 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Exhibit Normative Conformity
Apr 21, 2026The conformity bias exhibited by large language models (LLMs) can pose a significant challenge to decision-making in LLM-based multi-agent systems (LLM-MAS). While many prior studies have treated "conformity" simply as a matter of opinion change, this study introduces the social psychological distinction between informational conformity and normative conformity in order to understand LLM conformity at the mechanism level. Specifically, we design new tasks to distinguish between informational conformity, in which participants in a discussion are motivated to make accurate judgments, and normative conformity, in which participants are motivated to avoid conflict or gain acceptance within a group. We then conduct experiments based on these task settings. The experimental results show that, among the six LLMs evaluated, up to five exhibited tendencies toward not only informational conformity but also normative conformity. Furthermore, intriguingly, we demonstrate that by manipulating subtle aspects of the social context, it may be possible to control the target toward which a particular LLM directs its normative conformity. These findings suggest that decision-making in LLM-MAS may be vulnerable to manipulation by a small number of malicious users. In addition, through analysis of internal vectors associated with informational and normative conformity, we suggest that although both behaviors appear externally as the same form of "conformity," they may in fact be driven by distinct internal mechanisms. Taken together, these results may serve as an initial milestone toward understanding how "norms" are implemented in LLMs and how they influence group dynamics.
Position: No Retroactive Cure for Infringement during Training
Apr 20, 2026As generative AI faces intensifying legal challenges, the machine learning community has increasingly relied on post-hoc mitigation -- especially machine unlearning and inference-time guardrails -- to argue for compliance. This paper argues that such post-hoc mitigation methods cannot retroactively cure liability from unlawful acquisition and training, because compliance hinges on data lineage, not the outputs. Our argument has three parts. First, unauthorized copying/ingestion can be a legally complete completed act, and model weights may operate as fixed copies that retain training-derived expressive value, making later filtering beside the point for infringement. Second, contract and tort/unfair-competition rules -- via licenses, terms of service, and anti-free-riding principles -- can independently restrict access and use, often bypassing copyright defenses (e.g., fair use or TDM exceptions). Third, since value from protected inputs can persist in weights, remedies such as unjust enrichment and disgorgement may require stripping gains and, in some cases, reaching the model itself. We therefore argue for a shift from Post-Hoc Sanitization to verifiable Ex-Ante Process Compliance.
Cooperation Breakdown in LLM Agents Under Communication Delays
Feb 12, 2026LLM-based multi-agent systems (LLM-MAS), in which autonomous AI agents cooperate to solve tasks, are gaining increasing attention. For such systems to be deployed in society, agents must be able to establish cooperation and coordination under real-world computational and communication constraints. We propose the FLCOA framework (Five Layers for Cooperation/Coordination among Autonomous Agents) to conceptualize how cooperation and coordination emerge in groups of autonomous agents, and highlight that the influence of lower-layer factors - especially computational and communication resources - has been largely overlooked. To examine the effect of communication delay, we introduce a Continuous Prisoner's Dilemma with Communication Delay and conduct simulations with LLM-based agents. As delay increases, agents begin to exploit slower responses even without explicit instructions. Interestingly, excessive delay reduces cycles of exploitation, yielding a U-shaped relationship between delay magnitude and mutual cooperation. These results suggest that fostering cooperation requires attention not only to high-level institutional design but also to lower-layer factors such as communication delay and resource allocation, pointing to new directions for MAS research.
UniDetox: Universal Detoxification of Large Language Models via Dataset Distillation
Apr 29, 2025We present UniDetox, a universally applicable method designed to mitigate toxicity across various large language models (LLMs). Previous detoxification methods are typically model-specific, addressing only individual models or model families, and require careful hyperparameter tuning due to the trade-off between detoxification efficacy and language modeling performance. In contrast, UniDetox provides a detoxification technique that can be universally applied to a wide range of LLMs without the need for separate model-specific tuning. Specifically, we propose a novel and efficient dataset distillation technique for detoxification using contrastive decoding. This approach distills detoxifying representations in the form of synthetic text data, enabling universal detoxification of any LLM through fine-tuning with the distilled text. Our experiments demonstrate that the detoxifying text distilled from GPT-2 can effectively detoxify larger models, including OPT, Falcon, and LLaMA-2. Furthermore, UniDetox eliminates the need for separate hyperparameter tuning for each model, as a single hyperparameter configuration can be seamlessly applied across different models. Additionally, analysis of the detoxifying text reveals a reduction in politically biased content, providing insights into the attributes necessary for effective detoxification of LLMs.
Towards Transfer Unlearning: Empirical Evidence of Cross-Domain Bias Mitigation
Jul 24, 2024


Large language models (LLMs) often inherit biases from vast amounts of training corpora. Traditional debiasing methods, while effective to some extent, do not completely eliminate memorized biases and toxicity in LLMs. In this paper, we study an unlearning-based approach to debiasing in LLMs by performing gradient ascent on hate speech against minority groups, i.e., minimizing the likelihood of biased or toxic content. Specifically, we propose a mask language modeling unlearning technique, which unlearns the harmful part of the text. This method enables LLMs to selectively forget and disassociate from biased and harmful content. Experimental results demonstrate the effectiveness of our approach in diminishing bias while maintaining the language modeling abilities. Surprisingly, the results also unveil an unexpected potential for cross-domain transfer unlearning: debiasing in one bias form (e.g. gender) may contribute to mitigating others (e.g. race and religion).
Differentiable Instruction Optimization for Cross-Task Generalization
Jun 16, 2023Instruction tuning has been attracting much attention to achieve generalization ability across a wide variety of tasks. Although various types of instructions have been manually created for instruction tuning, it is still unclear what kind of instruction is optimal to obtain cross-task generalization ability. This work presents instruction optimization, which optimizes training instructions with respect to generalization ability. Rather than manually tuning instructions, we introduce learnable instructions and optimize them with gradient descent by leveraging bilevel optimization. Experimental results show that the learned instruction enhances the diversity of instructions and improves the generalization ability compared to using only manually created instructions.
SciReviewGen: A Large-scale Dataset for Automatic Literature Review Generation
May 24, 2023Automatic literature review generation is one of the most challenging tasks in natural language processing. Although large language models have tackled literature review generation, the absence of large-scale datasets has been a stumbling block to the progress. We release SciReviewGen, consisting of over 10,000 literature reviews and 690,000 papers cited in the reviews. Based on the dataset, we evaluate recent transformer-based summarization models on the literature review generation task, including Fusion-in-Decoder extended for literature review generation. Human evaluation results show that some machine-generated summaries are comparable to human-written reviews, while revealing the challenges of automatic literature review generation such as hallucinations and a lack of detailed information. Our dataset and code are available at https://github.com/tetsu9923/SciReviewGen.
Unsupervised Abstractive Opinion Summarization by Generating Sentences with Tree-Structured Topic Guidance
Jun 15, 2021

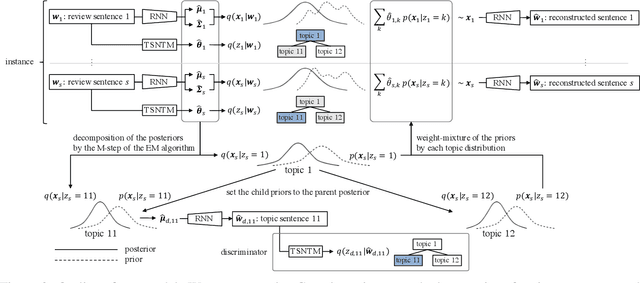
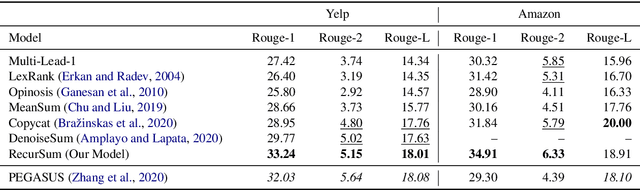
This paper presents a novel unsupervised abstractive summarization method for opinionated texts. While the basic variational autoencoder-based models assume a unimodal Gaussian prior for the latent code of sentences, we alternate it with a recursive Gaussian mixture, where each mixture component corresponds to the latent code of a topic sentence and is mixed by a tree-structured topic distribution. By decoding each Gaussian component, we generate sentences with tree-structured topic guidance, where the root sentence conveys generic content, and the leaf sentences describe specific topics. Experimental results demonstrate that the generated topic sentences are appropriate as a summary of opinionated texts, which are more informative and cover more input contents than those generated by the recent unsupervised summarization model (Bra\v{z}inskas et al., 2020). Furthermore, we demonstrate that the variance of latent Gaussians represents the granularity of sentences, analogous to Gaussian word embedding (Vilnis and McCallum, 2015).
Unsupervised Neural Single-Document Summarization of Reviews via Learning Latent Discourse Structure and its Ranking
Jun 13, 2019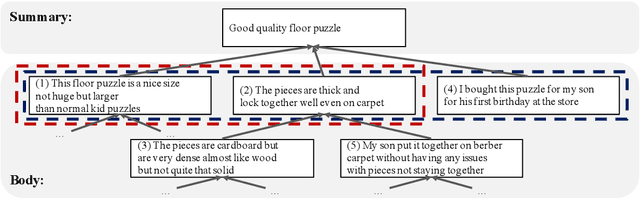
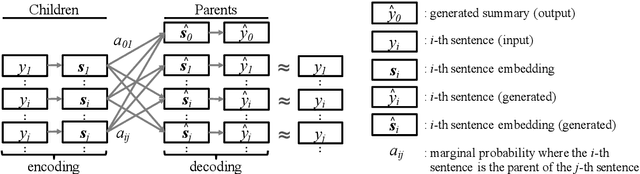
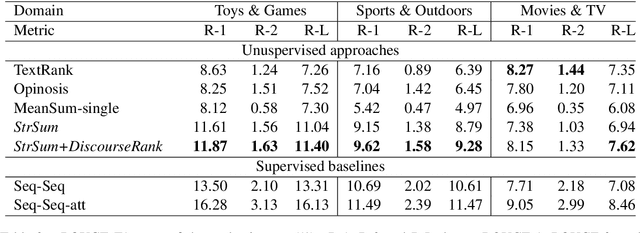
This paper focuses on the end-to-end abstractive summarization of a single product review without supervision. We assume that a review can be described as a discourse tree, in which the summary is the root, and the child sentences explain their parent in detail. By recursively estimating a parent from its children, our model learns the latent discourse tree without an external parser and generates a concise summary. We also introduce an architecture that ranks the importance of each sentence on the tree to support summary generation focusing on the main review point. The experimental results demonstrate that our model is competitive with or outperforms other unsupervised approaches. In particular, for relatively long reviews, it achieves a competitive or better performance than supervised models. The induced tree shows that the child sentences provide additional information about their parent, and the generated summary abstracts the entire review.