 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagnetic Indoor Localization through CNN Regression and Rotation Invariance
Apr 24, 2026Indoor positioning is an essential technology for a wide range of applications in GNSS-denied environments, including indoor navigation and IoT systems. Combining convolutional neural networks (CNNs) and magnetic field-based features offers a low-cost, infrastructure-free solution for precise positioning. While magnetic fingerprints are a promising approach for indoor positioning, models trained on raw 3D magnetometer data are highly sensitive to device orientation. We address this by using two rotation invariant features derived from the 3D magnetic field: the norm (Mn) and the projection onto the gravity axis (Mg). We train a lightweight 7-layer dilated CNN (MagNetS/XL) on magnetic sequences to directly regress (x, y) positions. Using the MagPie dataset (three buildings, handheld trajectories), we systematically evaluate fixed and random rotations of test and/or train data. Raw 3D inputs (Mx, My , Mz) exhibit isotropic error increases under fixed 90° rotations and further degrade with growing random rotations. In contrast, 2D (Mn, Mg) inputs maintain rotation invariant accuracy and surpass the 3D inputs once rotation exceeds building-specific thresholds for three reference buildings: 0° for Loomis (large), 5° for Talbot (medium), and 6° for CSL (small). MagNetXL achieves or exceeds state-of-the-art accuracy on the MagPie dataset, and MagNetS delivers similar performance with roughly one third of the parameters, favoring mobile deployment. These results show that the robustness gained from rotation invariant inputs outweighs the loss of input dimensionality in realistic usage, allowing mapping and localization without orientation alignment or added infrastructure.
Location as a service with a MEC architecture
Feb 13, 2026In recent years, automated driving has become viable, and advanced driver assistance systems (ADAS) are now part of modern cars. These systems require highly precise positioning. In this paper, a cooperative approach to localization is presented. The GPS information from several road users is collected in a Mobile Edge Computing cloud, and the characteristics of GNSS positioning are used to provide lane-precise positioning for all participants by applying probabilistic filters and HD maps.
Performance evaluation of a ROS2 based Automated Driving System
Nov 19, 2024Automated driving is currently a prominent area of scientific work. In the future, highly automated driving and new Advanced Driver Assistance Systems will become reality. While Advanced Driver Assistance Systems and automated driving functions for certain domains are already commercially available, ubiquitous automated driving in complex scenarios remains a subject of ongoing research. Contrarily to single-purpose Electronic Control Units, the software for automated driving is often executed on high performance PCs. The Robot Operating System 2 (ROS2) is commonly used to connect components in an automated driving system. Due to the time critical nature of automated driving systems, the performance of the framework is especially important. In this paper, a thorough performance evaluation of ROS2 is conducted, both in terms of timeliness and error rate. The results show that ROS2 is a suitable framework for automated driving systems.
Railway LiDAR semantic segmentation based on intelligent semi-automated data annotation
Oct 17, 2024



Automated vehicles rely on an accurate and robust perception of the environment. Similarly to automated cars, highly automated trains require an environmental perception. Although there is a lot of research based on either camera or LiDAR sensors in the automotive domain, very few contributions for this task exist yet for automated trains. Additionally, no public dataset or described approach for a 3D LiDAR semantic segmentation in the railway environment exists yet. Thus, we propose an approach for a point-wise 3D semantic segmentation based on the 2DPass network architecture using scans and images jointly. In addition, we present a semi-automated intelligent data annotation approach, which we use to efficiently and accurately label the required dataset recorded on a railway track in Germany. To improve performance despite a still small number of labeled scans, we apply an active learning approach to intelligently select scans for the training dataset. Our contributions are threefold: We annotate rail data including camera and LiDAR data from the railway environment, transfer label the raw LiDAR point clouds using an image segmentation network, and train a state-of-the-art 3D LiDAR semantic segmentation network efficiently leveraging active learning. The trained network achieves good segmentation results with a mean IoU of 71.48% of 9 classes.
Driver Assistance for Safe and Comfortable On-Ramp Merging Using Environment Models Extended through V2X Communication and Role-Based Behavior Predictions
Aug 17, 2020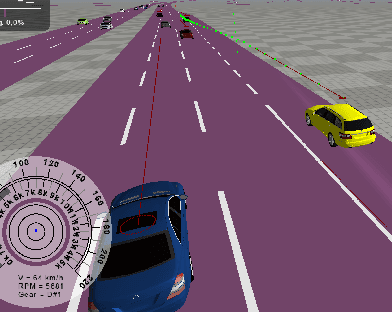
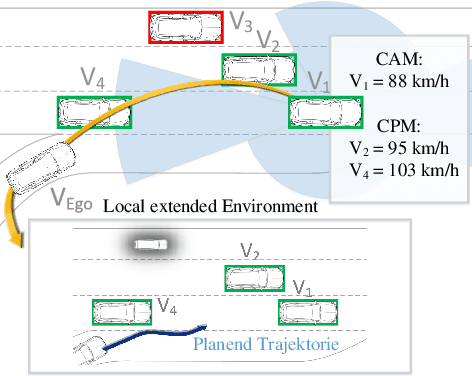
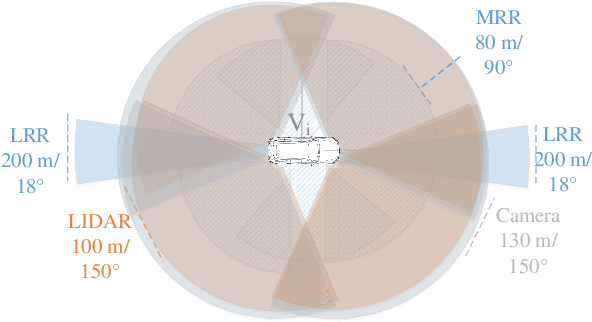
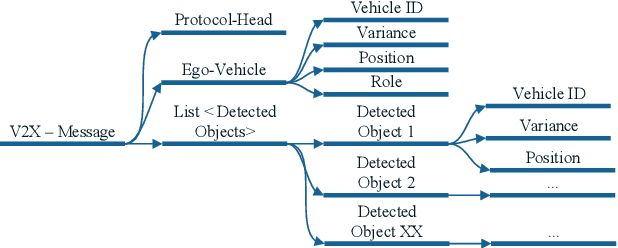
Modern driver assistance systems as well as autonomous vehicles take their decisions based on local maps of the environment. These maps include, for example, surrounding moving objects perceived by sensors as well as routes and navigation information. Current research in the field of environment mapping is concerned with two major challenges. The first one is the integration of information from different sources e.g. on-board sensors like radar, camera, ultrasound and lidar, offline map data or backend information. The second challenge comprises in finding an abstract representation of this aggregated information with suitable interfaces for different driving functions and traffic situations. To overcome these challenges, an extended environment model is a reasonable choice. In this paper, we show that role-based motion predictions in combination with v2x-extended environment models are able to contribute to increased traffic safety and driving comfort. Thus, we combine the mentioned research areas and show possible improvements, using the example of a threading process at a motorway access road. Furthermore, it is shown that already an average v2x equipment penetration of 80% can lead to a significant improvement of 0.33m/s^2 of the total acceleration and 12m more safety distance compared to non v2x-equipped vehicles during the threading process.