 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEINIT: Avoiding Barren Plateaus in Variational Quantum Algorithms
Apr 28, 2022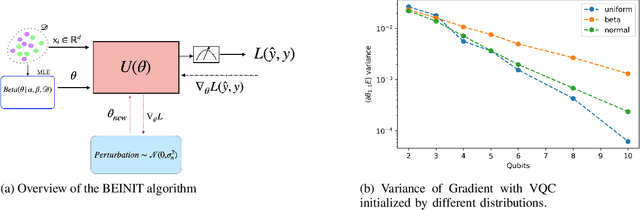
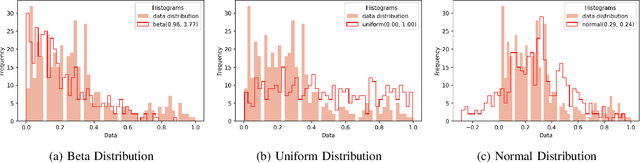
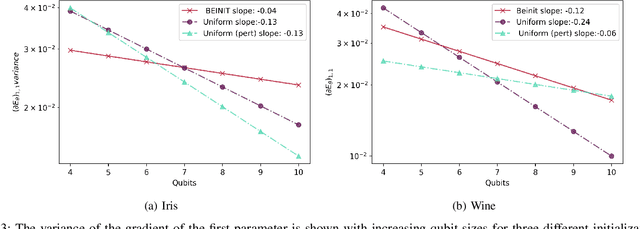
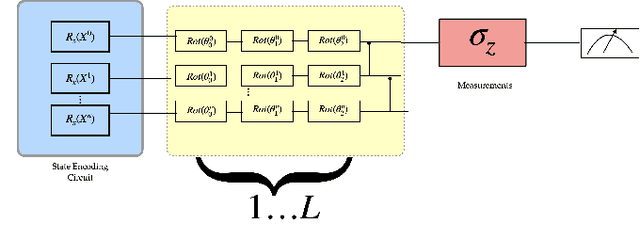
Barren plateaus are a notorious problem in the optimization of variational quantum algorithms and pose a critical obstacle in the quest for more efficient quantum machine learning algorithms. Many potential reasons for barren plateaus have been identified but few solutions have been proposed to avoid them in practice. Existing solutions are mainly focused on the initialization of unitary gate parameters without taking into account the changes induced by input data. In this paper, we propose an alternative strategy which initializes the parameters of a unitary gate by drawing from a beta distribution. The hyperparameters of the beta distribution are estimated from the data. To further prevent barren plateau during training we add a novel perturbation at every gradient descent step. Taking these ideas together, we empirically show that our proposed framework significantly reduces the possibility of a complex quantum neural network getting stuck in a barren plateau.
Proactive Query Expansion for Streaming Data Using External Source
Jan 17, 2022



Query expansion is the process of reformulating the original query by adding relevant words. Choosing which terms to add in order to improve the performance of the query expansion methods or to enhance the quality of the retrieved results is an important aspect of any information retrieval system. Adding words that can positively impact the quality of the search query or are informative enough play an important role in returning or gathering relevant documents that cover a certain topic can result in improving the efficiency of the information retrieval system. Typically, query expansion techniques are used to add or substitute words to a given search query to collect relevant data. In this paper, we design and implement a pipeline of automated query expansion. We outline several tools using different methods to expand the query. Our methods depend on targeting emergent events in streaming data over time and finding the hidden topics from targeted documents using probabilistic topic models. We employ Dynamic Eigenvector Centrality to trigger the emergent events, and the Latent Dirichlet Allocation to discover the topics. Also, we use an external data source as a secondary stream to supplement the primary stream with relevant words and expand the query using the words from both primary and secondary streams. An experimental study is performed on Twitter data (primary stream) related to the events that happened during protests in Baltimore in 2015. The quality of the retrieved results was measured using a quality indicator of the streaming data: tweets count, hashtag count, and hashtag clustering.
FAIRLEARN:Configurable and Interpretable Algorithmic Fairness
Nov 17, 2021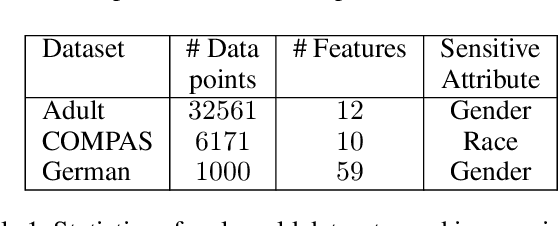
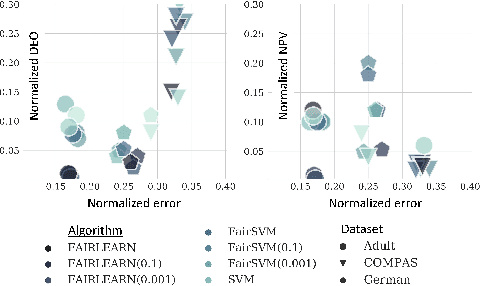
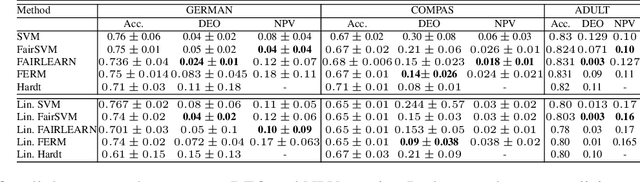
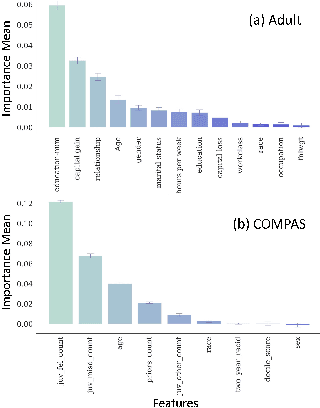
The rapid growth of data in the recent years has led to the development of complex learning algorithms that are often used to make decisions in real world. While the positive impact of the algorithms has been tremendous, there is a need to mitigate any bias arising from either training samples or implicit assumptions made about the data samples. This need becomes critical when algorithms are used in automated decision making systems that can hugely impact people's lives. Many approaches have been proposed to make learning algorithms fair by detecting and mitigating bias in different stages of optimization. However, due to a lack of a universal definition of fairness, these algorithms optimize for a particular interpretation of fairness which makes them limited for real world use. Moreover, an underlying assumption that is common to all algorithms is the apparent equivalence of achieving fairness and removing bias. In other words, there is no user defined criteria that can be incorporated into the optimization procedure for producing a fair algorithm. Motivated by these shortcomings of existing methods, we propose the FAIRLEARN procedure that produces a fair algorithm by incorporating user constraints into the optimization procedure. Furthermore, we make the process interpretable by estimating the most predictive features from data. We demonstrate the efficacy of our approach on several real world datasets using different fairness criteria.
Coping with Mistreatment in Fair Algorithms
Feb 22, 2021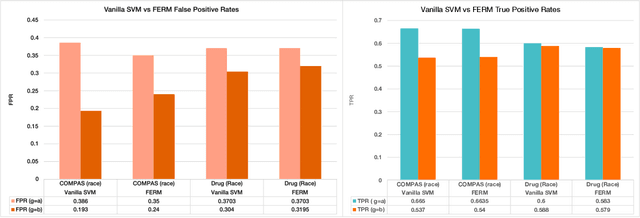
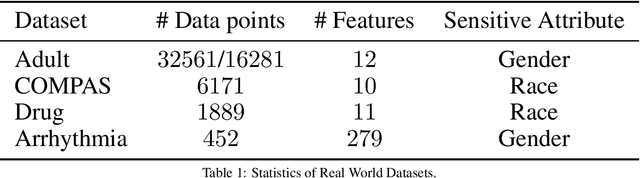

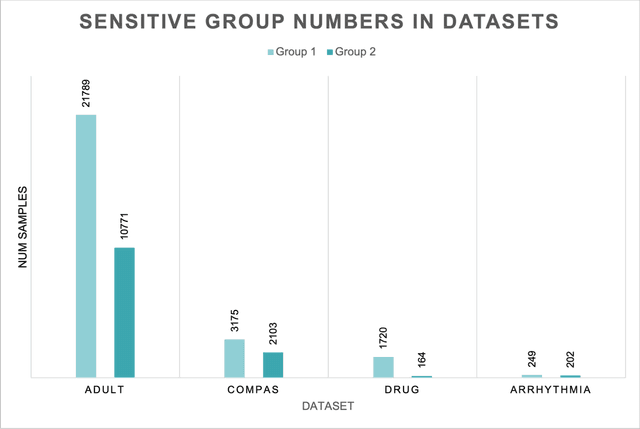
Machine learning actively impacts our everyday life in almost all endeavors and domains such as healthcare, finance, and energy. As our dependence on the machine learning increases, it is inevitable that these algorithms will be used to make decisions that will have a direct impact on the society spanning all resolutions from personal choices to world-wide policies. Hence, it is crucial to ensure that (un)intentional bias does not affect the machine learning algorithms especially when they are required to take decisions that may have unintended consequences. Algorithmic fairness techniques have found traction in the machine learning community and many methods and metrics have been proposed to ensure and evaluate fairness in algorithms and data collection. In this paper, we study the algorithmic fairness in a supervised learning setting and examine the effect of optimizing a classifier for the Equal Opportunity metric. We demonstrate that such a classifier has an increased false positive rate across sensitive groups and propose a conceptually simple method to mitigate this bias. We rigorously analyze the proposed method and evaluate it on several real world datasets demonstrating its efficacy.
Accelerating COVID-19 research with graph mining and transformer-based learning
Feb 10, 2021In 2020, the White House released the, "Call to Action to the Tech Community on New Machine Readable COVID-19 Dataset," wherein artificial intelligence experts are asked to collect data and develop text mining techniques that can help the science community answer high-priority scientific questions related to COVID-19. The Allen Institute for AI and collaborators announced the availability of a rapidly growing open dataset of publications, the COVID-19 Open Research Dataset (CORD-19). As the pace of research accelerates, biomedical scientists struggle to stay current. To expedite their investigations, scientists leverage hypothesis generation systems, which can automatically inspect published papers to discover novel implicit connections. We present an automated general purpose hypothesis generation systems AGATHA-C and AGATHA-GP for COVID-19 research. The systems are based on graph-mining and the transformer model. The systems are massively validated using retrospective information rediscovery and proactive analysis involving human-in-the-loop expert analysis. Both systems achieve high-quality predictions across domains (in some domains up to 0.97% ROC AUC) in fast computational time and are released to the broad scientific community to accelerate biomedical research. In addition, by performing the domain expert curated study, we show that the systems are able to discover on-going research findings such as the relationship between COVID-19 and oxytocin hormone.
Classical symmetries and QAOA
Dec 08, 2020
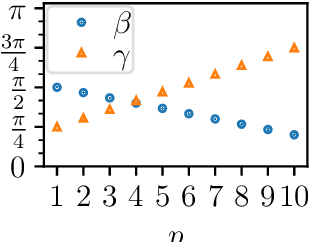
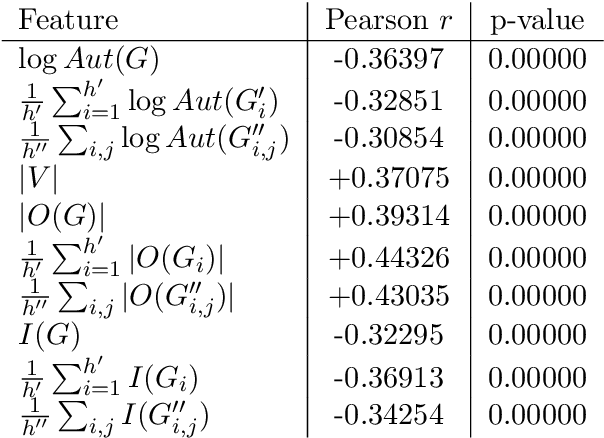
We study the relationship between the Quantum Approximate Optimization Algorithm (QAOA) and the underlying symmetries of the objective function to be optimized. Our approach formalizes the connection between quantum symmetry properties of the QAOA dynamics and the group of classical symmetries of the objective function. The connection is general and includes but is not limited to problems defined on graphs. We show a series of results exploring the connection and highlight examples of hard problem classes where a nontrivial symmetry subgroup can be obtained efficiently. In particular we show how classical objective function symmetries lead to invariant measurement outcome probabilities across states connected by such symmetries, independent of the choice of algorithm parameters or number of layers. To illustrate the power of the developed connection, we apply machine learning techniques towards predicting QAOA performance based on symmetry considerations. We provide numerical evidence that a small set of graph symmetry properties suffices to predict the minimum QAOA depth required to achieve a target approximation ratio on the MaxCut problem, in a practically important setting where QAOA parameter schedules are constrained to be linear and hence easier to optimize.
Accelerating Text Mining Using Domain-Specific Stop Word Lists
Nov 18, 2020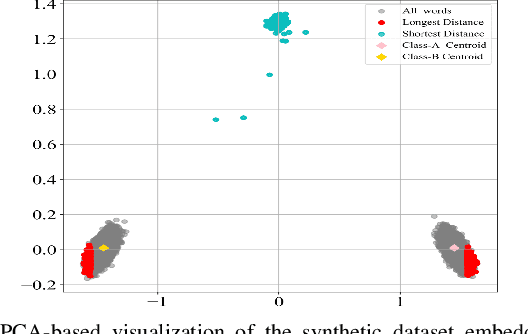
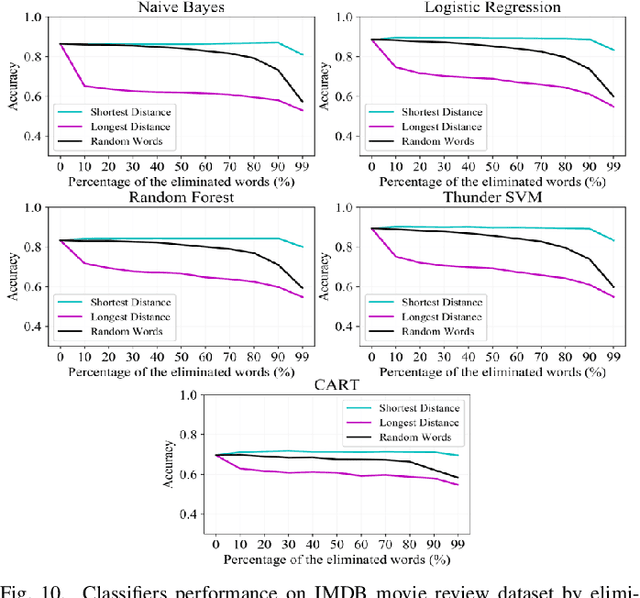
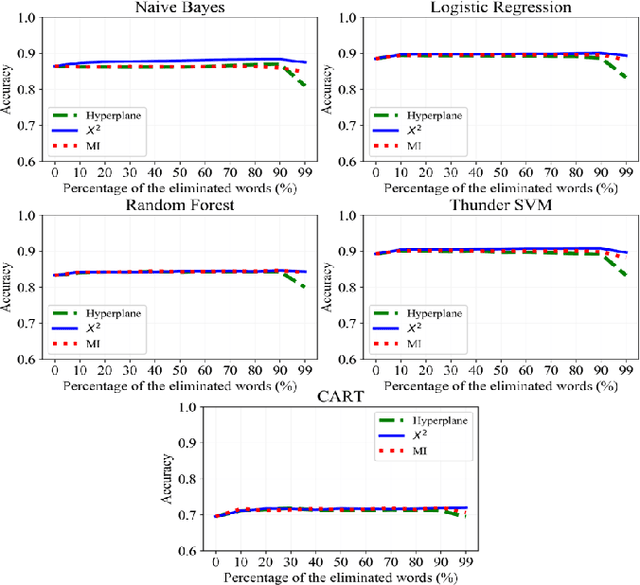
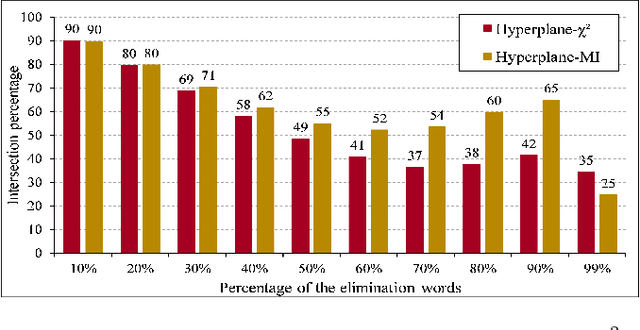
Text preprocessing is an essential step in text mining. Removing words that can negatively impact the quality of prediction algorithms or are not informative enough is a crucial storage-saving technique in text indexing and results in improved computational efficiency. Typically, a generic stop word list is applied to a dataset regardless of the domain. However, many common words are different from one domain to another but have no significance within a particular domain. Eliminating domain-specific common words in a corpus reduces the dimensionality of the feature space, and improves the performance of text mining tasks. In this paper, we present a novel mathematical approach for the automatic extraction of domain-specific words called the hyperplane-based approach. This new approach depends on the notion of low dimensional representation of the word in vector space and its distance from hyperplane. The hyperplane-based approach can significantly reduce text dimensionality by eliminating irrelevant features. We compare the hyperplane-based approach with other feature selection methods, namely \c{hi}2 and mutual information. An experimental study is performed on three different datasets and five classification algorithms, and measure the dimensionality reduction and the increase in the classification performance. Results indicate that the hyperplane-based approach can reduce the dimensionality of the corpus by 90% and outperforms mutual information. The computational time to identify the domain-specific words is significantly lower than mutual information.
AML-SVM: Adaptive Multilevel Learning with Support Vector Machines
Nov 05, 2020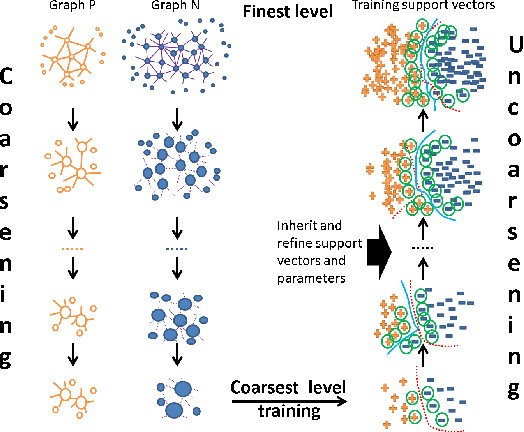
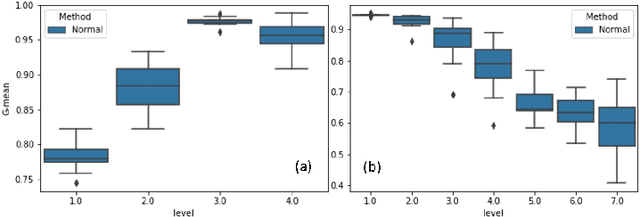
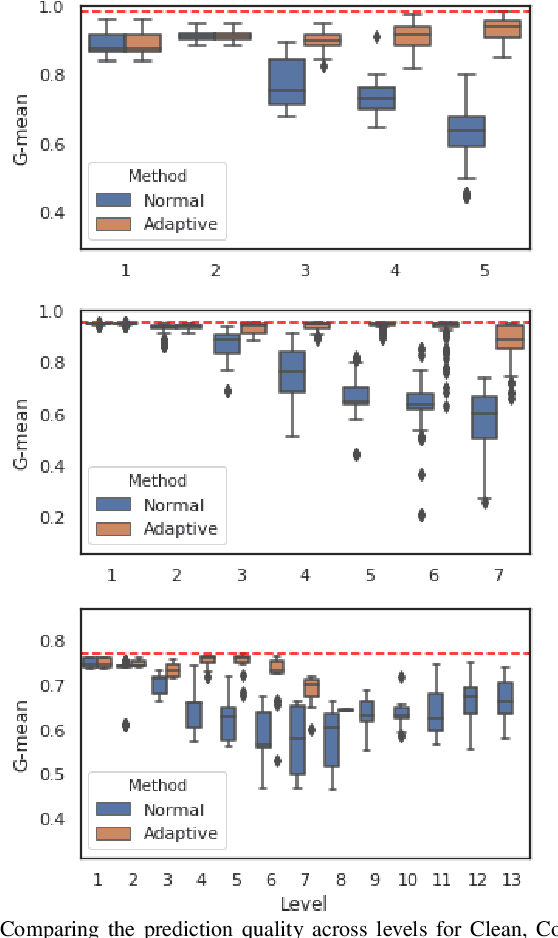

The support vector machines (SVM) is one of the most widely used and practical optimization based classification models in machine learning because of its interpretability and flexibility to produce high quality results. However, the big data imposes a certain difficulty to the most sophisticated but relatively slow versions of SVM, namely, the nonlinear SVM. The complexity of nonlinear SVM solvers and the number of elements in the kernel matrix quadratically increases with the number of samples in training data. Therefore, both runtime and memory requirements are negatively affected. Moreover, the parameter fitting has extra kernel parameters to tune, which exacerbate the runtime even further. This paper proposes an adaptive multilevel learning framework for the nonlinear SVM, which addresses these challenges, improves the classification quality across the refinement process, and leverages multi-threaded parallel processing for better performance. The integration of parameter fitting in the hierarchical learning framework and adaptive process to stop unnecessary computation significantly reduce the running time while increase the overall performance. The experimental results demonstrate reduced variance on prediction over validation and test data across levels in the hierarchy, and significant speedup compared to state-of-the-art nonlinear SVM libraries without a decrease in the classification quality. The code is accessible at https://github.com/esadr/amlsvm.
Unsupervised Hierarchical Graph Representation Learning by Mutual Information Maximization
Apr 02, 2020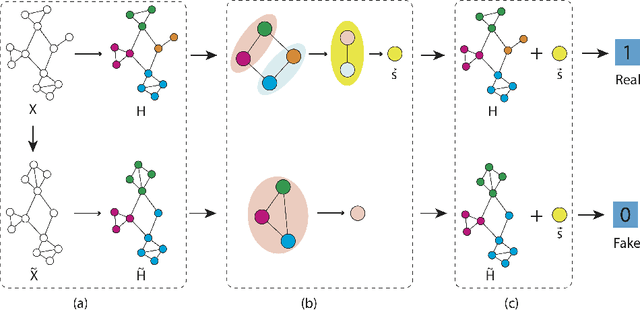
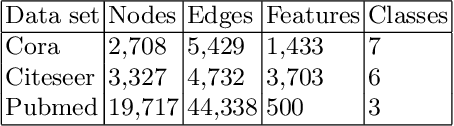
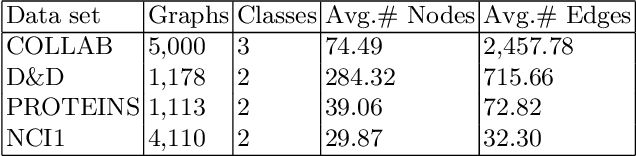
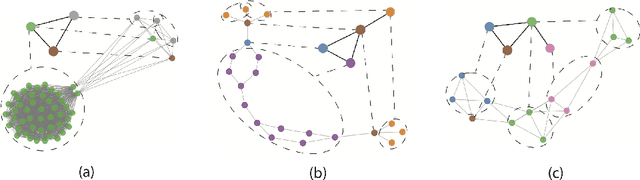
Graph representation learning based on graph neural networks (GNNs) can greatly improve the performance of downstream tasks, such as node and graph classification. However, the general GNN models do not aggregate node information in a hierarchical manner, and can miss key higher-order structural features of many graphs. The hierarchical aggregation also enables the graph representations to be explainable. In addition, supervised graph representation learning requires labeled data, which is expensive and error-prone. To address these issues, we present an unsupervised graph representation learning method, Unsupervised Hierarchical Graph Representation (UHGR), which can generate hierarchical representations of graphs. Our method focuses on maximizing mutual information between "local" and high-level "global" representations, which enables us to learn the node embeddings and graph embeddings without any labeled data. To demonstrate the effectiveness of the proposed method, we perform the node and graph classification using the learned node and graph embeddings. The results show that the proposed method achieves comparable results to state-of-the-art supervised methods on several benchmarks. In addition, our visualization of hierarchical representations indicates that our method can capture meaningful and interpretable clusters.
CBAG: Conditional Biomedical Abstract Generation
Feb 13, 2020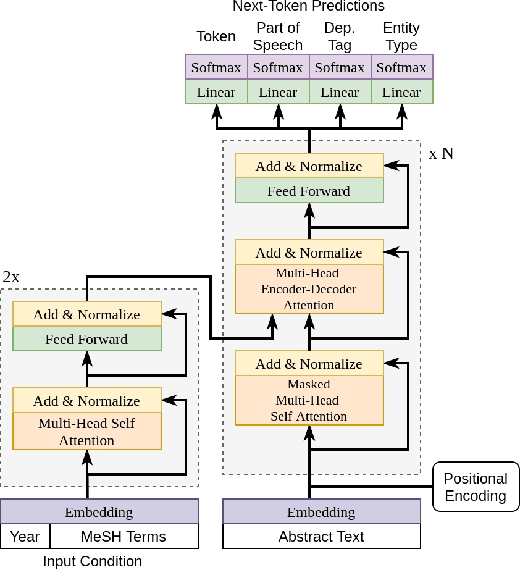
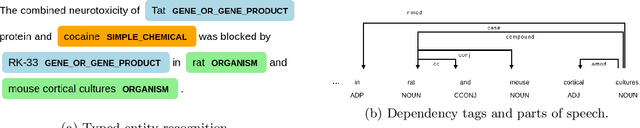
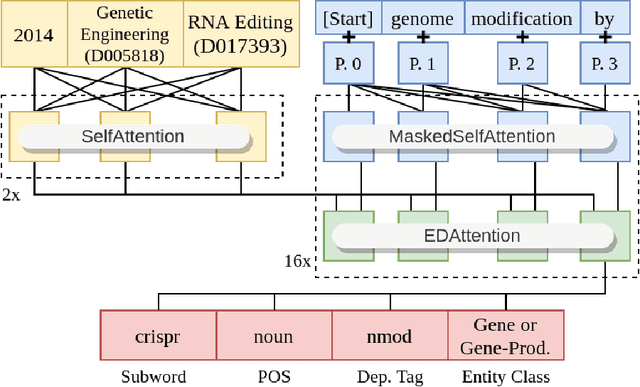
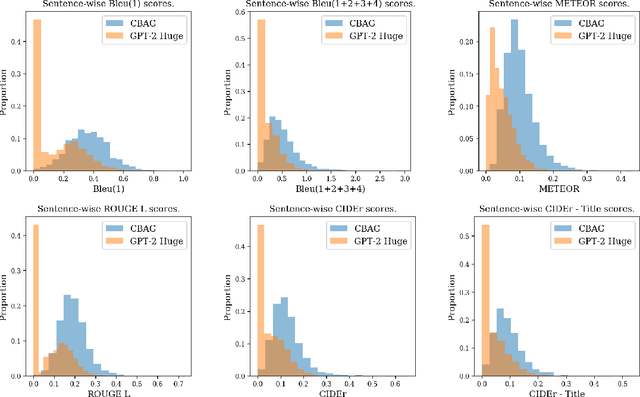
Biomedical research papers use significantly different language and jargon when compared to typical English text, which reduces the utility of pre-trained NLP models in this domain. Meanwhile Medline, a database of biomedical abstracts, introduces nearly a million new documents per-year. Applications that could benefit from understanding this wealth of publicly available information, such as scientific writing assistants, chat-bots, or descriptive hypothesis generation systems, require new domain-centered approaches. A conditional language model, one that learns the probability of words given some a priori criteria, is a fundamental building block in many such applications. We propose a transformer-based conditional language model with a shallow encoder "condition" stack, and a deep "language model" stack of multi-headed attention blocks. The condition stack encodes metadata used to alter the output probability distribution of the language model stack. We sample this distribution in order to generate biomedical abstracts given only a proposed title, an intended publication year, and a set of keywords. Using typical natural language generation metrics, we demonstrate that this proposed approach is more capable of producing non-trivial relevant entities within the abstract body than the 1.5B parameter GPT-2 language model.