 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded P-values in Parametric Programming-based Selective Inference
Jul 21, 2023



Selective inference (SI) has been actively studied as a promising framework for statistical hypothesis testing for data-driven hypotheses. The basic idea of SI is to make inferences conditional on an event that a hypothesis is selected. In order to perform SI, this event must be characterized in a traceable form. When selection event is too difficult to characterize, additional conditions are introduced for tractability. This additional conditions often causes the loss of power, and this issue is referred to as over-conditioning. Parametric programming-based SI (PP-based SI) has been proposed as one way to address the over-conditioning issue. The main problem of PP-based SI is its high computational cost due to the need to exhaustively explore the data space. In this study, we introduce a procedure to reduce the computational cost while guaranteeing the desired precision, by proposing a method to compute the upper and lower bounds of p-values. We also proposed three types of search strategies that efficiently improve these bounds. We demonstrate the effectiveness of the proposed method in hypothesis testing problems for feature selection in linear models and attention region identification in deep neural networks.
Efficient Model Selection for Predictive Pattern Mining Model by Safe Pattern Pruning
Jun 23, 2023Predictive pattern mining is an approach used to construct prediction models when the input is represented by structured data, such as sets, graphs, and sequences. The main idea behind predictive pattern mining is to build a prediction model by considering substructures, such as subsets, subgraphs, and subsequences (referred to as patterns), present in the structured data as features of the model. The primary challenge in predictive pattern mining lies in the exponential growth of the number of patterns with the complexity of the structured data. In this study, we propose the Safe Pattern Pruning (SPP) method to address the explosion of pattern numbers in predictive pattern mining. We also discuss how it can be effectively employed throughout the entire model building process in practical data analysis. To demonstrate the effectiveness of the proposed method, we conduct numerical experiments on regression and classification problems involving sets, graphs, and sequences.
Generalized Low-Rank Update: Model Parameter Bounds for Low-Rank Training Data Modifications
Jun 22, 2023In this study, we have developed an incremental machine learning (ML) method that efficiently obtains the optimal model when a small number of instances or features are added or removed. This problem holds practical importance in model selection, such as cross-validation (CV) and feature selection. Among the class of ML methods known as linear estimators, there exists an efficient model update framework called the low-rank update that can effectively handle changes in a small number of rows and columns within the data matrix. However, for ML methods beyond linear estimators, there is currently no comprehensive framework available to obtain knowledge about the updated solution within a specific computational complexity. In light of this, our study introduces a method called the Generalized Low-Rank Update (GLRU) which extends the low-rank update framework of linear estimators to ML methods formulated as a certain class of regularized empirical risk minimization, including commonly used methods such as SVM and logistic regression. The proposed GLRU method not only expands the range of its applicability but also provides information about the updated solutions with a computational complexity proportional to the amount of dataset changes. To demonstrate the effectiveness of the GLRU method, we conduct experiments showcasing its efficiency in performing cross-validation and feature selection compared to other baseline methods.
Human-In-the-Loop for Bayesian Autonomous Materials Phase Mapping
Jun 17, 2023



Autonomous experimentation (AE) combines machine learning and research hardware automation in a closed loop, guiding subsequent experiments toward user goals. As applied to materials research, AE can accelerate materials exploration, reducing time and cost compared to traditional Edisonian studies. Additionally, integrating knowledge from diverse sources including theory, simulations, literature, and domain experts can boost AE performance. Domain experts may provide unique knowledge addressing tasks that are difficult to automate. Here, we present a set of methods for integrating human input into an autonomous materials exploration campaign for composition-structure phase mapping. The methods are demonstrated on x-ray diffraction data collected from a thin film ternary combinatorial library. At any point during the campaign, the user can choose to provide input by indicating regions-of-interest, likely phase regions, and likely phase boundaries based on their prior knowledge (e.g., knowledge of the phase map of a similar material system), along with quantifying their certainty. The human input is integrated by defining a set of probabilistic priors over the phase map. Algorithm output is a probabilistic distribution over potential phase maps, given the data, model, and human input. We demonstrate a significant improvement in phase mapping performance given appropriate human input.
Adaptive Defective Area Identification in Material Surface Using Active Transfer Learning-based Level Set Estimation
Apr 03, 2023In material characterization, identifying defective areas on a material surface is fundamental. The conventional approach involves measuring the relevant physical properties point-by-point at the predetermined mesh grid points on the surface and determining the area at which the property does not reach the desired level. To identify defective areas more efficiently, we propose adaptive mapping methods in which measurement resources are used preferentially to detect the boundaries of defective areas. We interpret this problem as an active-learning (AL) of the level set estimation (LSE) problem. The goal of AL-based LSE is to determine the level set of the physical property function defined on the surface with as small number of measurements as possible. Furthermore, to handle the situations in which materials with similar specifications are repeatedly produced, we introduce a transfer learning approach so that the information of previously produced materials can be effectively utilized. As a proof-of-concept, we applied the proposed methods to the red-zone estimation problem of silicon wafers and demonstrated that we could identify the defective areas with significantly lower measurement costs than those of conventional methods.
Latent Reconstruction-Aware Variational Autoencoder
Feb 05, 2023Variational Autoencoders (VAEs) have become increasingly popular in recent years due to their ability to generate new objects such as images and texts from a given dataset. This ability has led to a wide range of applications. While standard tasks often require sampling from high-density regions in the latent space, there are also tasks that require sampling from low-density regions, such as Morphing and Latent Space Bayesian Optimization (LS-BO). These tasks are becoming increasingly important in fields such as de novo molecular design, where the ability to generate diverse and high-quality chemical compounds is essential. In this study, we investigate the issue of low-quality objects generated from low-density regions in VAEs. To address this problem, we propose a new VAE model, the Latent Reconstruction-Aware VAE (LRA-VAE). The LRA-VAE model takes into account what we refer to as the Latent Reconstruction Error (LRE) of the latent variables. We evaluate our proposal using Morphing and LS-BO experiments, and show that LRA-VAE can improve the quality of generated objects over the other approaches, making it a promising solution for various generation tasks that involve sampling from low-density regions.
Distributionally Robust Multi-objective Bayesian Optimization under Uncertain Environments
Jan 27, 2023In this study, we address the problem of optimizing multi-output black-box functions under uncertain environments. We formulate this problem as the estimation of the uncertain Pareto-frontier (PF) of a multi-output Bayesian surrogate model with two types of variables: design variables and environmental variables. We consider this problem within the context of Bayesian optimization (BO) under uncertain environments, where the design variables are controllable, whereas the environmental variables are assumed to be random and not controllable. The challenge of this problem is to robustly estimate the PF when the distribution of the environmental variables is unknown, that is, to estimate the PF when the environmental variables are generated from the worst possible distribution. We propose a method for solving the BO problem by appropriately incorporating the uncertainties of the environmental variables and their probability distribution. We demonstrate that the proposed method can find an arbitrarily accurate PF with high probability in a finite number of iterations. We also evaluate the performance of the proposed method through numerical experiments.
Valid P-Value for Deep Learning-Driven Salient Region
Jan 06, 2023



Various saliency map methods have been proposed to interpret and explain predictions of deep learning models. Saliency maps allow us to interpret which parts of the input signals have a strong influence on the prediction results. However, since a saliency map is obtained by complex computations in deep learning models, it is often difficult to know how reliable the saliency map itself is. In this study, we propose a method to quantify the reliability of a salient region in the form of p-values. Our idea is to consider a salient region as a selected hypothesis by the trained deep learning model and employ the selective inference framework. The proposed method can provably control the probability of false positive detections of salient regions. We demonstrate the validity of the proposed method through numerical examples in synthetic and real datasets. Furthermore, we develop a Keras-based framework for conducting the proposed selective inference for a wide class of CNNs without additional implementation cost.
Transformer-based Personalized Attention Mechanism (PersAM) for Medical Images with Clinical Records
Jun 07, 2022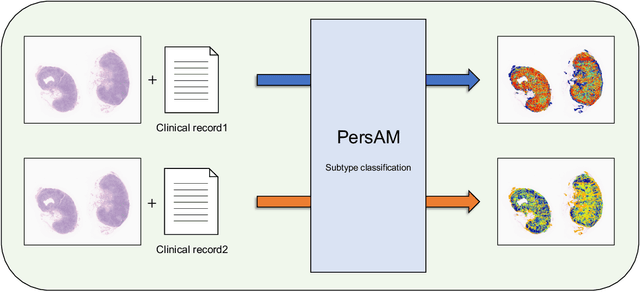
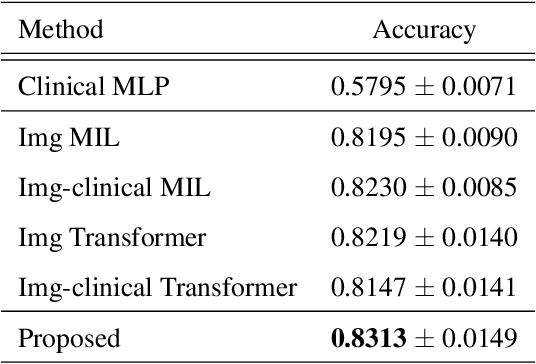
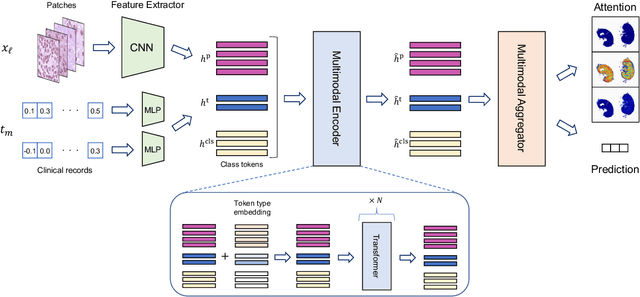
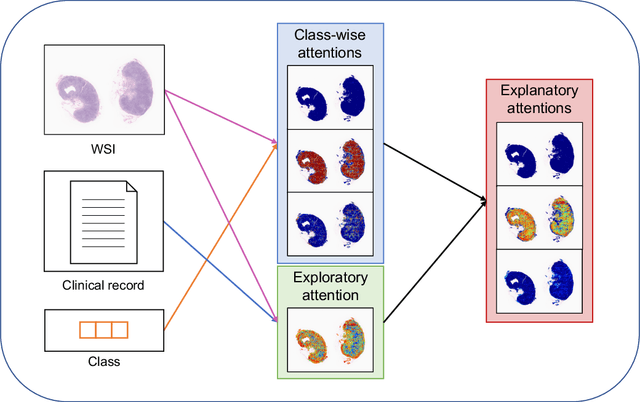
In medical image diagnosis, identifying the attention region, i.e., the region of interest for which the diagnosis is made, is an important task. Various methods have been developed to automatically identify target regions from given medical images. However, in actual medical practice, the diagnosis is made based not only on the images but also on a variety of clinical records. This means that pathologists examine medical images with some prior knowledge of the patients and that the attention regions may change depending on the clinical records. In this study, we propose a method called the Personalized Attention Mechanism (PersAM), by which the attention regions in medical images are adaptively changed according to the clinical records. The primary idea of the PersAM method is to encode the relationships between the medical images and clinical records using a variant of Transformer architecture. To demonstrate the effectiveness of the PersAM method, we applied it to a large-scale digital pathology problem of identifying the subtypes of 842 malignant lymphoma patients based on their gigapixel whole slide images and clinical records.
A Confidence Machine for Sparse High-Order Interaction Model
May 28, 2022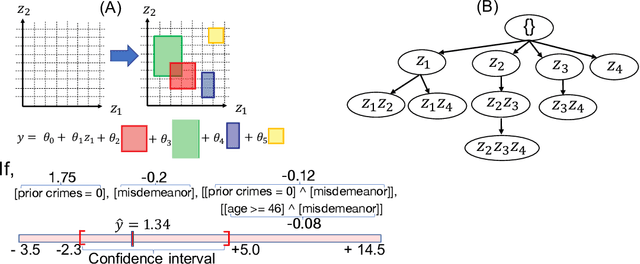
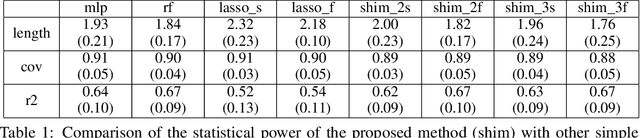
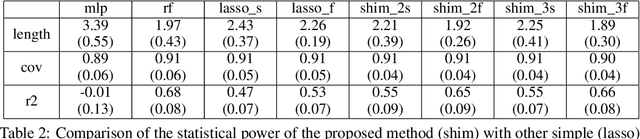
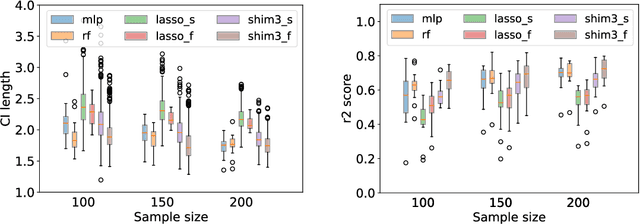
In predictive modeling for high-stake decision-making, predictors must be not only accurate but also reliable. Conformal prediction (CP) is a promising approach for obtaining the confidence of prediction results with fewer theoretical assumptions. To obtain the confidence set by so-called full-CP, we need to refit the predictor for all possible values of prediction results, which is only possible for simple predictors. For complex predictors such as random forests (RFs) or neural networks (NNs), split-CP is often employed where the data is split into two parts: one part for fitting and another to compute the confidence set. Unfortunately, because of the reduced sample size, split-CP is inferior to full-CP both in fitting as well as confidence set computation. In this paper, we develop a full-CP of sparse high-order interaction model (SHIM), which is sufficiently flexible as it can take into account high-order interactions among variables. We resolve the computational challenge for full-CP of SHIM by introducing a novel approach called homotopy mining. Through numerical experiments, we demonstrate that SHIM is as accurate as complex predictors such as RF and NN and enjoys the superior statistical power of full-CP.