 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Graph Convolutional Networks to Address fMRI Small Data Problems
Feb 19, 2025



Although great advances in the analysis of neuroimaging data have been made, a major challenge is a lack of training data. This is less problematic in tasks such as diagnosis, where much data exists, but particularly prevalent in harder problems such as predicting treatment responses (prognosis), where data is focused and hence limited. Here, we address the learning from small data problems for medical imaging using graph neural networks. This is particularly challenging as the information about the patients is themselves graphs (regions of interest connectivity graphs). We show how a spectral representation of the connectivity data allows for efficient propagation that can yield approximately 12\% improvement over traditional deep learning methods using the exact same data. We show that our method's superior performance is due to a data smoothing result that can be measured by closing the number of triangle inequalities and thereby satisfying transitivity.
Foundations for Unfairness in Anomaly Detection -- Case Studies in Facial Imaging Data
Jul 29, 2024Deep anomaly detection (AD) is perhaps the most controversial of data analytic tasks as it identifies entities that are then specifically targeted for further investigation or exclusion. Also controversial is the application of AI to facial imaging data. This work explores the intersection of these two areas to understand two core questions: "Who" these algorithms are being unfair to and equally important "Why". Recent work has shown that deep AD can be unfair to different groups despite being unsupervised with a recent study showing that for portraits of people: men of color are far more likely to be chosen to be outliers. We study the two main categories of AD algorithms: autoencoder-based and single-class-based which effectively try to compress all the instances with those that can not be easily compressed being deemed to be outliers. We experimentally verify sources of unfairness such as the under-representation of a group (e.g. people of color are relatively rare), spurious group features (e.g. men are often photographed with hats), and group labeling noise (e.g. race is subjective). We conjecture that lack of compressibility is the main foundation and the others cause it but experimental results show otherwise and we present a natural hierarchy amongst them.
ChaosMining: A Benchmark to Evaluate Post-Hoc Local Attribution Methods in Low SNR Environments
Jun 17, 2024



In this study, we examine the efficacy of post-hoc local attribution methods in identifying features with predictive power from irrelevant ones in domains characterized by a low signal-to-noise ratio (SNR), a common scenario in real-world machine learning applications. We developed synthetic datasets encompassing symbolic functional, image, and audio data, incorporating a benchmark on the {\it (Model \(\times\) Attribution\(\times\) Noise Condition)} triplet. By rigorously testing various classic models trained from scratch, we gained valuable insights into the performance of these attribution methods in multiple conditions. Based on these findings, we introduce a novel extension to the notable recursive feature elimination (RFE) algorithm, enhancing its applicability for neural networks. Our experiments highlight its strengths in prediction and feature selection, alongside limitations in scalability. Further details and additional minor findings are included in the appendix, with extensive discussions. The codes and resources are available at \href{https://github.com/geshijoker/ChaosMining/}{URL}.
Identification and Uses of Deep Learning Backbones via Pattern Mining
Mar 27, 2024Deep learning is extensively used in many areas of data mining as a black-box method with impressive results. However, understanding the core mechanism of how deep learning makes predictions is a relatively understudied problem. Here we explore the notion of identifying a backbone of deep learning for a given group of instances. A group here can be instances of the same class or even misclassified instances of the same class. We view each instance for a given group as activating a subset of neurons and attempt to find a subgraph of neurons associated with a given concept/group. We formulate this problem as a set cover style problem and show it is intractable and presents a highly constrained integer linear programming (ILP) formulation. As an alternative, we explore a coverage-based heuristic approach related to pattern mining, and show it converges to a Pareto equilibrium point of the ILP formulation. Experimentally we explore these backbones to identify mistakes and improve performance, explanation, and visualization. We demonstrate application-based results using several challenging data sets, including Bird Audio Detection (BAD) Challenge and Labeled Faces in the Wild (LFW), as well as the classic MNIST data.
Cooperative Knowledge Distillation: A Learner Agnostic Approach
Feb 02, 2024Knowledge distillation is a simple but powerful way to transfer knowledge between a teacher model to a student model. Existing work suffers from at least one of the following key limitations in terms of direction and scope of transfer which restrict its use: all knowledge is transferred from teacher to student regardless of whether or not that knowledge is useful, the student is the only one learning in this exchange, and typically distillation transfers knowledge only from a single teacher to a single student. We formulate a novel form of knowledge distillation in which many models can act as both students and teachers which we call cooperative distillation. The models cooperate as follows: a model (the student) identifies specific deficiencies in it's performance and searches for another model (the teacher) who encodes learned knowledge into instructional virtual instances via counterfactual instance generation. Because different models may have different strengths and weaknesses, all models can act as either students or teachers (cooperation) when appropriate and only distill knowledge in areas specific to their strengths (focus). Since counterfactuals as a paradigm are not tied to any specific algorithm, we can use this method to distill knowledge between learners of different architectures, algorithms, and even feature spaces. We demonstrate that our approach not only outperforms baselines such as transfer learning, self-supervised learning, and multiple knowledge distillation algorithms on several datasets, but it can also be used in settings where the aforementioned techniques cannot.
Scalable Spectral Clustering with Group Fairness Constraints
Oct 28, 2022



There are synergies of research interests and industrial efforts in modeling fairness and correcting algorithmic bias in machine learning. In this paper, we present a scalable algorithm for spectral clustering (SC) with group fairness constraints. Group fairness is also known as statistical parity where in each cluster, each protected group is represented with the same proportion as in the entirety. While FairSC algorithm (Kleindessner et al., 2019) is able to find the fairer clustering, it is compromised by high costs due to the kernels of computing nullspaces and the square roots of dense matrices explicitly. We present a new formulation of underlying spectral computation by incorporating nullspace projection and Hotelling's deflation such that the resulting algorithm, called s-FairSC, only involves the sparse matrix-vector products and is able to fully exploit the sparsity of the fair SC model. The experimental results on the modified stochastic block model demonstrate that s-FairSC is comparable with FairSC in recovering fair clustering. Meanwhile, it is sped up by a factor of 12 for moderate model sizes. s-FairSC is further demonstrated to be scalable in the sense that the computational costs of s-FairSC only increase marginally compared to the SC without fairness constraints.
Towards Auditing Unsupervised Learning Algorithms and Human Processes For Fairness
Sep 20, 2022



Existing work on fairness typically focuses on making known machine learning algorithms fairer. Fair variants of classification, clustering, outlier detection and other styles of algorithms exist. However, an understudied area is the topic of auditing an algorithm's output to determine fairness. Existing work has explored the two group classification problem for binary protected status variables using standard definitions of statistical parity. Here we build upon the area of auditing by exploring the multi-group setting under more complex definitions of fairness.
Explainable Clustering via Exemplars: Complexity and Efficient Approximation Algorithms
Sep 20, 2022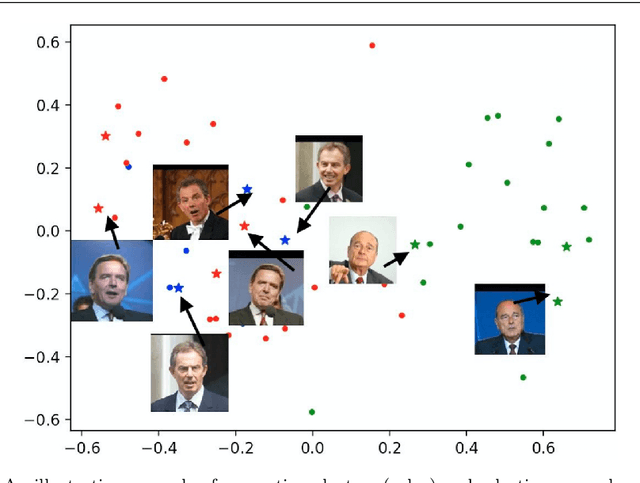

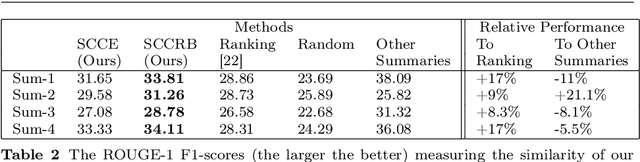
Explainable AI (XAI) is an important developing area but remains relatively understudied for clustering. We propose an explainable-by-design clustering approach that not only finds clusters but also exemplars to explain each cluster. The use of exemplars for understanding is supported by the exemplar-based school of concept definition in psychology. We show that finding a small set of exemplars to explain even a single cluster is computationally intractable; hence, the overall problem is challenging. We develop an approximation algorithm that provides provable performance guarantees with respect to clustering quality as well as the number of exemplars used. This basic algorithm explains all the instances in every cluster whilst another approximation algorithm uses a bounded number of exemplars to allow simpler explanations and provably covers a large fraction of all the instances. Experimental results show that our work is useful in domains involving difficult to understand deep embeddings of images and text.
Deep Fair Discriminative Clustering
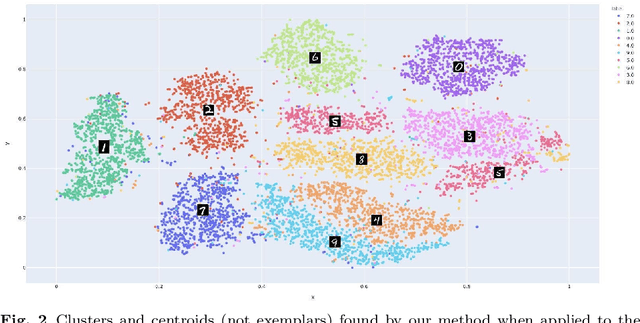
May 28, 2021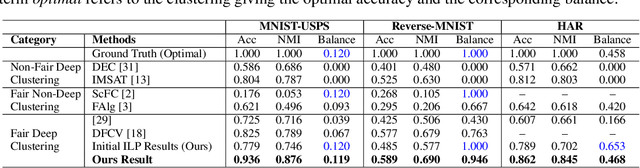

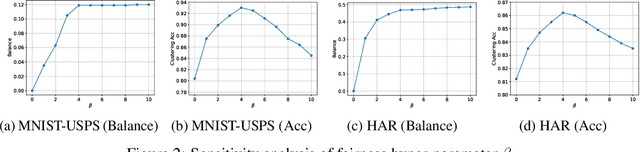
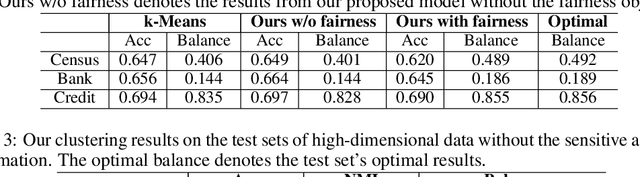
Deep clustering has the potential to learn a strong representation and hence better clustering performance compared to traditional clustering methods such as $k$-means and spectral clustering. However, this strong representation learning ability may make the clustering unfair by discovering surrogates for protected information which we empirically show in our experiments. In this work, we study a general notion of group-level fairness for both binary and multi-state protected status variables (PSVs). We begin by formulating the group-level fairness problem as an integer linear programming formulation whose totally unimodular constraint matrix means it can be efficiently solved via linear programming. We then show how to inject this solver into a discriminative deep clustering backbone and hence propose a refinement learning algorithm to combine the clustering goal with the fairness objective to learn fair clusters adaptively. Experimental results on real-world datasets demonstrate that our model consistently outperforms state-of-the-art fair clustering algorithms. Our framework shows promising results for novel clustering tasks including flexible fairness constraints, multi-state PSVs and predictive clustering.
Deep Descriptive Clustering
May 24, 2021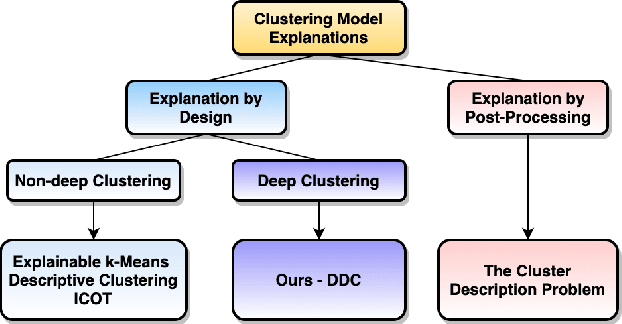

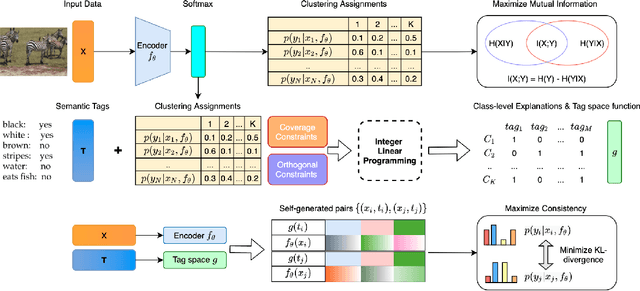

Recent work on explainable clustering allows describing clusters when the features are interpretable. However, much modern machine learning focuses on complex data such as images, text, and graphs where deep learning is used but the raw features of data are not interpretable. This paper explores a novel setting for performing clustering on complex data while simultaneously generating explanations using interpretable tags. We propose deep descriptive clustering that performs sub-symbolic representation learning on complex data while generating explanations based on symbolic data. We form good clusters by maximizing the mutual information between empirical distribution on the inputs and the induced clustering labels for clustering objectives. We generate explanations by solving an integer linear programming that generates concise and orthogonal descriptions for each cluster. Finally, we allow the explanation to inform better clustering by proposing a novel pairwise loss with self-generated constraints to maximize the clustering and explanation module's consistency. Experimental results on public data demonstrate that our model outperforms competitive baselines in clustering performance while offering high-quality cluster-level explanations.