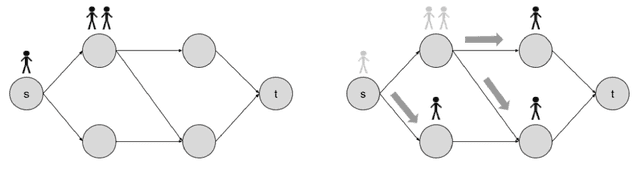
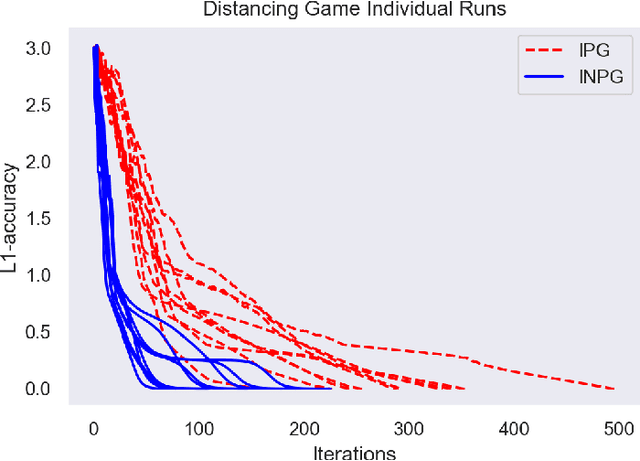
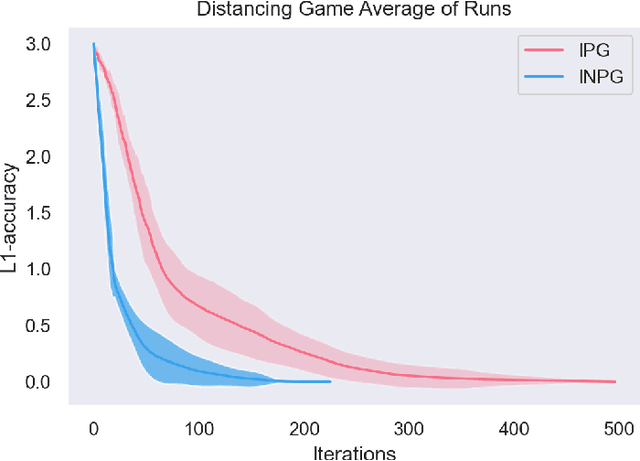
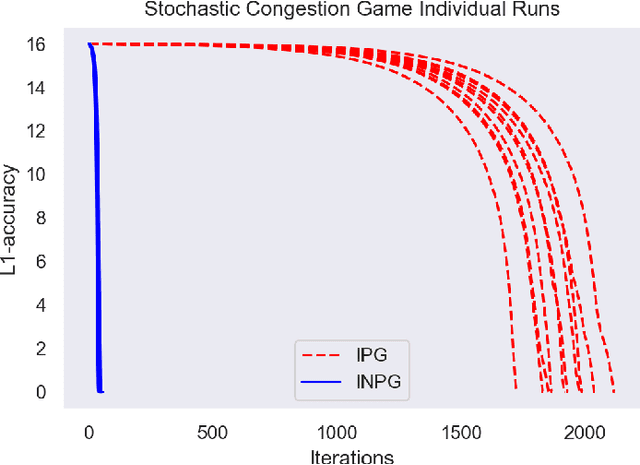
Multi-agent reinforcement learning has been successfully applied to fully-cooperative and fully-competitive environments, but little is currently known about mixed cooperative/competitive environments. In this paper, we focus on a particular class of multi-agent mixed cooperative/competitive stochastic games called Markov Potential Games (MPGs), which include cooperative games as a special case. Recent results have shown that independent policy gradient converges in MPGs but it was not known whether Independent Natural Policy Gradient converges in MPGs as well. We prove that Independent Natural Policy Gradient always converges in the last iterate using constant learning rates. The proof deviates from the existing approaches and the main challenge lies in the fact that Markov Potential Games do not have unique optimal values (as single-agent settings exhibit) so different initializations can lead to different limit point values. We complement our theoretical results with experiments that indicate that Natural Policy Gradient outperforms Policy Gradient in routing games and congestion games.
Global Convergence of Multi-Agent Policy Gradient in Markov Potential Games
Jun 03, 2021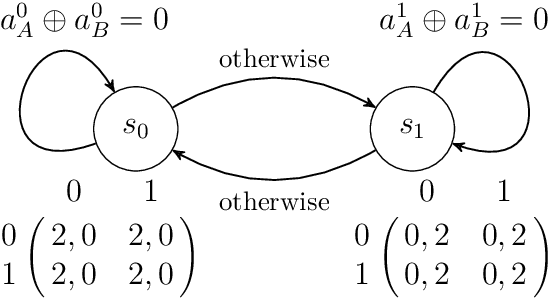
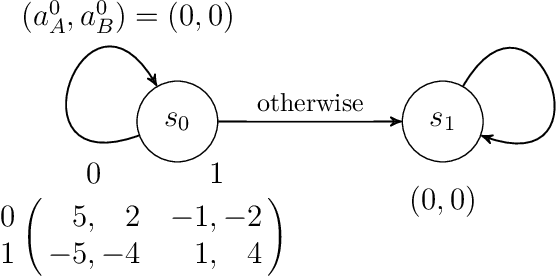
Potential games are arguably one of the most important and widely studied classes of normal form games. They define the archetypal setting of multi-agent coordination as all agent utilities are perfectly aligned with each other via a common potential function. Can this intuitive framework be transplanted in the setting of Markov Games? What are the similarities and differences between multi-agent coordination with and without state dependence? We present a novel definition of Markov Potential Games (MPG) that generalizes prior attempts at capturing complex stateful multi-agent coordination. Counter-intuitively, insights from normal-form potential games do not carry over as MPGs can consist of settings where state-games can be zero-sum games. In the opposite direction, Markov games where every state-game is a potential game are not necessarily MPGs. Nevertheless, MPGs showcase standard desirable properties such as the existence of deterministic Nash policies. In our main technical result, we prove fast convergence of independent policy gradient to Nash policies by adapting recent gradient dominance property arguments developed for single agent MDPs to multi-agent learning settings.
Fast Convergence of Langevin Dynamics on Manifold: Geodesics meet Log-Sobolev
Oct 11, 2020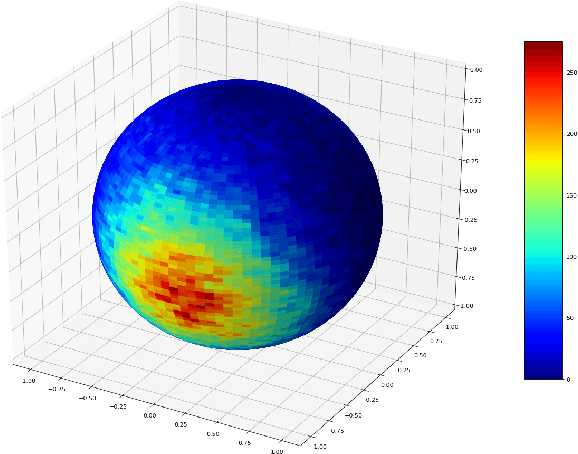
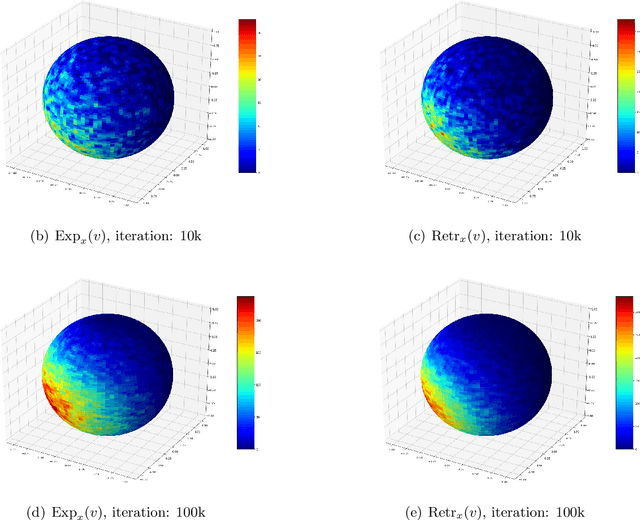
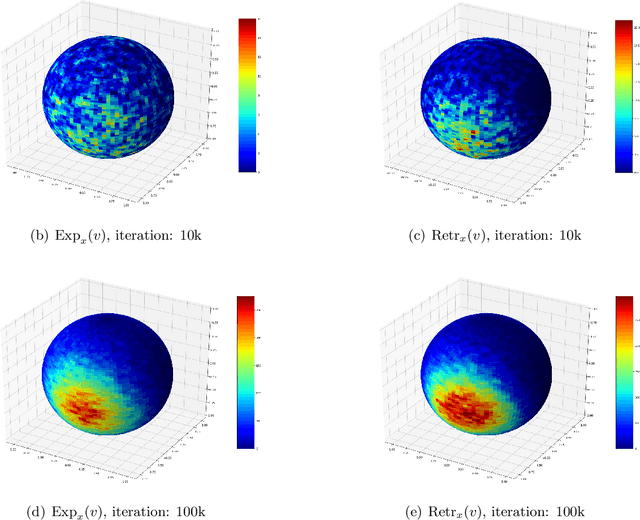
Sampling is a fundamental and arguably very important task with numerous applications in Machine Learning. One approach to sample from a high dimensional distribution $e^{-f}$ for some function $f$ is the Langevin Algorithm (LA). Recently, there has been a lot of progress in showing fast convergence of LA even in cases where $f$ is non-convex, notably [53], [39] in which the former paper focuses on functions $f$ defined in $\mathbb{R}^n$ and the latter paper focuses on functions with symmetries (like matrix completion type objectives) with manifold structure. Our work generalizes the results of [53] where $f$ is defined on a manifold $M$ rather than $\mathbb{R}^n$. From technical point of view, we show that KL decreases in a geometric rate whenever the distribution $e^{-f}$ satisfies a log-Sobolev inequality on $M$.
Efficient Statistics for Sparse Graphical Models from Truncated Samples
Jun 17, 2020
In this paper, we study high-dimensional estimation from truncated samples. We focus on two fundamental and classical problems: (i) inference of sparse Gaussian graphical models and (ii) support recovery of sparse linear models. (i) For Gaussian graphical models, suppose $d$-dimensional samples ${\bf x}$ are generated from a Gaussian $N(\mu,\Sigma)$ and observed only if they belong to a subset $S \subseteq \mathbb{R}^d$. We show that ${\mu}$ and ${\Sigma}$ can be estimated with error $\epsilon$ in the Frobenius norm, using $\tilde{O}\left(\frac{\textrm{nz}({\Sigma}^{-1})}{\epsilon^2}\right)$ samples from a truncated $\mathcal{N}({\mu},{\Sigma})$ and having access to a membership oracle for $S$. The set $S$ is assumed to have non-trivial measure under the unknown distribution but is otherwise arbitrary. (ii) For sparse linear regression, suppose samples $({\bf x},y)$ are generated where $y = {\bf x}^\top{{\Omega}^*} + \mathcal{N}(0,1)$ and $({\bf x}, y)$ is seen only if $y$ belongs to a truncation set $S \subseteq \mathbb{R}$. We consider the case that ${\Omega}^*$ is sparse with a support set of size $k$. Our main result is to establish precise conditions on the problem dimension $d$, the support size $k$, the number of observations $n$, and properties of the samples and the truncation that are sufficient to recover the support of ${\Omega}^*$. Specifically, we show that under some mild assumptions, only $O(k^2 \log d)$ samples are needed to estimate ${\Omega}^*$ in the $\ell_\infty$-norm up to a bounded error. For both problems, our estimator minimizes the sum of the finite population negative log-likelihood function and an $\ell_1$-regularization term.
Convergence to Second-Order Stationarity for Non-negative Matrix Factorization: Provably and Concurrently
Mar 19, 2020
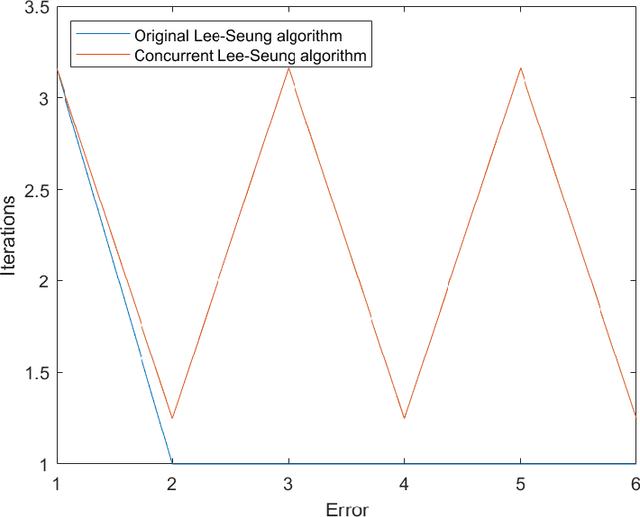
Non-negative matrix factorization (NMF) is a fundamental non-convex optimization problem with numerous applications in Machine Learning (music analysis, document clustering, speech-source separation etc). Despite having received extensive study, it is poorly understood whether or not there exist natural algorithms that can provably converge to a local minimum. Part of the reason is because the objective is heavily symmetric and its gradient is not Lipschitz. In this paper we define a multiplicative weight update type dynamics (modification of the seminal Lee-Seung algorithm) that runs concurrently and provably avoids saddle points (first order stationary points that are not second order). Our techniques combine tools from dynamical systems such as stability and exploit the geometry of the NMF objective by reducing the standard NMF formulation over the non-negative orthant to a new formulation over (a scaled) simplex. An important advantage of our method is the use of concurrent updates, which permits implementations in parallel computing environments.
Logistic-Regression with peer-group effects via inference in higher order Ising models
Mar 18, 2020Spin glass models, such as the Sherrington-Kirkpatrick, Hopfield and Ising models, are all well-studied members of the exponential family of discrete distributions, and have been influential in a number of application domains where they are used to model correlation phenomena on networks. Conventionally these models have quadratic sufficient statistics and consequently capture correlations arising from pairwise interactions. In this work we study extensions of these to models with higher-order sufficient statistics, modeling behavior on a social network with peer-group effects. In particular, we model binary outcomes on a network as a higher-order spin glass, where the behavior of an individual depends on a linear function of their own vector of covariates and some polynomial function of the behavior of others, capturing peer-group effects. Using a {\em single}, high-dimensional sample from such model our goal is to recover the coefficients of the linear function as well as the strength of the peer-group effects. The heart of our result is a novel approach for showing strong concavity of the log pseudo-likelihood of the model, implying statistical error rate of $\sqrt{d/n}$ for the Maximum Pseudo-Likelihood Estimator (MPLE), where $d$ is the dimensionality of the covariate vectors and $n$ is the size of the network (number of nodes). Our model generalizes vanilla logistic regression as well as the peer-effect models studied in recent works, and our results extend these results to accommodate higher-order interactions.
Better Depth-Width Trade-offs for Neural Networks through the lens of Dynamical Systems
Mar 02, 2020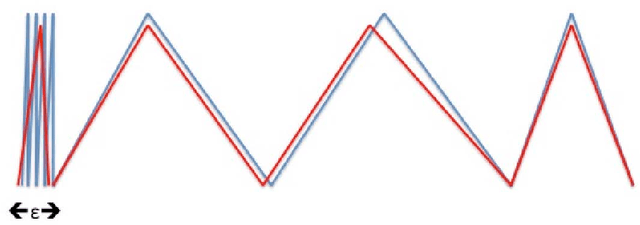
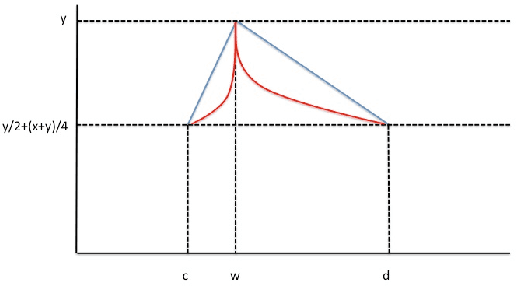
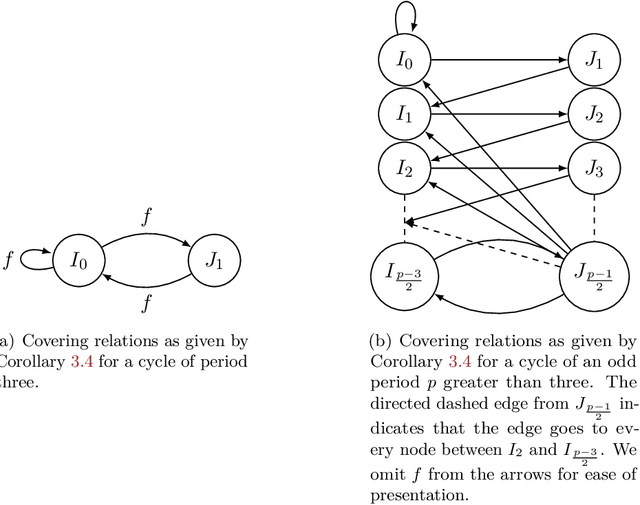
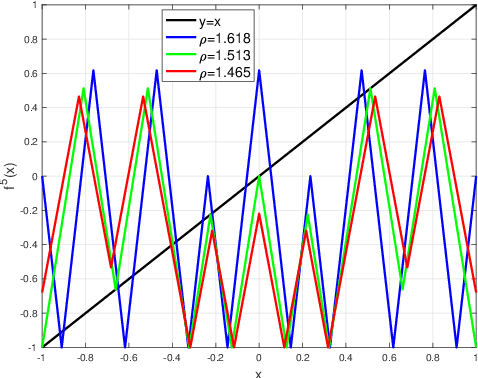
The expressivity of neural networks as a function of their depth, width and type of activation units has been an important question in deep learning theory. Recently, depth separation results for ReLU networks were obtained via a new connection with dynamical systems, using a generalized notion of fixed points of a continuous map $f$, called periodic points. In this work, we strengthen the connection with dynamical systems and we improve the existing width lower bounds along several aspects. Our first main result is period-specific width lower bounds that hold under the stronger notion of $L^1$-approximation error, instead of the weaker classification error. Our second contribution is that we provide sharper width lower bounds, still yielding meaningful exponential depth-width separations, in regimes where previous results wouldn't apply. A byproduct of our results is that there exists a universal constant characterizing the depth-width trade-offs, as long as $f$ has odd periods. Technically, our results follow by unveiling a tighter connection between the following three quantities of a given function: its period, its Lipschitz constant and the growth rate of the number of oscillations arising under compositions of the function $f$ with itself.
Last iterate convergence in no-regret learning: constrained min-max optimization for convex-concave landscapes
Feb 21, 2020
In a recent series of papers it has been established that variants of Gradient Descent/Ascent and Mirror Descent exhibit last iterate convergence in convex-concave zero-sum games. Specifically, \cite{DISZ17, LiangS18} show last iterate convergence of the so called "Optimistic Gradient Descent/Ascent" for the case of \textit{unconstrained} min-max optimization. Moreover, in \cite{Metal} the authors show that Mirror Descent with an extra gradient step displays last iterate convergence for convex-concave problems (both constrained and unconstrained), though their algorithm does not follow the online learning framework; it uses extra information rather than \textit{only} the history to compute the next iteration. In this work, we show that "Optimistic Multiplicative-Weights Update (OMWU)" which follows the no-regret online learning framework, exhibits last iterate convergence locally for convex-concave games, generalizing the results of \cite{DP19} where last iterate convergence of OMWU was shown only for the \textit{bilinear case}. We complement our results with experiments that indicate fast convergence of the method.