 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards High-Level Modelling in Automated Planning
Dec 09, 2024Planning is a fundamental activity, arising frequently in many contexts, from daily tasks to industrial processes. The planning task consists of selecting a sequence of actions to achieve a specified goal from specified initial conditions. The Planning Domain Definition Language (PDDL) is the leading language used in the field of automated planning to model planning problems. Previous work has highlighted the limitations of PDDL, particularly in terms of its expressivity. Our interest lies in facilitating the handling of complex problems and enhancing the overall capability of automated planning systems. Unified-Planning is a Python library offering high-level API to specify planning problems and to invoke automated planners. In this paper, we present an extension of the UP library aimed at enhancing its expressivity for high-level problem modelling. In particular, we have added an array type, an expression to count booleans, and the allowance for integer parameters in actions. We show how these facilities enable natural high-level models of three classical planning problems.
Automating Reformulation of Essence Specifications via Graph Rewriting
Nov 14, 2024Formulating an effective constraint model of a parameterised problem class is crucial to the efficiency with which instances of the class can subsequently be solved. It is difficult to know beforehand which of a set of candidate models will perform best in practice. This paper presents a system that employs graph rewriting to reformulate an input model for improved performance automatically. By situating our work in the Essence abstract constraint specification language, we can use the structure in its high level variable types to trigger rewrites directly. We implement our system via rewrite rules expressed in the Graph Programs 2 language, applied to the abstract syntax tree of an input specification. We show how to automatically translate the solution of the reformulated problem into a solution of the original problem for verification and presentation. We demonstrate the efficacy of our system with a detailed case study.
Athanor: Local Search over Abstract Constraint Specifications
Oct 08, 2024



Local search is a common method for solving combinatorial optimisation problems. We focus on general-purpose local search solvers that accept as input a constraint model - a declarative description of a problem consisting of a set of decision variables under a set of constraints. Existing approaches typically take as input models written in solver-independent constraint modelling languages like MiniZinc. The Athanor solver we describe herein differs in that it begins from a specification of a problem in the abstract constraint specification language Essence, which allows problems to be described without commitment to low-level modelling decisions through its support for a rich set of abstract types. The advantage of proceeding from Essence is that the structure apparent in a concise, abstract specification of a problem can be exploited to generate high quality neighbourhoods automatically, avoiding the difficult task of identifying that structure in an equivalent constraint model. Based on the twin benefits of neighbourhoods derived from high level types and the scalability derived by searching directly over those types, our empirical results demonstrate strong performance in practice relative to existing solution methods.
Frugal Algorithm Selection
May 17, 2024



When solving decision and optimisation problems, many competing algorithms (model and solver choices) have complementary strengths. Typically, there is no single algorithm that works well for all instances of a problem. Automated algorithm selection has been shown to work very well for choosing a suitable algorithm for a given instance. However, the cost of training can be prohibitively large due to running candidate algorithms on a representative set of training instances. In this work, we explore reducing this cost by choosing a subset of the training instances on which to train. We approach this problem in three ways: using active learning to decide based on prediction uncertainty, augmenting the algorithm predictors with a timeout predictor, and collecting training data using a progressively increasing timeout. We evaluate combinations of these approaches on six datasets from ASLib and present the reduction in labelling cost achieved by each option.
Towards Exploratory Reformulation of Constraint Models
Nov 20, 2023



It is well established that formulating an effective constraint model of a problem of interest is crucial to the efficiency with which it can subsequently be solved. Following from the observation that it is difficult, if not impossible, to know a priori which of a set of candidate models will perform best in practice, we envisage a system that explores the space of models through a process of reformulation from an initial model, guided by performance on a set of training instances from the problem class under consideration. We plan to situate this system in a refinement-based approach, where a user writes a constraint specification describing a problem above the level of abstraction at which many modelling decisions are made. In this position paper we set out our plan for an exploratory reformulation system, and discuss progress made so far.
Towards a Model of Puzznic
Oct 02, 2023We report on progress in modelling and solving Puzznic, a video game requiring the player to plan sequences of moves to clear a grid by matching blocks. We focus here on levels with no moving blocks. We compare a planning approach and three constraint programming approaches on a small set of benchmark instances. The planning approach is at present superior to the constraint programming approaches, but we outline proposals for improving the constraint models.
Challenges in Modelling and Solving Plotting with PDDL
Oct 02, 2023


We study a planning problem based on Plotting, a tile-matching puzzle video game published by Taito in 1989. The objective of this game is to remove a target number of coloured blocks from a grid by sequentially shooting blocks into the grid. Plotting features complex transitions after every shot: various blocks are affected directly, while others can be indirectly affected by gravity. We highlight the challenges of modelling Plotting with PDDL and of solving it with a grounding-based state-of-the-art planner.
A Framework for Generating Informative Benchmark Instances
May 29, 2022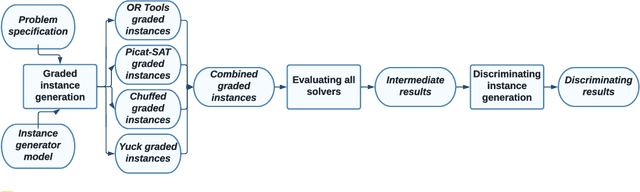
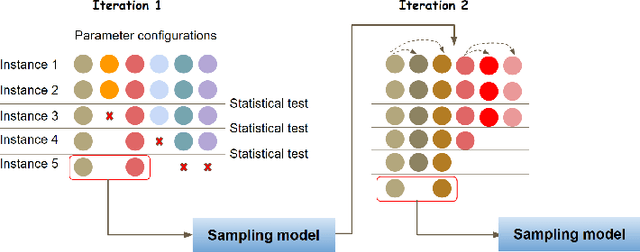
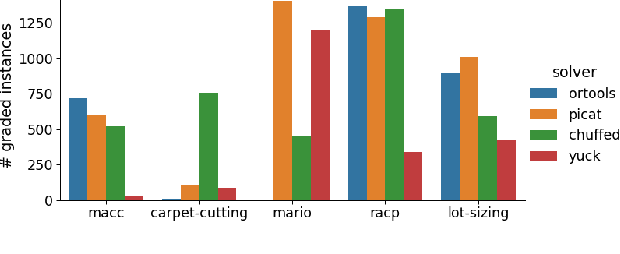
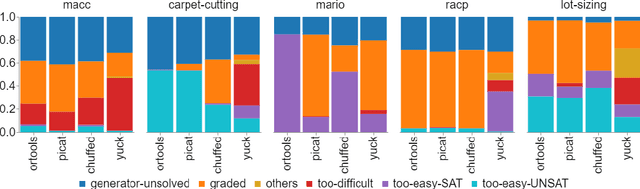
Benchmarking is an important tool for assessing the relative performance of alternative solving approaches. However, the utility of benchmarking is limited by the quantity and quality of the available problem instances. Modern constraint programming languages typically allow the specification of a class-level model that is parameterised over instance data. This separation presents an opportunity for automated approaches to generate instance data that define instances that are graded (solvable at a certain difficulty level for a solver) or can discriminate between two solving approaches. In this paper, we introduce a framework that combines these two properties to generate a large number of benchmark instances, purposely generated for effective and informative benchmarking. We use five problems that were used in the MiniZinc competition to demonstrate the usage of our framework. In addition to producing a ranking among solvers, our framework gives a broader understanding of the behaviour of each solver for the whole instance space; for example by finding subsets of instances where the solver performance significantly varies from its average performance.
Automatic Tabulation in Constraint Models
Feb 26, 2022


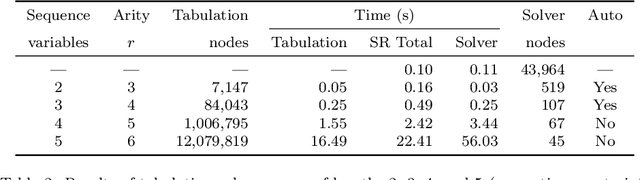
The performance of a constraint model can often be improved by converting a subproblem into a single table constraint. In this paper we study heuristics for identifying promising candidate subproblems, where converting the candidate into a table constraint is likely to improve solver performance. We propose a small set of heuristics to identify common cases, such as expressions that will propagate weakly. The process of discovering promising subproblems and tabulating them is entirely automated in the constraint modelling tool Savile Row. Caches are implemented to avoid tabulating equivalent subproblems many times. We give a simple algorithm to generate table constraints directly from a constraint expression in \savilerow. We demonstrate good performance on the benchmark problems used in earlier work on tabulation, and also for several new problem classes. In some cases, the entirely automated process leads to orders of magnitude improvements in solver performance.
Towards Reformulating Essence Specifications for Robustness
Nov 01, 2021



The Essence language allows a user to specify a constraint problem at a level of abstraction above that at which constraint modelling decisions are made. Essence specifications are refined into constraint models using the Conjure automated modelling tool, which employs a suite of refinement rules. However, Essence is a rich language in which there are many equivalent ways to specify a given problem. A user may therefore omit the use of domain attributes or abstract types, resulting in fewer refinement rules being applicable and therefore a reduced set of output models from which to select. This paper addresses the problem of recovering this information automatically to increase the robustness of the quality of the output constraint models in the face of variation in the input Essence specification. We present reformulation rules that can change the type of a decision variable or add attributes that shrink its domain. We demonstrate the efficacy of this approach in terms of the quantity and quality of models Conjure can produce from the transformed specification compared with the original.